PyTorch开源图像分类工具箱MMClassification详解
MMClassification是一个基于PyTorch的开源图像分类工具箱,是OpenMMLab项目的一部分,源码传送门,最新发布版本为v0.23.2,License为Apache-2.0。它支持在Windows、Linux和Mac上运行。
1.安装:使用conda安装
(1).创建openmmlab虚拟环境:
conda create -n openmmlab python=3.8
conda activate openmmlab
(2).安装PyTorch:这里PyTorch使用1.11.0版本,CUDA使用10.2版本,此CUDA版本对PyTorch各版本都支持
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=10.2 -c pytorch
(3).安装MMCV:MMCV有两个版本,这里安装带CUDA的mmcv-full
1).mmcv-full: 完整版,包含所有的特性以及丰富的开箱即用的CUDA算子,安装此版本需要较长时间。
2).mmcv:精简版,不包含CUDA算子但包含其余所有特性和功能,类似MMCV 1.0之前的版本。
不要在同一个环境中安装两个版本,否则可能会遇到类似ModuleNotFound的错误。在安装一个版本之前,需要先卸载另一个:
pip uninstall mmcv-full
pip uninstall mmcv
注意:这里mmcv-full使用1.5.3版本。CUDA版本和PyTorch版本与安装PyTorch时保持一致
pip install mmcv-full==1.5.3 -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.11.0/index.html
(4).安装MMClassification:没有通过源码安装
pip install mmcls==0.23.2
2.测试:论文:《Very Deep Convolutional Networks for Large-Scale Image Recognition》
ImageNet数据集:是根据WordNet层次结构组织的图像数据集,ImageNet_1000_label中给出了1000类别中label对应的id值。
(1).下载模型(checkpoint):
def download_checkpoint(path, name, url):
if os.path.isfile(path+name) == False:
print("checkpoint(model) file does not exist, now download ...")
subprocess.run(["wget", "-P", path, url])
path = "../../data/model/"
checkpoint = "vgg19_batch256_imagenet_20210208-e6920e4a.pth"
url = "https://download.openmmlab.com/mmclassification/v0/vgg/vgg19_batch256_imagenet_20210208-e6920e4a.pth"
download_checkpoint(path, checkpoint, url)
(2).根据配置文件和checkpoint文件构建模型:
config = "../../src/mmclassification/configs/vgg/vgg19_8xb32_in1k.py"
model = init_model(config, path+checkpoint, device)
(3).准备测试图像:原始图像来自网络
image_path = "../../data/image/" image_name = "6.jpg"

(4).进行推理:
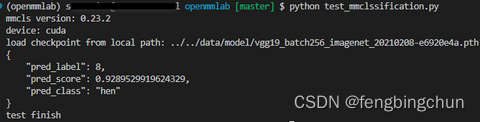
result = inference_model(model, image) print(mmcv.dump(result, file_format='json', indent=4)) # show_result_pyplot(model, image, result)
执行结果如下图所示:
GitHub传送门
到此这篇关于PyTorch开源图像分类工具箱MMClassification详解的文章就介绍到这了,更多相关PyTorch MMClassification内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

如何使用Pytorch完成图像分类任务详解
目录 概述: 一. 数据准备 二.定义一个卷积神经网络 三.完整代码如下: 总结 概述: 本文将通过组织自己的训练数据,使用Pytorch深度学习框架来训练自己的模型,最终实现自己的图像分类!本篇文章以识别阳台为例子,进行讲述. 一. 数据准备 深度学习的基础就是数据,完成图像分类,当然数据也必不可少.先使用爬虫爬取阳台图片1200张以及非阳台图片1200张,图片的名字从0.jpg一直编到2400.jpg,把爬取的图片放置在同一个文件夹中命名为image(如下图1所示). 图1 针对百度图片的爬
-
python深度学习tensorflow训练好的模型进行图像分类
