Python读取HTML中的canvas并且以图片形式存入Word文档
目录
- 前言
- 创建Word文档并插入
- 插入到已存在的Word文档指定的位置
前言
朋友提问:

创建Word文档并插入
市面上有很多图表绘制库,例如echarts和highcharts等等。对于这种由js动态绘制的图表,我们只能控制游览器自动截图存入word,
完整代码如下:
from docx import Document
import os
from selenium import webdriver
browser = webdriver.Chrome()
# 调整游览器大小达到调整图表宽度的目的
browser.set_window_size(540, 1024)
url = "file://" + \
os.path.abspath("html/awrcrt_MESDB_1_21369_21373.html").replace("\\", "/")
browser.get(url)
doc = Document()
for canvas in browser.find_elements_by_tag_name("canvas"):
canvas.location_once_scrolled_into_view
canvas.screenshot("tmp.png")
doc.add_picture("tmp.png")
doc.save("img.docx")
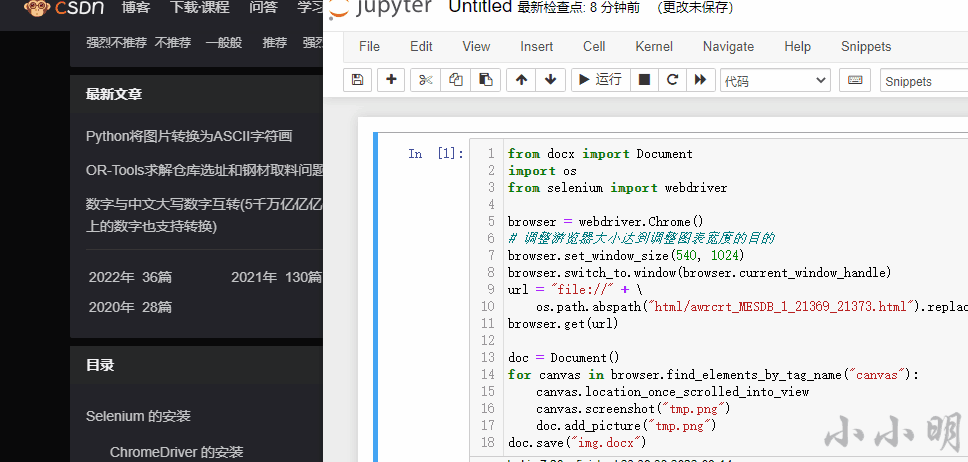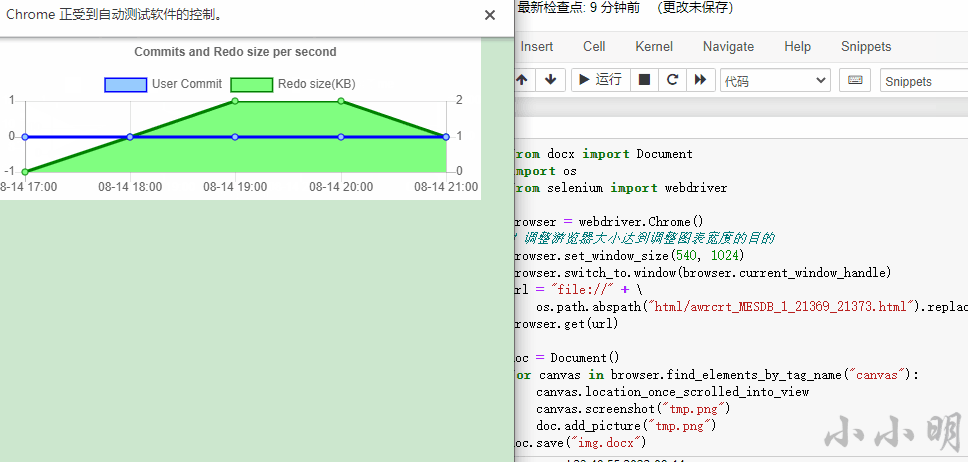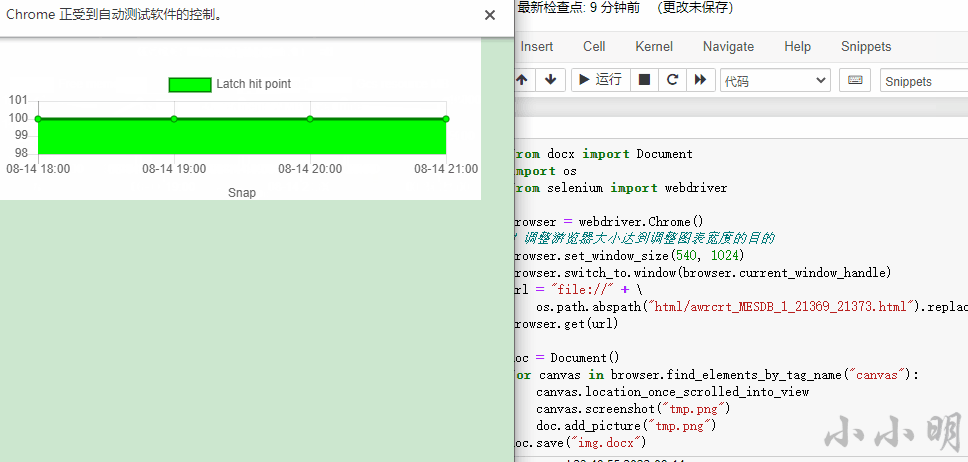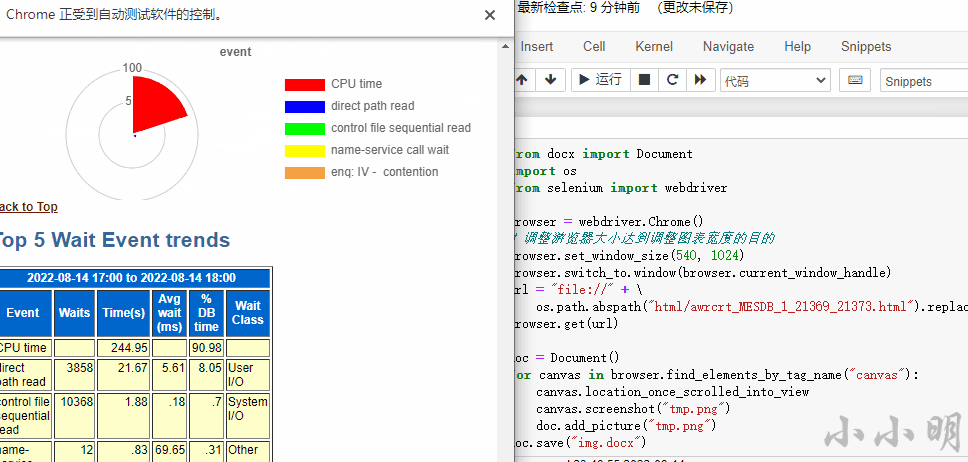
然后我们得到Word文档:

插入到已存在的Word文档指定的位置
后面朋友又反馈,只需要插入HTML中的指定几张图表到现有Word文档的指定位置。
待插入的图表元素都有对应的ID可以定位:
那我们只需要对Word文档要插入的位置进行标记,模板如下:

然后完整代码如下:
from docx.shared import Mm
from docxtpl import DocxTemplate, InlineImage
from docx import Document
import os
from selenium import webdriver
browser = webdriver.Chrome()
# 调整游览器大小达到调整图表宽度的目的
browser.set_window_size(540, 1024)
url = "file://" + \
os.path.abspath("html/awrcrt_MESDB_1_21369_21373.html").replace("\\", "/")
browser.get(url)
tpl = DocxTemplate("数据库性能概览_模板.docx")
canvas_ids = ["canvas_cpu", "canvas_conn",
"canvas_commit", "canvas_logon", "canvas_event"]
context = {}
context["dbname"] = "MESDB"
for canvas_id in canvas_ids:
canvas = browser.find_element_by_id(canvas_id)
canvas.location_once_scrolled_into_view
canvas.screenshot(f"{canvas_id}.png")
context[canvas_id] = InlineImage(tpl, f"{canvas_id}.png", width=Mm(165))
