玩转SpringBoot中的那些连接池(小结)
回想起前几天在部署springboot项目到正线时,线上环境要求jdk7,可项目是基于jdk8开发的,springboot也是用的springboot2以上的版本,可以说缝缝补补一整天才搞好能满足线上环境的代码,搞完后当然需要小小的了解一下背后的秘密。
好了,话不多说,我们直接进入正题。
其实切换还不算太麻烦,坑就坑在SpringBoot2切换到SpringBoot1后,默认使用的连接池发生了变化,之前做的压力测试又重新搞了一遍。

怨天尤人貌似消极了哈,小编我可是一个正能量满满的人,所以总结下自己就是:虽然会用,但是没了解技术背后的真相而闹出的乌龙。
接下里我们就一起来检验下SpringBoot2和SpringBoot1使用的默认数据源吧!
一、SpringBoot2的HikariCP
首先在pom文件中需要引入的依赖包:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<mybatis.spring.boot.version>1.3.1</mybatis.spring.boot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.spring.boot.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
其次在配置文件中需要定义如下属性(不定义时会自动使用默认值)
# spring的相关配置 spring: application: name: HikariCP测试 # 数据源的配置 datasource: # 连接池的配置 type: com.zaxxer.hikari.HikariDataSource hikari: minimum-idle: 5 maximum-pool-size: 15 connection-test-query: SELECT 1 max-lifetime: 1800000 connection-timeout: 30000 pool-name: DatebookHikariCP
配置好后,启动成功时你能看到类似这样子的打印信息:
2020-01-16 16:23:12.911 INFO 9996 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2020-01-16 16:23:12.913 INFO 9996 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'dataSource' has been autodetected for JMX exposure
2020-01-16 16:23:12.924 INFO 9996 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Located MBean 'dataSource': registering with JMX server as MBean [com.zaxxer.hikari:name=dataSource,type=HikariDataSource]
2020-01-16 16:23:12.994 INFO 9996 --- [ main ] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 18001 (http) with context path ''
2020-01-16 16:23:13.002 INFO 9996 --- [ main ] c.j.mmzsblog.DatasourceTestApplication : Started DatasourceTestApplication in 6.724 seconds (JVM running for 8.883)
其中第3行[com.zaxxer.hikari:name=dataSource,type=HikariDataSource]这部分就点明了使用的连接池类型
二、SpringBoot1的tomcat-jdbc
降低版本后,我没有看到上面的信息打印,一时差点不知道使用了什么连接池,不过网上都说是tomcat-jdbc;但是相信眼见为实的我,肯定要在哪里打印一下才放心,于是乎,我进行了如下操作:
搞了一个controller来简单的打印一下连接池的信息
@RestController
public class testController {
@Resource
private DataSource dataSource;
@GetMapping("/query")
public void query(){
System.out.println("查询到的数据源连接池信息是:"+dataSource);
System.out.println("查询到的数据源连接池类型是:"+dataSource.getClass());
System.out.println("查询到的数据源连接池名字是:"+dataSource.getPoolProperties().getName());
}
}
然后我就看到了如下的打印信息,果真是用的tomcat-jdbc
