Python线程池的实现浅析
目录
- 一、序言
- 二、正文
- 1、Future 对象
- 2、提交函数自动创建 Future 对象
- 3、future.set_result 到底干了什么事情
- 4、提交多个函数
- 5、使用 map 来提交多个函数
- 6、按照顺序等待执行
- 7、取消一个函数的执行
- 8、函数执行时出现异常
- 9、等待所有函数执行完毕
- 三、小结
雷猴啊,兄弟们!今天来展示一下如何用Python快速实现一个线程池。
一、序言
当有多个 IO 密集型的任务要被处理时,我们自然而然会想到多线程。但如果任务非常多,我们不可能每一个任务都启动一个线程去处理,这个时候最好的办法就是实现一个线程池,至于池子里面的线程数量可以根据业务场景进行设置。
比如我们实现一个有 10 个线程的线程池,这样可以并发地处理 10 个任务,每个线程将任务执行完之后,便去执行下一个任务。通过使用线程池,可以避免因线程创建过多而导致资源耗尽,而且任务在执行时的生命周期也可以很好地把控。
而线程池的实现方式也很简单,但这里我们不打算手动实现,因为 Python 提供了一个标准库 concurrent.futures,已经内置了对线程池的支持。所以本篇文章,我们就来详细介绍一下该模块的用法。
二、正文
1、Future 对象
当我们往线程池里面提交一个函数时,会分配一个线程去执行,同时立即返回一个 Future 对象。通过 Future 对象可以监控函数的执行状态,有没有出现异常,以及有没有执行完毕等等。如果函数执行完毕,内部便会调用 future.set_result 将返回值设置到 future 里面,然后外界便可调用 future.result 拿到返回值。
除此之外 future 还可以绑定回调,一旦函数执行完毕,就会以 future 为参数,自动触发回调。所以 future 被称为未来对象,可以把它理解为函数的一个容器,当我们往线程池提交一个函数时,会立即创建相应的 future 然后返回。函数的执行状态什么的,都通过 future 来查看,当然也可以给它绑定一个回调,在函数执行完毕时自动触发。
那么下面我们就来看一下 future 的用法,文字的话理解起来可能有点枯燥。
将函数提交到线程池里面运行时,会立即返回一个对象
这个对象就叫做 Future 对象,里面包含了函数的执行状态等等
当然我们也可以手动创建一个Future对象。
from concurrent.futures import Future
# 创建 Future 对象 future
future = Future()
# 给 future 绑定回调
def callback(f: Future):
print("当set_result的时候会执行回调,result:",
f.result())
future.add_done_callback(callback)