tpl.render(context)
tpl.save("数据库性能概览.docx")
browser.close()
生成结果:
到此这篇关于Python读取HTML中的canvas并且以图片形式存入Word文档的文章就介绍到这了,更多相关Python读取canvas内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

如何让Python在HTML中运行
目录 PyScript 快速体验 小结 最近一直在更新Java新特性和IDEA Tips两个专栏,其他方向内容的动态关注少了.昨天天晚上刷推的时候,瞄到了这个神奇的东西,觉得挺cool的,拿出来分享下: 相信你看到图,不用我说,你也猜到是啥了吧?html里可以跑python代码了! 看到好多知识已经开始猛吹未来了,但乍看怎么觉得有点像JSP?或者一些模版引擎?是进步还是倒退呢?与其瞎想,不如仔细看看这个东东的能力吧! 根据官方介绍,这个名为PyScript的框架,其核心目标是为开发者提供在标准H
-
Python办公自动化从Excel中计算整理数据并写入Word
前言 在前几天的文章中我们讲解了如何从Word表格中提取指定数据并按照格式保存到Excel中,今天我们将再次以一位读者提出的真实需求来讲解如何使用Python从Excel中计算.整理数据并写入Word中,其实并不难,主要就是以下两步: openpyxl读取Excel获取内容 docx读写Word文件 那我们开始吧! 需求确认 首先来看下我们需要处理的Excel部分数据,因涉及隐私已经将数据皮卡丘化 可以看到数据非常多,并且还存在重复数据.而我们要做的就是对每一列的数据按照一定的规则进行计算.整理
-
python+html实现前后端数据交互界面显示的全过程
目录 前言 1.python开发工具 2.项目创建 总结 前言 最近刚刚开始学习如何将python后台与html前端结合起来,现在写一篇blog记录一下,我采用的是前后端不分离形式. 话不多说,先来实现一个简单的计算功能吧,前端输入计算的数据,后端计算结果,返回结果至前端进行显示. 1.python开发工具 我选用的是pycharm专业版,因为社区版本无法创建django程序 2.项目创建 第一步:打开pycharm,创建一个django程序 蓝圈圈起来的为自定义的名字,点击右下角的create
-
Python Tkinter Canvas画布控件详解
目录 Canvas控件基本属性 Canvas控件绘图常用方法 Canvas 控件具有两个功能,首先它可以用来绘制各种图形,比如弧形.线条.椭圆形.多边形和矩形等,其次 Canvas 控件还可以用来展示图片(包括位图),我们将这些绘制在画布控件上的图形,称之为“画布对象”. 每一个画布对象都有一个“唯一身份ID”,这是 Tkinter 自动为其创建的,从而方便控制和操作这些画布对象. 通过 Canvas 控件创建一个简单的图形编辑器,让用户可以达到自定义图形的目的,就像使用画笔在画布上绘画一样,可
-
Python实现读取HTML表格 pd.read_html()
目录 Python读取HTML表格 pd.read_html读取数据不完整问题 解决办法 Python读取HTML表格 数据部门提供的数据是xls格式的文件,但是执行读取xls文件的脚本报错. xlrd报错: xlrd.biffh.XLRDError: Unsupported format, or corrupt file: Expected BOF record; found b'<html xm' 读取xlrd的脚本 data_lines = read_excel_file(self.fil
-
Python自动化办公之Word转PDF的实现