查询到的数据源连接池信息是:org.apache.tomcat.jdbc.pool.DataSource@181d8899{ConnectionPool[defaultAutoCommit=null; defaultReadOnly=null; defaultTransactionIsolation=-1; defaultCatalog=null; driverClassName=com.mysql.jdbc.Driver; maxActive=100; maxIdle=100; minIdle=10; initialSize=10; maxWait=30000; testOnBorrow=true; testOnReturn=false; timeBetweenEvictionRunsMillis=5000; numTestsPerEvictionRun=0; minEvictableIdleTimeMillis=60000; testWhileIdle=false; testOnConnect=false; password=********; url=jdbc:mysql://localhost:3306/xxxxxx; username=xxxx; validationQuery=SELECT 1; validationQueryTimeout=-1; validatorClassName=null; validationInterval=3000; accessToUnderlyingConnectionAllowed=true; removeAbandoned=false; removeAbandonedTimeout=60; logAbandoned=false; connectionProperties=null; initSQL=null; jdbcInterceptors=null; jmxEnabled=true; fairQueue=true; useEquals=true; abandonWhenPercentageFull=0; maxAge=0; useLock=false; dataSource=null; dataSourceJNDI=null; suspectTimeout=0; alternateUsernameAllowed=false; commitOnReturn=false; rollbackOnReturn=false; useDisposableConnectionFacade=true; logValidationErrors=false; propagateInterruptState=false; ignoreExceptionOnPreLoad=false; useStatementFacade=true; }
查询到的数据源连接池类型是:class org.apache.tomcat.jdbc.pool.DataSource
查询到的数据源连接池名字是:Tomcat Connection Pool[1-1715657818]
其实,我们从pom文件也能看出其中的门道:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
依赖文件中的这一个依赖其实就是表明了SpringBoot1使用的是tomcat-jdbc连接池。
哎,现在才知道SpringBoot2.0和SpringBoot1.0版本使用的默认数据库是不一样的。
现在原因是找到了,可是如何解决呢?要不然把SpringBoot1版本的默认连接池修改成和SpringBoot2版本的一样。好,有了想法,那就开干。

其实,在SpringBoot1的版本也是可以使用HikariCP连接池的,操作就是:
首先引入默认配置的数据源处排除掉tomcat-jdbc
<!--配置默认数据源 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<exclusions>
<!-- 排除默认的tomcat-jdbc数据源 -->
<exclusion>
<groupId>org.apache</groupId>
<artifactId>tomcat-jdbc</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 引用SpringBoot2默认的HikariCP数据源 -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.3.1</version>
</dependency>
再在.yml文件中配置HikariCP数据源的相关信息
# spring的相关配置 spring: # 数据源的配置 datasource: # 连接池的配置 type: com.zaxxer.hikari.HikariDataSource hikari: minimum-idle: 5 maximum-pool-size: 15 connection-test-query: SELECT 1 max-lifetime: 1800000 connection-timeout: 30000
为什么说我此处要将数据源切换成SpringBoot2.0使用的默认数据源呢?因为使用SpringBoot1.0的tomcat-jdbc数据源我怕压力测试出来达不到要求,为了不给测试增加工作压力(小编我就是这么好的一个人)

所以我进行了上面的替换操作。
不过这样做肯定也是有好处的。好处就在于HikariCP那迷人的优势:
1、字节码级别优化(很多方法通过JavaAssist生成)
2、大量小改进
- 用FastStatementList代替ArrayList
- 无锁集合ConcurrentBag
- 代理类的优化(比如:,用invokestatic代替invokevirtual)
正如官网的这个对比图显示的一样:它更快
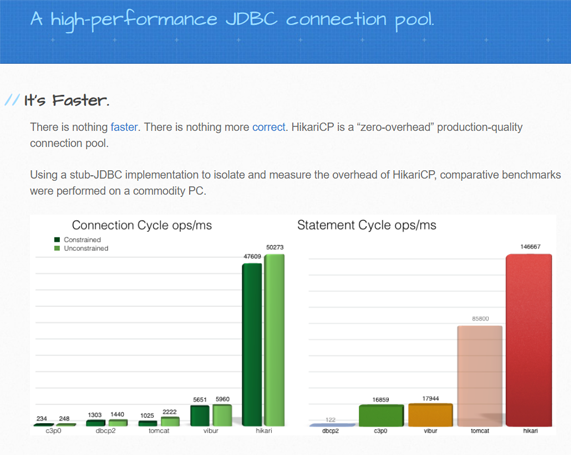
其实话又说回来,要是我一开始就是用第三方数据库,岂不是就不存在这些自己搞出来的幺蛾子了!