# 通过 add_done_callback 方法即可给 future 绑定回调
# 调用的时候会自动将 future 作为参数
# 如果需要多个参数,那么就使用偏函数
# 回调函数什么时候执行呢?
# 显然是当 future 执行 set_result 的时候
# 如果 future 是向线程池提交函数时返回的
# 那么当函数执行完毕时会自动执行 future.set_result(xx)
# 并将自身的返回设置进去
# 而这里的 future 是我们手动创建的,因此需要手动执行
future.set_result("嘿嘿")
当set_result的时候会执行回调,result: 嘿嘿
需要注意的是:只能执行一次 set_result,但是可以多次调用 result 获取结果。
from concurrent.futures import Future
future = Future()
future.set_result("哼哼")
print(future.result()) # 哼哼
print(future.result()) # 哼哼
print(future.result()) # 哼哼
执行 future.result() 之前一定要先 set_result,否则会一直处于阻塞状态。当然 result 方法还可以接收一个 timeout 参数,表示超时时间,如果在指定时间内没有获取到值就会抛出异常。
2、提交函数自动创建 Future 对象
我们上面是手动创建的 Future 对象,但工作中很少会手动创建。我们将函数提交到线程池里面运行的时候,会自动创建 Future 对象并返回。这个 Future 对象里面就包含了函数的执行状态,比如此时是处于暂停、运行中还是完成等等,并且函数在执行完毕之后,还会调用 future.set_result 将自身的返回值设置进去。
from concurrent.futures import ThreadPoolExecutor
import time
def task(name, n):
time.sleep(n)
return f"{name} 睡了 {n} 秒"
# 创建一个线程池
# 里面还可以指定 max_workers 参数,表示最多创建多少个线程
# Python学习交流裙279199867
# 如果不指定,那么每提交一个函数,都会为其创建一个线程
executor = ThreadPoolExecutor()
# 通过 submit 即可将函数提交到线程池,一旦提交,就会立刻运行
# 因为开启了一个新的线程,主线程会继续往下执行
# 至于 submit 的参数,按照函数名,对应参数提交即可
# 切记不可写成task("古明地觉", 3),这样就变成调用了
future = executor.submit(task, "屏幕前的你", 3)
# 由于函数里面出现了 time.sleep,并且指定的 n 是 3
# 所以函数内部会休眠 3 秒,显然此时处于运行状态
print(future)
"""
<Future at 0x7fbf701726d0 state=running>
"""
# 我们说 future 相当于一个容器,包含了内部函数的执行状态
# 函数是否正在运行中
print(future.running())
"""
True
"""
# 函数是否执行完毕
print(future.done())
"""
False
"""
# 主程序也 sleep 3 秒
time.sleep(3)
# 显然此时函数已经执行完毕了
# 并且打印结果还告诉我们返回值类型是 str
print(future)
"""
<Future at 0x7fbf701726d0 state=finished returned str>
"""
print(future.running())
"""
False
"""
print(future.done())
"""
True
"""
# 函数执行完毕时,会将返回值设置在 future 里
# 也就是说一旦执行了 future.set_result
# 那么就表示函数执行完毕了,然后外界可以调用 result 拿到返回值
print(future.result())
"""
屏幕前的你 睡了 3 秒
"""
这里再强调一下 future.result(),这一步是会阻塞的,举个例子:
# 提交函数 future = executor.submit(task, "屏幕前的你", 3) start = time.perf_counter() future.result() end = time.perf_counter() print(end - start) # 3.00331525
可以看到,future.result() 这一步花了将近 3s。其实也不难理解,future.result() 是干嘛的?就是为了获取函数的返回值,可函数都还没有执行完毕,它又从哪里获取呢?所以只能先等待函数执行完毕,将返回值通过 set_result 设置到 future 里面之后,外界才能调用 future.result() 获取到值。
如果不想一直等待的话,那么在获取值的时候可以传入一个超时时间。
from concurrent.futures import (
ThreadPoolExecutor,
TimeoutError
)
import time
def task(name, n):
time.sleep(n)
return f"{name} 睡了 {n} 秒"
executor = ThreadPoolExecutor()
future = executor.submit(task, "屏幕前的你", 3)
try:
# 1 秒之内获取不到值,抛出 TimeoutError
res = future.result(1)
except TimeoutError:
pass
# 再 sleep 2 秒,显然函数执行完毕了
time.sleep(2)
# 获取返回值
print(future.result())
"""
屏幕前的你 睡了 3 秒
"""
当然啦,这么做其实还不够智能,因为我们不知道函数什么时候执行完毕。所以最好的办法还是绑定一个回调,当函数执行完毕时,自动触发回调。
from concurrent.futures import ThreadPoolExecutor
import time
def task(name, n):
time.sleep(n)
return f"{name} 睡了 {n} 秒"
def callback(f):
print(f.result())
executor = ThreadPoolExecutor()
future = executor.submit(task, "屏幕前的你", 3)
# 绑定回调,3 秒之后自动调用
future.add_done_callback(callback)
"""
屏幕前的你 睡了 3 秒
"""
需要注意的是,在调用 submit 方法之后,提交到线程池的函数就已经开始执行了。而不管函数有没有执行完毕,我们都可以给对应的 future 绑定回调。
如果函数完成之前添加回调,那么会在函数完成后触发回调。如果函数完成之后添加回调,由于函数已经完成,代表此时的 future 已经有值了,或者说已经 set_result 了,那么会立即触发回调。
3、future.set_result 到底干了什么事情
当函数执行完毕之后,会执行 set_result,那么这个方法到底干了什么事情呢?
