python Pandas时序数据处理
目录
- Python中时间的一些常用操作
- Pandas时间序列(DatetimeIndex)与时序数据
- 杭州天气的时序处理
- 附:matplotlib中文支持
Python中时间的一些常用操作
import time
# 从格林威治时间到现在,单位秒
print('系统时间戳:', time.time())
print('本地时间按格式转成str:', time.strftime('%Y-%m-%d %X', time.localtime()))
# 无参的localtime返回time.struct_time格式的时间,是本地时区的时间
print('无参localtime:', time.localtime())
print('本时区时间转成时间戳:', time.mktime(time.localtime()))
# 将时间戳转换为能读懂的时间
print('时间戳转时间:', time.strftime('%Y-%m-%d %X', time.localtime(time.time())))
运行结果:
系统时间戳: 1542188096.1592166
本地时间按格式转成str: 2018-11-14 17:34:56
无参localtime: time.struct_time(tm_year=2018, tm_mon=11, tm_mday=14, tm_hour=17, tm_min=34, tm_sec=56, tm_wday=2, tm_yday=318, tm_isdst=0)
本时区时间转成时间戳: 1542188096.0
时间戳转时间: 2018-11-14 17:34:56
Pandas时间序列(DatetimeIndex)与时序数据
时间序列在Series对象中且作为索引存在时,就构成了时序数据。
import datetime
import numpy as np
import pandas as pd
# pd.date_range()函数用于创建一个Pandas时间序列DatetimeIndex
# start参数(也是第一个参数)传入一个str格式的开始时间,也可以传入一个datetime对象
# 这里用datetime.datetime()创建了一个datetime对象,只用了前三个参数也就是年月日
# pd.date_range()函数可以指明end表示时间序列的结尾时间
# 这里用periods参数指明序列中要生成的时间的个数,freq='D'指定为每天(Day)生成一个时间
dti = pd.date_range(start=datetime.datetime(2018, 11, 14), periods=18, freq='D')
print(dti, '\n', '*' * 40, sep='')
# 将时间序列放在Series对象中作为索引,这里freq='W'表示隔一周生成一个
s_dti = pd.Series(np.arange(6), index=pd.date_range('2018/11/4', periods=6, freq='W'))
print(s_dti.head(), '\n', '*' * 40, sep='')
# 取时序数据中指定时间的内容
print(s_dti['2018-11-25'], '\n', '*' * 40, sep='')
# 取第二个索引对应的时间的年月日
print(s_dti.index[2].year, s_dti.index[2].month, s_dti.index[2].day, '\n', '*' * 40, sep='')
运行结果:
DatetimeIndex(['2018-11-14', '2018-11-15', '2018-11-16', '2018-11-17',
'2018-11-18', '2018-11-19', '2018-11-20', '2018-11-21',
'2018-11-22', '2018-11-23', '2018-11-24', '2018-11-25',
'2018-11-26', '2018-11-27', '2018-11-28', '2018-11-29',
'2018-11-30', '2018-12-01'],
dtype='datetime64[ns]', freq='D')
****************************************
2018-11-04 0
2018-11-11 1
2018-11-18 2
2018-11-25 3
2018-12-02 4
Freq: W-SUN, dtype: int32
****************************************
3
****************************************
20181118
****************************************
杭州天气的时序处理
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
df = pd.read_csv('E:/Data/practice/hz_weather.csv')
df = df[['日期', '最高气温', '最低气温']]
# print(df.head())
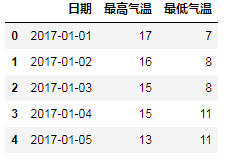