比如阿里巴巴的Druid连接池不就是个优秀的产品么!它到底有多优秀呢?你先看它的使用:
三、其它连接池(如:Druid)
3.1、SpringBoot1.0中引用Druid
和前文的SpringBoot1.0中引用HikariCP一样,先排除默认数据源tomcat-jdbc再引用想要使用的连接池
3.1.1、首先引入默认配置的数据源处排除掉tomcat-jdbc
<!--配置默认数据源 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<exclusions>
<!-- 排除默认的tomcat-jdbc数据源 -->
<exclusion>
<groupId>org.apache</groupId>
<artifactId>tomcat-jdbc</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 引用阿里巴巴的druid数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.31</version>
</dependency>
3.1.2、再在.yml文件中配置Druid数据源的相关信息
spring: # 数据源的配置 datasource: # 连接池的配置 type: com.alibaba.druid.pool.DruidDataSource druid: initial-size: 5 max-active: 10 min-idle: 5 max-wait: 30000 pool-prepared-statements: true max-pool-prepared-statement-per-connection-size: 20 validation-query: SELECT 1 FROM DUAL validation-query-timeout: 60000 test-on-borrow: false test-on-return: false test-while-idle: true time-between-eviction-runs-millis: 60000 min-evictable-idle-time-millis: 100000
3.1.3、再写个配置类加载数据源
@Configuration
@ConditionalOnClass(DruidDataSource.class)
@ConditionalOnProperty(name = "spring.datasource.type", havingValue = "com.alibaba.druid.pool.DruidDataSource", matchIfMissing = true)
public class DataSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid")
public DataSource dataSourceOne() {
return DruidDataSourceBuilder.create().build();
}
}
3.1.4、启动效果:
2020-01-17 16:59:32.804 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2020-01-17 16:59:32.806 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'dataSourceOne' has been autodetected for JMX exposure
2020-01-17 16:59:32.808 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'statFilter' has been autodetected for JMX exposure
2020-01-17 16:59:32.818 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Located MBean 'dataSourceOne': registering with JMX server as MBean [com.alibaba.druid.spring.boot.autoconfigure:name=dataSourceOne,type=DruidDataSourceWrapper]
2020-01-17 16:59:32.822 INFO 8520 --- [ main ] o.s.j.e.a.AnnotationMBeanExporter : Located MBean 'statFilter': registering with JMX server as MBean [com.alibaba.druid.filter.stat:name=statFilter,type=StatFilter]
2020-01-17 16:59:32.932 INFO 8520 --- [ main ] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 18001 (http)
2020-01-17 16:59:32.943 INFO 8520 --- [ main ] c.j.mmzsblog.DatasourceTestApplication : Started DatasourceTestApplication in 8.328 seconds (JVM running for 10.941)
3.2、SpringBoot2.0中引用Druid
在SpringBoot2.0中引用Druid和在SpringBoot1.0中引入类似;
3.2.1、不需要排除默认配置的数据源,直接引入置Druid数据源
<!-- 引用阿里巴巴的druid数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.31</version>
</dependency>
3.2.2、在.yml文件中配置的Druid数据源的相关信息同3.1.3一样
3.2.3、再写个配置类加载数据源同3.1.3一样
3.2.4、启动后你同样能看到打印出类似的信息
Located MBean 'dataSourceOne': registering with JMX server as MBean [com.alibaba.druid.spring.boot.autoconfigure:name=dataSourceOne,type=DruidDataSourceWrapper]
3.3、优秀在哪?
看了上面的使用,超级简单又木有?