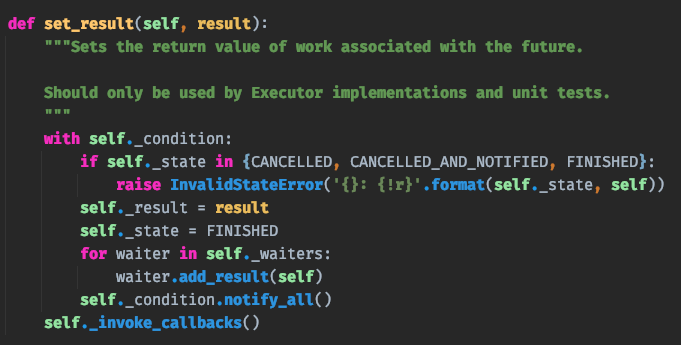
我们看到 future 有两个被保护的属性,分别是 _result 和 _state。显然 _result 用于保存函数的返回值,而 future.result() 本质上也是返回 _result 属性的值。而 _state 属性则用于表示函数的执行状态,初始为 PENDING,执行中为 RUNING,执行完毕时被设置为 FINISHED。
调用 future.result() 的时候,会判断 _state 的属性,如果还在执行中就一直等待。当 _state 为 FINISHED 的时候,就返回 _result 属性的值。
4、提交多个函数
我们上面每次只提交了一个函数,但其实可以提交任意多个,我们来看一下:
from concurrent.futures import ThreadPoolExecutor
import time
def task(name, n):
time.sleep(n)
return f"{name} 睡了 {n} 秒"
executor = ThreadPoolExecutor()
futures = [executor.submit(task, "屏幕前的你", 3),
executor.submit(task, "屏幕前的你", 4),
executor.submit(task, "屏幕前的你", 1)]
# 此时都处于running
print(futures)
"""
[<Future at 0x1b5ff622550 state=running>,
<Future at 0x1b5ff63ca60 state=running>,
<Future at 0x1b5ff63cdf0 state=running>]
"""
time.sleep(3)
# 主程序 sleep 3s 后
# futures[0]和futures[2]处于 finished
# futures[1]仍处于 running
print(futures)
"""
[<Future at 0x1b5ff622550 state=running>,
<Future at 0x1b5ff63ca60 state=running>,
<Future at 0x1b5ff63cdf0 state=finished returned str>]
"""
如果是多个函数,要如何拿到返回值呢?很简单,遍历 futures 即可。
executor = ThreadPoolExecutor()
futures = [executor.submit(task, "屏幕前的你", 5),
executor.submit(task, "屏幕前的你", 2),
executor.submit(task, "屏幕前的你", 4),
executor.submit(task, "屏幕前的你", 3),
executor.submit(task, "屏幕前的你", 6)]
for future in futures:
print(future.result())
"""
屏幕前的你 睡了 5 秒
屏幕前的你 睡了 2 秒
屏幕前的你 睡了 4 秒
屏幕前的你 睡了 3 秒
屏幕前的你 睡了 6 秒
"""
这里面有一些值得说一说的地方,首先 futures 里面有 5 个 future,记做 future1, future2, future3, future4, future5。
当使用 for 循环遍历的时候,实际上会依次遍历这 5 个 future,所以返回值的顺序就是我们添加的函数的顺序。由于 future1 对应的函数休眠了 5s,那么必须等到 5s 后,future1 里面才会有值。
但这五个函数是并发执行的,future2, future3, future4 由于只休眠了 2s, 4s, 3s,所以肯定会先执行完毕,然后执行 set_result,将返回值设置到对应的 future 里。