print(type(df.日期)) # <class 'pandas.core.series.Series'> print(type(df.日期.values)) # <class 'numpy.ndarray'> # 修改日期格式 # 注意,df.日期得到的是Series对象,df.日期.values得到的是ndarray多维数组 # pd.to_datetime()函数将输入解析成时间对象的格式并返回 # format参数指定解析的方式 # 当输入列表形式的值时,返回DatetimeIndex;当输入Series时,返回Series;当输入常量时,返回Timestamp print(type(pd.to_datetime(df.日期.values, format="%Y-%m-%d"))) # <class 'pandas.core.indexes.datetimes.DatetimeIndex'> print(type(pd.to_datetime(df.日期, format="%Y-%m-%d"))) # <class 'pandas.core.series.Series'> df.日期 = pd.to_datetime(df.日期.values, format="%Y-%m-%d") # print(df.head())
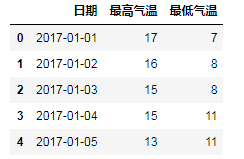
# 将日期设置为索引
df = df.set_index('日期')
# 取出第0个索引值对应的日期
print(df.index[0]) # 2017-01-01 00:00:00
# DatetimeIndex里存的是一个个的Timestamp,查看一下类型
print(type(df.index[0])) # <class 'pandas._libs.tslibs.timestamps.Timestamp'>
# print(df.info())
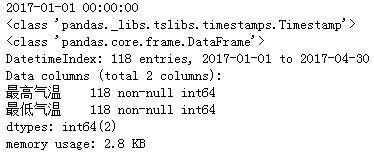
# 提取1月份的温度数据 df_jan = df[(df.index >= "2017-1-1") & (df.index < "2017-2-1")] # 或用这种方式也可以 df_jan = df["2017-1-1":"2017-1-31"] # print(df_jan.info())
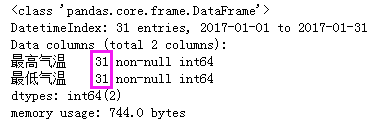
# 只取到月份
df_m = df.to_period('M')
# print(df_m.head())

# 利用上面的只取到月份,对level=0(即索引层级)做聚合就可以求月内的平均值等 s_m_mean = df_m.groupby(level=0).mean() # print(s_m_mean.head())
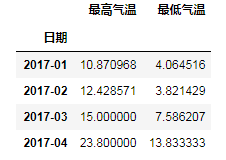
# 绘制[最高温度]和[最低温度]两个指标随着索引[时间]变化的图 fig, ax = plt.subplots(1, 1, figsize=(12, 4)) df.plot(ax=ax) plt.show()

附:matplotlib中文支持

到此这篇关于python Pandas时序数据处理 的文章就介绍到这了,更多相关Pandas 时序数据 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据分析之 Pandas Dataframe合并和去重操作
目录 一.之 Pandas Dataframe合并 二.去重操作 一.之 Pandas Dataframe合并 在数据分析中,避免不了要从多个数据集中取数据,那就避免不了要进行数据的合并,这篇文章就来介绍一下 Dataframe 对象的合并操作. Pandas 提供了merge()方法来进行合并操作,使用语法如下: pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=Fa
-
Python数据分析之 Pandas Dataframe条件筛选遍历详情
目录 一.条件筛选 二.Dataframe数据遍历 for...in...语句 iteritems()方法 iterrows()方法 itertuples()方法 一.条件筛选 查询Pandas Dataframe数据时,经常会筛选出符合条件的数据,接下来介绍一下具体的使用方式. 示例Dataframe如下: 单条件筛选,例如查询gender为woman的数据: df[df["gender"]=="woman"] # 或 df.loc[df["gender
-
Python数据分析之 Pandas Dataframe修改和删除及查询操作
目录 一.查询操作 元素的查询 二.修改操作 行列索引的修改 元素值的修改 三.行和列的删除操作 一.查询操作 可以使用Dataframe的index属性和columns属性获取行.列索引. import pandas as pd data = {"name": ["Alice", "Bob", "Cindy", "David"], "age": [25, 23, 28, 24], &q
-
python pandas时序处理相关功能详解
创建时间序列 函数pd.date_range() 根据指定的范围,生成时间序列DatetimeIndex,每隔元素的类型为Timestamp.该函数应用较多. ts = pd.date_range('2017-09-01', periods=10, freq='d', normalize=False) ts 输出为: DatetimeIndex(['2017-09-01', '2017-09-02', '2017-09-03', '2017-09-04', '2017-09-05', '2017
-
Python的Pandas时序数据详解
目录 Pandas时序数据 一.python中的时间表示-datetime模块 1.换取当前时间 2.指定时间 3.运算 二. Pandas处理时序序列 1.pd.Timestamp() 2.pd.Timedelta() 3.运算 4.时间索引 总结 Pandas时序数据 前言 在数据分析中,时序数据是一类非常重要的数据.事物的发展总是伴随着时间的推移,数据也会在各个时间点上产生. 一.python中的时间表示-datetime模块 Python的标准库datetime支持创建和处理时间,P