首先我们看看druid官网给出的几个传统连接池之间的对比吧:

从上表可以看出,Druid连接池在性能、监控、诊断、安全、扩展性这些方面远远超出竞品。
官网是这样介绍它的:
Druid连接池是阿里巴巴开源的数据库连接池项目。Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。
所以,小编我倒腾了这么久,想明白了一件事,我以后还是用阿里爸爸的Druid连接池吧,接入简单,还自带监控,并且它可是经过阿里巴巴各大系统考验过的产品,值得信赖,省事省心啊。

参考:
1:HikariCP的优点:https://www.jianshu.com/p/129efe2c8e49
2、druid官网:https://github.com/alibaba/druid/
到此这篇关于玩转SpringBoot中的那些连接池(小结)的文章就介绍到这了,更多相关SpringBoot 连接池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

springboot配置druid连接池的方法示例
Druid的简介 Druid首先是一个数据库连接池.Druid是目前最好的数据库连接池,在功能.性能.扩展性方面,都超过其他数据库连接池,包括DBCP.C3P0.BoneCP.Proxool.JBoss DataSource.Druid已经在阿里巴巴部署了超过600个应用,经过一年多生产环境大规模部署的严苛考验.Druid是阿里巴巴开发的号称为监控而生的数据库连接池! Druid的功能 1.替换DBCP和C3P0.Druid提供了一个高效.功能强大.可扩展性好的数据库连接池. 2.可以监控数据库
-
SpringBoot使用 druid 连接池来优化分页语句
一.前言 一个老系统随着数据量越来越大,我们察觉到部分分页语句拖慢了我们的速度. 鉴于老系统的使用方式,不打算使用pagehelper和mybatis-plus来处理,加上系统里使用得是druid连接池,考虑直接使用druid来优化. 二.老代码 老代码是使用得一个mybatis插件进行的分页,分页的核心代码如下: // 记录统计的 sql String countSql = "select count(0) from (" + sql+ ") tmp_count"
-
SpringBoot整合Druid数据库连接池的方法
一,Druid是什么? Druid是Java语言中最好的数据库连接池.Druid能够提供强大的监控和扩展功能. 二, 在哪里下载druid maven中央仓库: http://central.maven.org/maven2/com/alibaba/druid/ 三, 怎么获取Druid的源码 Druid是一个开源项目,源码托管在github上,源代码仓库地址是 https://github.com/alibaba/druid.同时每次Druid发布正式版本和快照的时候,都会把源码打包,你可以从
-
springboot集成druid连接池配置的方法
在开发项目中如果数据库选型为mysql,很大概率下连接池会使用druid 这里介绍springboot集成durid springboot : 2.1.9 druid : 1.1.10 案例地址 github地址 springboot集成druid配置 需要引入的pom <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactI
-
基于SpringBoot2.0默认使用Redis连接池的配置操作
SpringBoot2.0默认采用Lettuce客户端来连接Redis服务端的 默认是不使用连接池的,只有配置 redis.lettuce.pool下的属性的时候才可以使用到redis连接池 redis: cluster: nodes: ${redis.host.cluster} password: ${redis.password} lettuce: shutdown-timeout: 100 # 关闭超时时间 pool: max-active: 8 # 连接池最大连接数(使用负值表示没有限制
-
详解SpringBoot配置连接池
内置的连接池 目前spring Boot中默认支持的连接池有dbcp,dbcp2, tomcat, hikari三种连接池. 数据库连接可以使用DataSource池进行自动配置. 由于Tomcat数据源连接池的性能和并发,在tomcat可用时,我们总是优先使用它. 如果HikariCP可用,我们将使用它. 如果Commons DBCP可用,我们将使用它,但在生产环境不推荐使用它. 最后,如果Commons DBCP2可用,我们将使用它. 以上的几种连接池,可以通过在配置application文
-
springboot整合druid连接池的步骤
使用springboot默认的连接池 导入springboot data-jdbc依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jdbc</artifactId> </dependency> 配置文件配置连接池 spring: datasource: username: root pass
-
玩转SpringBoot中的那些连接池(小结)
回想起前几天在部署springboot项目到正线时,线上环境要求jdk7,可项目是基于jdk8开发的,springboot也是用的springboot2以上的版本,可以说缝缝补补一整天才搞好能满足线上环境的代码,搞完后当然需要小小的了解一下背后的秘密. 好了,话不多说,我们直接进入正题. 其实切换还不算太麻烦,坑就坑在SpringBoot2切换到SpringBoot1后,默认使用的连接池发生了变化,之前做的压力测试又重新搞了一遍. 怨天尤人貌似消极了哈,小编我可是一个正能量满满的人,所以总结下自