但 Python 的 for 循环不可能在第一次迭代还没有结束,就去执行第二次迭代。因为 futures 里面的几个 future 的顺序已经一开始就被定好了,只有当第一个 future.result() 执行完成之后,才会执行第二个 future.result(),以及第三个、第四个。
因此即便后面的函数已经执行完毕,但由于 for 循环的顺序,也只能等着,直到前面的 future.result() 执行完毕。所以当第一个 future.result() 结束时,后面三个 future.result() 会立刻输出,因为它们内部的函数已经执行结束了。
而最后一个 future,由于内部函数 sleep 了 6 秒,因此要再等待 1 秒,才会打印 future.result()。
5、使用 map 来提交多个函数
使用 submit 提交函数会返回一个 future,并且还可以给 future 绑定一个回调。但如果不关心回调的话,那么还可以使用 map 进行提交。
executor = ThreadPoolExecutor()
# map 内部也是使用了 submit
results = executor.map(task,
["屏幕前的你"] * 3,
[3, 1, 2])
# 并且返回的是迭代器
print(results)
"""
<generator object ... at 0x0000022D78EFA970>
"""
# 此时遍历得到的是不再是 future
# 而是 future.result()
for result in results:
print(result)
"""
屏幕前的你 睡了 3 秒
屏幕前的你 睡了 1 秒
屏幕前的你 睡了 2 秒
"""
可以看到,当使用for循环的时候,map 执行的逻辑和 submit 是一样的。唯一的区别是,此时不需要再调用 result 了,因为返回的就是函数的返回值。
或者我们直接调用 list 也行。
executor = ThreadPoolExecutor()
results = executor.map(task,
["屏幕前的你"] * 3,
[3, 1, 2])
print(list(results))
"""
['屏幕前的你 睡了 3 秒',
'屏幕前的你 睡了 1 秒',
'屏幕前的你 睡了 2 秒']
"""
results 是一个生成器,调用 list 的时候会将里面的值全部产出。由于 map 内部还是使用的 submit,然后通过 future.result() 拿到返回值,而耗时最长的函数需要 3 秒,因此这一步会阻塞 3 秒。3 秒过后,会打印所有函数的返回值。
6、按照顺序等待执行
上面在获取返回值的时候,是按照函数的提交顺序获取的。如果我希望哪个函数先执行完毕,就先获取哪个函数的返回值,该怎么做呢?
from concurrent.futures import (
ThreadPoolExecutor,
as_completed
)
import time
def task(name, n):
time.sleep(n)
return f"{name} 睡了 {n} 秒"
executor = ThreadPoolExecutor()
futures = [executor.submit(task, "屏幕前的你", 5),
executor.submit(task, "屏幕前的你", 2),
executor.submit(task, "屏幕前的你", 1),
executor.submit(task, "屏幕前的你", 3),
executor.submit(task, "屏幕前的你", 4)]
for future in as_completed(futures):
print(future.result())
"""
屏幕前的你 睡了 1 秒
屏幕前的你 睡了 2 秒
屏幕前的你 睡了 3 秒
屏幕前的你 睡了 4 秒
屏幕前的你 睡了 5 秒
"""
此时谁先完成,谁先返回。
7、取消一个函数的执行
我们通过 submit 可以将函数提交到线程池中执行,但如果我们想取消该怎么办呢?