-
Python数据分析Pandas Dataframe排序操作
目录 1.索引的排序 2.值的排序 前言: 数据的排序是比较常用的操作,DataFrame 的排序分为两种,一种是对索引进行排序,另一种是对值进行排序,接下来就分别介绍一下. 1.索引的排序 DataFrame 提供了sort_index()方法来进行索引的排序,通过axis参数指定对行索引排序还是对列索引排序,默认为0,表示对行索引排序,设置为1表示对列索引进行排序:ascending参数指定升序还是降序,默认为True表示升序,设置为False表示降序, 具体使用方法如下: 对行索引进行降序
-
Python数据分析 Pandas Series对象操作
目录 一.Pandas Series对象 Series数据结构 创建Series对象 二.Series对象的基本操作 Series 常用属性 Series 常用方法 Series 运算 一.Pandas Series对象 Pandas 是基于 NumPy 设计实现的 Python 数据分析库,Pandas 提供了大量的能让我们高效处理数据的函数和方法,也纳入了很多数据处理的库以及一些数据模型,可以说非常强大. 可以使用以下命令进行安装: conda install pandas # 或 pip
-
python Pandas时序数据处理
目录 Python中时间的一些常用操作 Pandas时间序列(DatetimeIndex)与时序数据 杭州天气的时序处理 附:matplotlib中文支持 Python中时间的一些常用操作 import time # 从格林威治时间到现在,单位秒 print('系统时间戳:', time.time()) print('本地时间按格式转成str:', time.strftime('%Y-%m-%d %X', time.localtime())) # 无参的localtime返回time.struc
-
python pandas数据处理教程之合并与拼接
目录 前言 一.join 1.leftjoin 2.rightjoin 3.innerjoin 4.outjoin 二.merge 三.concat 1.纵向合并 2.横向合并 四.append 1.同结构数据追加 2.不同结构数据追加 3.追加合并多个数据集 五.combine_first 六.update 总结 前言 在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集.pandas提供了多种方法完全可以满足数据处理的常用需求.具
-
Python Pandas数据处理高频操作详解
目录 引入依赖 算法相关依赖 获取数据 生成df 重命名列 增加列 缺失值处理 独热编码 替换值 删除列 数据筛选 差值计算 数据修改 时间格式转换 设置索引列 折线图 散点图 柱状图 热力图 66个最常用的pandas数据分析函数 从各种不同的来源和格式导入数据 导出数据 创建测试对象 查看.检查数据 数据选取 数据清理 筛选,排序和分组依据 数据合并 数据统计 16个函数,用于数据清洗 1.cat函数 2.contains 3.startswith/endswith 4.count 5.ge
-
python pandas数据处理之删除特定行与列
目录 dropna() 方法过滤任何含有缺失值的行 方法一:dropna() 其他参数解析 方法二:替换并删除,Python pandas 如果某列值为空,过滤删除所在行数据 总结 dropna() 方法过滤任何含有缺失值的行 pandas.DataFrame里,如果一行数据有任意值为空,则过滤掉整行,这时候使用dropna()方法是合适的.下面的案例,任意列只要有一个为空数据,则整行都干掉.但是我们常常遇到的情况,是根据一个指标(一列)数据的情况,去过滤行数据,类似Excel里面的过滤漏斗,怎
-
python pandas消除空值和空格以及 Nan数据替换方法
在人工采集数据时,经常有可能把空值和空格混在一起,一般也注意不到在本来为空的单元格里加入了空格.这就给做数据处理的人带来了麻烦,因为空值和空格都是代表的无数据,而pandas中Series的方法notnull()会把有空格的数据也纳入进来,这样就不能完整地得到我们想要的数据了,这里给出一个简单的方法处理该问题. 方法1: 既然我们认为空值和空格都代表无数据,那么可以先得到这两种情况下的布尔数组. 这里,我们的DataFrame类型的数据集为df,其中有一个变量VIN,那么取得空值和空格的布尔数组
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
利用python做表格数据处理
技术背景 数据处理是一个当下非常热门的研究方向,通过对于大型实际场景中的数据进行建模,可以用于预测下一阶段可能出现的情况.比如我们有过去的2002年-2018年的黄金价格的数据: 该数据来源于Gitee上的一个开源项目.其中包含有:时间.开盘价.收盘价.最高价.最低价.交易数以及成交额这么几个参数.假如我们使用一个机器学习的模型去分析这个数据,也许我们可以预测在这个数据中并不存在的金价数据.如果预测的契合度较好,那么对于一些人的投资策略来说有重大意义.但是这种实际场景下的数据,往往数据量是非常大
-
Python Pandas知识点之缺失值处理详解
前言 数据处理过程中,经常会遇到数据有缺失值的情况,本文介绍如何用Pandas处理数据中的缺失值. 一.什么是缺失值 对数据而言,缺失值分为两种,一种是Pandas中的空值,另一种是自定义的缺失值. 1. Pandas中的空值有三个:np.nan (Not a Number) . None 和 pd.NaT(时间格式的空值,注意大小写不能错),这三个值可以用Pandas中的函数isnull(),notnull(),isna()进行判断. isnull()和notnull()的结果互为取反,isn