-
Springboot中加入druid连接池
目录 1.DRUID连接池介绍 2.DRUID 的参数 3.配置依赖 4.添加文件 1.DRUID连接池介绍 Druid是阿里巴巴开发的号称为监控而生的数据库连接池,Druid是目前最好的数据库连接池.在功能.性能.扩展性方面,都超过其他数据库连接池,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况. 2.DRUID 的参数 jdbcUrl 连接数据库的url:mysql : jdbc:mysql://localhost:3306/testusername 数据库的用户名passw
-
如何在SpringBoot 中使用 Druid 数据库连接池
Druid是阿里开源的一款数据库连接池,除了常规的连接池功能外,它还提供了强大的监控和扩展功能.这对没有做数据库监控的小项目有很大的吸引力. 下列步骤可以让你无脑式的在SpringBoot2.x中使用Druid. 1.Maven中的pom文件 <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.14</ve
-
springboot中@Async默认线程池导致OOM问题
前言: 1.最近项目上在测试人员压测过程中发现了OOM问题,项目使用springboot搭建项目工程,通过查看日志中包含信息:unable to create new native thread 内存溢出的三种类型: 1.第一种OutOfMemoryError: PermGen space,发生这种问题的原意是程序中使用了大量的jar或class 2.第二种OutOfMemoryError: Java heap space,发生这种问题的原因是java虚拟机创建的对象太多 3.第三种OutOfM
-
spring boot中配置hikari连接池属性方式
目录 spring boot配置hikari连接池属性 spring-boot默认连接池 Hikari配置 Hikari连接池配置说明 spring boot配置hikari连接池属性 事件起因与一个简单应用经常发生Young GC,甚至在没有请求量的情况下也经常发生GC (Allocation Failure),后来使用mat工具进行分析,发现mysql连接相关的class居然占了40%+堆内空间. 才发现spring boot的连接池大小没有配置,默认是10个连接,但实际上该应用不需要这么多
-
.net 中的SqlConnection连接池机制详解
正确的理解这个连接池机制,有助于我们编写高效的数据库应用程序. 很多人认为 SqlConnection 的连接是不耗时的,理由是循环执行 SqlConnection.Open 得到的平均时间几乎为0,但每次首次open 时,耗时又往往达到几个毫秒到几秒不等,这又是为什么呢? 首先我们看一下 MSDN 上的权威文档上是怎么说的 Connecting to a database server typically consists of several time-consuming steps. A
-
SpringBoot中ApplicationEvent和ApplicationListener用法小结
目录 一.开发ApplicationEvent事件 二. 开发监听器 三.推送事件 四.注解方式实现监听器 对不起大家,昨天文章里的告别说早了,这个系列还不能就这么结束. 我们前面的文章中讲解过RabbitMQ的用法,所谓MQ就是一种发布订阅模式的消息模型.在Spring中其实本身也为我们提供了一种发布订阅模式的事件处理方式,就是ApplicationEvent和 ApplicationListener,这是一种基于观察者模式实现事件监听功能.也已帮助我们完成业务逻辑的解耦,提高程序的扩展性和可
-
springboot restTemplate连接池整合方式
目录 springboot restTemplate连接池整合 restTemplate 引入apache httpclient RestTemplate配置类 RestTemplate连接池配置参数 测试带连接池的RestTemplate RestTemplate 配置http连接池 springboot restTemplate连接池整合 restTemplate 使用http连接池能够减少连接建立与释放的时间,提升http请求的性能.如果客户端每次请求都要和服务端建立新的连接,即三次握手将
-
SpringBoot集成Druid连接池进行SQL监控的问题解析
Druid连接池是阿里巴巴开源的数据库连接池项目.Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能. Druid的监控统计功能是通过filter-chain扩展实现,采集的信息非常全面,包括SQL执行.并发.慢查.执行时间区间分布等.并且Druid内置提供了一个StatViewServlet用于展示Druid的统计信息,提高html页面展示非常完备的监控信息,可以快速诊断系统的瓶颈. 而Druid增加StatFilter之后,能采集大量统计信息,同时对性能基本没有影响.Stat
-
SpringBoot HikariCP连接池详解
目录 背景 公用池化包 Commons Pool 2 案例 JMH 测试 数据库连接池 HikariCP 结果缓存池 小结 背景 在我们平常的编码中,通常会将一些对象保存起来,这主要考虑的是对象的创建成本. 比如像线程资源.数据库连接资源或者 TCP 连接等,这类对象的初始化通常要花费比较长的时间,如果频繁地申请和销毁,就会耗费大量的系统资源,造成不必要的性能损失. 并且这些对象都有一个显著的特征,就是通过轻量级的重置工作,可以循环.重复地使用. 这个时候,我们就可以使用一个虚拟的池子,将这些资