executor = ThreadPoolExecutor() future1 = executor.submit(task, "屏幕前的你", 1) future2 = executor.submit(task, "屏幕前的你", 2) future3 = executor.submit(task, "屏幕前的你", 3) # 取消函数的执行 # 会将 future 的 _state 属性设置为 CANCELLED future3.cancel() # 查看是否被取消 print(future3.cancelled()) # False
问题来了,调用 cancelled 方法的时候,返回的是False,这是为什么?很简单,因为函数已经被提交到线程池里面了,函数已经运行了。而只有在还没有运行时,取消才会成功。
可这不矛盾了吗?函数一旦提交就会运行,只有不运行才会取消成功,这怎么办?还记得线程池的一个叫做 max_workers 的参数吗?用来控制线程池内的线程数量,我们可以将最大的线程数设置为2,那么当第三个函数进去的时候,就不会执行了,而是处于暂停状态。
executor = ThreadPoolExecutor(max_workers=2) future1 = executor.submit(task, "屏幕前的你", 1) future2 = executor.submit(task, "屏幕前的你", 2) future3 = executor.submit(task, "屏幕前的你", 3) # 如果池子里可以创建空闲线程 # 那么函数一旦提交就会运行,状态为 RUNNING print(future1._state) # RUNNING print(future2._state) # RUNNING # 但 future3 内部的函数还没有运行 # 因为池子里无法创建新的空闲线程了,所以状态为 PENDING print(future3._state) # PENDING # 取消函数的执行,前提是函数没有运行 # 会将 future 的 _state 属性设置为 CANCELLED future3.cancel() # 查看是否被取消 print(future3.cancelled()) # True print(future3._state) # CANCELLED
在启动线程池的时候,肯定是需要设置容量的,不然处理几千个函数要开启几千个线程吗。另外当函数被取消了,就不可以再调用 future.result() 了,否则的话会抛出 CancelledError。
8、函数执行时出现异常
我们前面的逻辑都是函数正常执行的前提下,但天有不测风云,如果函数执行时出现异常了该怎么办?
from concurrent.futures import ThreadPoolExecutor
def task1():
1 / 0
def task2():
pass
executor = ThreadPoolExecutor(max_workers=2)
future1 = executor.submit(task1)
future2 = executor.submit(task2)
print(future1)
print(future2)
"""
<Future at 0x7fe3e00f9e50 state=finished raised ZeroDivisionError>
<Future at 0x7fe3e00f9eb0 state=finished returned NoneType>
"""
# 结果显示 task1 函数执行出现异常了
# 那么这个异常要怎么获取呢?
print(future1.exception())
print(future1.exception().__class__)
"""
division by zero
<class 'ZeroDivisionError'>
"""
# 如果执行没有出现异常,那么 exception 方法返回 None
print(future2.exception()) # None
# 注意:如果函数执行出现异常了
# 那么调用 result 方法会将异常抛出来
future1.result()
"""
Traceback (most recent call last):
File "...", line 4, in task1
1 / 0
ZeroDivisionError: division by zero
"""
出现异常时,调用 future.set_exception 将异常设置到 future 里面,而 future 有一个 _exception 属性,专门保存设置的异常。当调用 future.exception() 时,也会直接返回 _exception 属性的值。
9、等待所有函数执行完毕
假设我们往线程池提交了很多个函数,如果希望提交的函数都执行完毕之后,主程序才能往下执行,该怎么办呢?其实方案有很多:
第一种:
from concurrent.futures import ThreadPoolExecutor
import time
def task(n):
time.sleep(n)
return f"sleep {n}"
executor = ThreadPoolExecutor()
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