目录 pdf 工具包 - pdfkit html 转 pdf 网址 转 pdf 字符串生成pdf 结合 pydocx 将 word 转 html 再转 pdf 该章节我们将要学习如何将 word 文件转为 PDF文件,其实网上有很多种生成 PDF 的教程,不过绝大多数都是以 windows 为主的,并且兼容有很多的问题.windows.mac.linux 同时兼容的情况比较少,所以今天的章节我们就来学习一下如何在 windows.mac.linux 三种系统中都可以生成 PDF 的解决方案. p
-
Python自动化办公之Word文档的创建与生成
目录 保存生成 word 生成标题 生成段落 添加图片 添加表格 分页 上几章节我们主要学习了如何读取文章,而主要任务是读取文档中的文本信息,也就是字符串,而图片本身是不可读的文件所以并没有去读取图片.从今天开始将学习如何通过 python 脚本来自动生成一个 word 文档. 保存生成 word 在学习如何生成一个 word 文档之前,我们来看看如何保存生成 word 文件,因为马上就会用到. 使用方法: document_obj.save(文件地址) ---> /home/demo.docx
-
Python读取HTML中的canvas并且以图片形式存入Word文档
目录 前言 创建Word文档并插入 插入到已存在的Word文档指定的位置 前言 朋友提问: 创建Word文档并插入 市面上有很多图表绘制库,例如echarts和highcharts等等.对于这种由js动态绘制的图表,我们只能控制游览器自动截图存入word, 完整代码如下: from docx import Document import os from selenium import webdriver browser = webdriver.Chrome() # 调整游览器大小达到调整图表宽度
-
Python实现Word文档转换Markdown的示例
随着SaaS服务的流行,越来越多的人选择在各个平台上编写文档,制作表格并进行分享. 同时,随着Markdown语法的破圈,很多平台开始集成支持这种简洁的书写标记语言,这样可以保证平台上用户文档样式的统一性. 但是在一些场景下,我们还是会在本地的Office软件上写有很多文档,或者历史遗留了很多本地文档. 如果我们需要将其上传到各大平台,直接复制粘贴,大概率是会造成文档内容结构和样式的丢失.于此我们需要将其转换为 Markdown 语法. 很多桌面软件(比如Typora)都提供了导入 Word 文
-
Python实现自动化处理Word文档的方法详解
目录 1. 批量生成Word文档 2. 将Word文档批量转换成PDF 3. 在Word文档中批量标记关键词 4. 在Word文档中批量替换关键词 使用Python实现Word文档的自动化处理,包括批量生成Word文档.在Word文档中批量进行查找和替换.将Word文档批量转换成PDF等. 1. 批量生成Word文档 安装openpyxl模块 pip install openpyxl 安装python-docx模块 pip install python-docx openpyxl模块可以读写扩展
-
asp.net中如何批量导出access某表内容到word文档
下面通过图文并茂的方式给大家介绍asp.net中批量导出access某表内容到word文档的方法,具体详情如下: 一.需求: 需要将表中每一条记录中的某些内容导出在一个word文档中,并将这些文档保存在指定文件夹目录下 二.界面,简单设计如下: 三.添加office相关引用 添加后可在解决方案资源管理器中看到: 四.添加form1中的引用 using System.Data.OleDb; using System.Data.SqlClient; using System.IO; using Mi