# 这里是不会阻塞的
print("start")
# 遍历所有的 future,并调用其 result 方法
# 这样就会等到所有的函数都执行完毕之后才会往下走
for future in [future1, future2, future3]:
print(future.result())
print("end")
"""
start
sleep 5
sleep 2
sleep 4
end
"""
第二种:
from concurrent.futures import (
ThreadPoolExecutor,
wait
)
import time
def task(n):
time.sleep(n)
return f"sleep {n}"
executor = ThreadPoolExecutor()
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
# return_when 有三个可选参数
# FIRST_COMPLETED:当任意一个任务完成或者取消
# FIRST_EXCEPTION:当任意一个任务出现异常
# 如果都没出现异常等同于ALL_COMPLETED
# ALL_COMPLETED:所有任务都完成,默认是这个值
fs = wait([future1, future2, future3],
return_when="ALL_COMPLETED")
# 此时返回的fs是DoneAndNotDoneFutures类型的namedtuple
# 里面有两个值,一个是done,一个是not_done
print(fs.done)
"""
{<Future at 0x1df1400 state=finished returned str>,
<Future at 0x2f08e48 state=finished returned str>,
<Future at 0x9f7bf60 state=finished returned str>}
"""
print(fs.not_done)
"""
set()
"""
for f in fs.done:
print(f.result())
"""
start
sleep 5
sleep 2
sleep 4
end
"""
第三种:
# 使用上下文管理
with ThreadPoolExecutor() as executor:
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
# 所有函数执行完毕(with语句结束)后才会往下执行
第四种:
executor = ThreadPoolExecutor() future1 = executor.submit(task, 5) future2 = executor.submit(task, 2) future3 = executor.submit(task, 4) # 所有函数执行结束后,才会往下执行 executor.shutdown()
三、小结
如果我们需要启动多线程来执行函数的话,那么不妨使用线程池。每调用一个函数就从池子里面取出一个线程,函数执行完毕就将线程放回到池子里以便其它函数执行。如果池子里面空了,或者说无法创建新的空闲线程,那么接下来的函数就只能处于等待状态了。
最后,concurrent.futures 不仅可以用于实现线程池,还可以用于实现进程池。两者的 API 是一样的:
from concurrent.futures import ProcessPoolExecutor
import time
def task(n):
time.sleep(n)
return f"sleep {n}"
executor = ProcessPoolExecutor()
# Windows 上需要加上这一行
if __name__ == '__main__':
future1 = executor.submit(task, 5)
future2 = executor.submit(task, 2)
future3 = executor.submit(task, 4)
executor.shutdown()
print(future1.result())
print(future2.result())
print(future3.result())
"""
sleep 5
sleep 2
sleep 4
"""
线程池和进程池的 API 是一致的,但工作中很少会创建进程池。
到此这篇关于Python线程池的实现浅析的文章就介绍到这了,更多相关Python线程池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python 常用模块threading和Thread模块之线程池
目录 1. 池的概念 2. 自定义线程池 3. 使用Python内置线程池 4. 池的其他操作 1. 池的概念 主线程: 相当于生产者,只管向线程池提交任务. 并不关心线程池是如何执行任务的. 线程池: 相当于消费者,负责接收任务,并将任务分配到一个空闲的线程中去执行.并不关心是哪一个线程执行的这个任务. 2. 自定义线程池 # -*- coding: utf-8 -*- from threading import Thread from queue import Queue import ti
-
Python实现线程池工作模式的案例详解
目录 01.客户机/服务器通信逻辑 02.数据交换协议 03.服务器主体逻辑 04.服务器会话线程 05.客户机主体逻辑 06.客户机发送数据 07.客户机接收数据 08.客户机界面设计 09.线程池 10.联合测试 11.小结 本文章基于苹果树病虫害预测模型,自定义应用层通信逻辑,设计服务器与客户机.客户机向服务器发送图像数据,服务器回送预测结果.为增强服务器的可靠性与可扩展性,服务器端采用线程池工作模式.为了增强客户机的可操作性,客户机采用PyQt5完成图形化界面设计. 01.客户机/服务器
-
python3线程池ThreadPoolExecutor处理csv文件数据
目录 背景 知识点 拓展 库 流程 实现代码 解释 背景 由于不同乙方对服务商业务接口字段理解不一致,导致线上上千万数据量数据存在问题,为了修复数据,通过 Python 脚本进行修改 知识点 Python3.线程池.pymysql.CSV 文件操作.requests 拓展 当我们程序在使用到线程.进程或协程的时候,以下三个知识点可以先做个基本认知 CPU 密集型.IO 密集型.GIL 全局解释器锁 库 pip3 install requests pip3 install pymysql 流程 实
-
Python线程池的正确使用方法
目录 Python线程池的正确使用 1.为什么要使用线程池呢? 2.线程池怎么用呢? 3.如何非阻塞的获取线程执行的结果 4.线程池的运行策略 Python线程池的正确使用 1.为什么要使用线程池呢? 因为线程执行完任务之后就会被系统销毁,下次再执行任务的时候再进行创建.这种方式在逻辑上没有啥问题.但是系统启动一个新线程的成本是比较高,因为其中涉及与操作系统的交互,操作系统需要给新线程分配资源.打个比方吧!就像软件公司招聘员工干活一样.当有活干时,就招聘一个外包人员干活.当活干完之后就把这个人员
-
Python线程池thread pool创建使用及实例代码分享
目录 前言 一.线程 1.线程介绍 2.线程特性 轻型实体 独立调度和分派的基本单位 可并发执行 4)共享进程资源 二.线程池 三.线程池的设计思路 四.Python线程池构建 1.构建思路 2.实现库功能函数 ThreadPoolExecutor() submit() result() cancel() cancelled() running() as_completed() map() 前言 首先线程和线程池不管在哪个语言里面,理论都是通用的.对于开发来说,解决高并发问题离不开对多个线程处理
-
Python快速实现一个线程池的示例代码
目录 楔子 Future 对象 提交函数自动创建 Future 对象 future.set_result 到底干了什么事情 提交多个函数 使用 map 来提交多个函数 按照顺序等待执行 取消一个函数的执行 函数执行时出现异常 等待所有函数执行完毕 小结 楔子 当有多个 IO 密集型的任务要被处理时,我们自然而然会想到多线程.但如果任务非常多,我们不可能每一个任务都启动一个线程去处理,这个时候最好的办法就是实现一个线程池,至于池子里面的线程数量可以根据业务场景进行设置. 比如我们实现一个有 10
-
Python实现线程池之线程安全队列
目录 一.线程池组成 二.线程安全队列的实现 三.测试逻辑 3.1.测试阻塞逻辑 3.2.测试读写加锁逻辑 本文实例为大家分享了Python实现线程池之线程安全队列的具体代码,供大家参考,具体内容如下 一.线程池组成 一个完整的线程池由下面几部分组成,线程安全队列.任务对象.线程处理对象.线程池对象.其中一个线程安全的队列是实现线程池和任务队列的基础,本节我们通过threading包中的互斥量threading.Lock()和条件变量threading.Condition()来实现一个简单的.读
-
Python爬虫之线程池的使用
一.前言 学到现在,我们可以说已经学习了爬虫的基础知识,如果没有那些奇奇怪怪的反爬虫机制,基本上只要有时间分析,一般的数据都是可以爬取的,那么到了这个时候我们需要考虑的就是爬取的效率了,关于提高爬虫效率,也就是实现异步爬虫,我们可以考虑以下两种方式:一是线程池的使用(也就是实现单进程下的多线程),一是协程的使用(如果没有记错,我所使用的协程模块是从python3.4以后引入的,我写博客时使用的python版本是3.9). 今天我们先来讲讲线程池. 二.同步代码演示 我们先用普通的同步的形式写一段
-
Python 线程池模块之多线程操作代码
1.线程池模块 引入 from concurrent.futures import ThreadPoolExecutor 2.使用线程池 一个简单的线程池使用案例 from concurrent.futures import ThreadPoolExecutor import time pool = ThreadPoolExecutor(10, 'Python') def fun(): time.sleep(1) print(1, end='') if __name__ == '__main__
-
Python线程池的实现浅析