-
Python读取mp3中ID3信息的方法
本文实例讲述了Python读取mp3中ID3信息的方法.分享给大家供大家参考.具体分析如下: pyid3不好用,常常有不认识的. mutagen不错,不过默认带的easyid3不会读取注释,需要手工hack一下 Python代码如下: from mutagen.mp3 import MP3 import mutagen.id3 from mutagen.easyid3 import EasyID3 EasyID3.valid_keys["comment"]="COMM::'X
-
python读取文本中数据并转化为DataFrame的实例
在技术问答中看到一个这样的问题,感觉相对比较常见,就单开一篇文章写下来. 从纯文本格式文件 "file_in"中读取数据,格式如下: 需要输出成"file_out",格式如下: 数据的原格式是"类别:内容",以空行"\n"为分条目,转换后变成一个条目一行,按照类别顺序依次写出内容. 建议读取后,使用pandas,把数据建立称DataFrame的表格.这样方便以后处理数据.但是原格式并不是通常的表格格式,所以要先做一些简单的处理
-
python 读取txt中每行数据,并且保存到excel中的实例
使用xlwt读取txt文件内容,并且写入到excel中,代码如下,已经加了注释. 代码简单,具体代码如下: # coding=utf-8 ''' main function:主要实现把txt中的每行数据写入到excel中 ''' ################# #第一次执行的代码 import xlwt #写入文件 import xlrd #打开excel文件 fopen=open("e:\\a\\bb\\a.txt",'r') lines=fopen.readlines() #新
-
python读取LMDB中图像的方法
本文实例为大家分享了python读取LMDB中的图像具体代码,供大家参考,具体内容如下 图像数据写入LMDB之后最好再按照写入的逻辑反向解析写入的图像,如果图像能够被还原则证明写入方式是没有问题的. from PIL import Image def read_from_lmdb(lmdb_path,img_save_to): try: lmdb_env=lmdb.open(lmdb_path, map_size=3221225472) lmdb_txn=lmdb_env.begin() lmd
-
Python读取excel中的图片完美解决方法
excel中有图片是很常见的,但是通过python读取excel中的图片没有很好的解决办法. 网上找了一种很聪明的方法,原理是这样的: 1.将待读取的excel文件后缀名改成zip,变成压缩文件. 2.再解压这个文件. 3.在解压后的文件夹中,就有excel中的图片. 4.这样读excel中的图片,就变成了读文件夹中的图片了,和普通文件一样,可以做各种处理. 解压后的压缩包如下: python脚本如下: ''' File Name: readexcelimg Author: tim Date:
-
python读取文本中的坐标方法
利用python读取文本文件很方便,用到了string模块,下面用一个小例子演示读取文本中的坐标信息. import string x , y , z = [] , [] ,[] with open("test.txt") as A: for eachline in A: tmp = eachline.split() x.append(string.atof(tmp[0])) y.append(string.atof(tmp[1])) z.append(string.atof(tmp[