目录 一.序言 二.正文 1.Future 对象 2.提交函数自动创建 Future 对象 3.future.set_result 到底干了什么事情 4.提交多个函数 5.使用 map 来提交多个函数 6.按照顺序等待执行 7.取消一个函数的执行 8.函数执行时出现异常 9.等待所有函数执行完毕 三.小结 雷猴啊,兄弟们!今天来展示一下如何用Python快速实现一个线程池. 一.序言 当有多个 IO 密集型的任务要被处理时,我们自然而然会想到多线程.但如果任务非常多,我们不可能每一个任务都启动一
-
python线程池threadpool使用篇
最近在做一个视频设备管理的项目,设备包括(摄像机,DVR,NVR等),包括设备信息补全,设备状态推送,设备流地址推送等,如果同时导入的设备数量较多,如果使用单线程进行设备检测,那么由于设备数量较多,会带来较大的延时,因此考虑多线程处理此问题. 可以使用python语言自己实现线程池,或者可以使用第三方包threadpool线程池包,本主题主要介绍threadpool的使用以及其里面的具体实现. 1.安装 使用安装: pip installthreadpool 2.使用 (1)引入threadpo
-
python线程池threadpool实现篇
本文为大家分享了threadpool线程池中所有的操作,供大家参考,具体内容如下 首先介绍一下自己使用到的名词: 工作线程(worker):创建线程池时,按照指定的线程数量,创建工作线程,等待从任务队列中get任务: 任务(requests):即工作线程处理的任务,任务可能成千上万个,但是工作线程只有少数.任务通过 makeRequests来创建 任务队列(request_queue):存放任务的队列,使用了queue实现的.工作线程从任务队列中get任务进行处理: 任务处理函
-
Python 线程池用法简单示例
本文实例讲述了Python 线程池用法.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #! python3 ''' Created on 2019-10-2 @author: Administrator ''' from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random def task(n): print('%s is runing' %
-
Python线程池模块ThreadPoolExecutor用法分析
本文实例讲述了Python线程池模块ThreadPoolExecutor用法.分享给大家供大家参考,具体如下: python3内置的有Threadingpool和ThreadPoolExecutor模块,两个都可以做线程池,当然ThreadPoolExecutor会更好用一些,而且也有ProcessPoolExecutor进程池模块,使用方法基本一致. 首先导入模块 from concurrent.futures import ThreadPoolExecutor 使用方法很简单,最常用的可能就
-
python线程池如何使用
线程池的使用 线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和ProcessPoolExecutor,其中 ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池. 如果使用线程池/进程池来管理并发编程,那么只要将相应的 task 函数提交给线程池/进程池,剩下的事情就由线程池/进程池来搞定. Exectuor 提供了如下常用方
-
实例代码讲解Python 线程池
大家都知道当任务过多,任务量过大时如果想提高效率的一个最简单的方法就是用多线程去处理,比如爬取上万个网页中的特定数据,以及将爬取数据和清洗数据的工作交给不同的线程去处理,也就是生产者消费者模式,都是典型的多线程使用场景. 那是不是意味着线程数量越多,程序的执行效率就越快呢. 显然不是.线程也是一个对象,是需要占用资源的,线程数量过多的话肯定会消耗过多的资源,同时线程间的上下文切换也是一笔不小的开销,所以有时候开辟过多的线程不但不会提高程序的执行效率,反而会适得其反使程序变慢,得不偿失. 所以,如
-
python线程池 ThreadPoolExecutor 的用法示例
前言 从Python3.2开始,标准库为我们提供了 concurrent.futures 模块,它提供了 ThreadPoolExecutor (线程池)和ProcessPoolExecutor (进程池)两个类. 相比 threading 等模块,该模块通过 submit 返回的是一个 future 对象,它是一个未来可期的对象,通过它可以获悉线程的状态主线程(或进程)中可以获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值: 主线程可以获取某一个线程(或者任务的)的状态,以及返
-
python线程池的四种好处总结
1.使用好处 提高性能:由于减去了大量新建终止线程的费用,重用了线程资源: 适用场景:适用于处理大量突发请求或需要大量线程完成任务,但实际任务处理时间短. 防御功能:可以有效避免系统因线程过多而导致系统负载过大而相应变慢的问题. 代码优势:使用线程池的语法比创建自己的线程更简单. 2.实例 """ @file : 004-线程池的使用.py @author : xiaolu @email : luxiaonlp@163.com @time : 2021-02-01 "