目录 正文 随机找一张图片 读取图片进行分类识别 最后输出 正文 谷歌在大型图像数据库ImageNet上训练好了一个Inception-v3模型,这个模型我们可以直接用来进来图像分类. 下载链接: https://pan.baidu.com/s/1XGfwYer5pIEDkpM3nM6o2A 提取码: hu66 下载完解压后,得到几个文件: 其中 classify_image_graph_def.pb 文件就是训练好的Inception-v3模型. imagenet_synset_to_huma
-
Python Pytorch深度学习之图像分类器
目录 一.简介 二.数据集 三.训练一个图像分类器 1.导入package吧 2.归一化处理+贴标签吧 3.先来康康训练集中的照片吧 4.定义一个神经网络吧 5.定义一个损失函数和优化器吧 6.训练网络吧 7.在测试集上测试一下网络吧 8.分别查看一下训练效果吧 总结 一.简介 通常,当处理图像.文本.语音或视频数据时,可以使用标准Python将数据加载到numpy数组格式,然后将这个数组转换成torch.*Tensor 对于图像,可以用Pillow,OpenCV 对于语音,可以用scipy,l
-
Pytorch深度学习之实现病虫害图像分类
目录 一.pytorch框架 1.1.概念 1.2.机器学习与深度学习的区别 1.3.在python中导入pytorch成功截图 二.数据集 三.代码复现 3.1.导入第三方库 3.2.CNN代码 3.3.测试代码 四.训练结果 4.1.LOSS损失函数 4.2. ACC 4.3.单张图片识别准确率 四.小结 一.pytorch框架 1.1.概念 PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序. 2017年1月,由Facebook人工智能研究院(FA
-
Python 如何给图像分类(图像识别模型构建)
在日常生活中总是有给图像分类的场景,比如垃圾分类.不同场景的图像分类等:今天的文章主要是基于图像识别场景进行模型构建.图像识别是通过 Python深度学习来进行模型训练,再使用模型对上传的电子表单进行自动审核与比对后反馈相应的结果.主要是利用 Python Torchvision 来构造模型,Torchvision 服务于Pytorch 深度学习框架,主要是用来生成图片.视频数据集以及训练模型. 模型构建 构建模型为了直观,需要使用 Jupyter notebook 进行模型的构建, 导入所需包
-
Python深度学习pytorch实现图像分类数据集
目录 读取数据集 读取小批量 整合所有组件 目前广泛使用的图像分类数据集之一是MNIST数据集.如今,MNIST数据集更像是一个健全的检查,而不是一个基准. 为了提高难度,我们将在接下来的章节中讨论在2017年发布的性质相似但相对复杂的Fashion-MNIST数据集. import torch import torchvision from torch.utils import data from torchvision import transforms from d2l import to
-
Tensorflow加载模型实现图像分类识别流程详解
目录 前言 正文 VGG19网络介绍 总结 前言 深度学习框架在市面上有很多.比如Theano.Caffe.CNTK.MXnet .Tensorflow等.今天讲解的就是主角Tensorflow.Tensorflow的前身是Google大脑项目的一个分布式机器学习训练框架,它是一个十分基础且集成度很高的系统,它的目标就是为研究超大型规模的视觉项目,后面延申到各个领域.Tensorflow 在2015年正式开源,开源的一个月内就收获到1w多的starts,这足以说明Tensorflow的优越性以及
-
PyTorch开源图像分类工具箱MMClassification详解
MMClassification是一个基于PyTorch的开源图像分类工具箱,是OpenMMLab项目的一部分,源码传送门,最新发布版本为v0.23.2,License为Apache-2.0.它支持在Windows.Linux和Mac上运行. 1.安装:使用conda安装 (1).创建openmmlab虚拟环境: conda create -n openmmlab python=3.8conda activate openmmlab (2).安装PyTorch:这里PyTorch使用1.11.0
-
关于PyTorch 自动求导机制详解
自动求导机制 从后向中排除子图 每个变量都有两个标志:requires_grad和volatile.它们都允许从梯度计算中精细地排除子图,并可以提高效率. requires_grad 如果有一个单一的输入操作需要梯度,它的输出也需要梯度.相反,只有所有输入都不需要梯度,输出才不需要.如果其中所有的变量都不需要梯度进行,后向计算不会在子图中执行. >>> x = Variable(torch.randn(5, 5)) >>> y = Variable(torch.rand
-
对Pytorch神经网络初始化kaiming分布详解
函数的增益值 torch.nn.init.calculate_gain(nonlinearity, param=None) 提供了对非线性函数增益值的计算. 增益值gain是一个比例值,来调控输入数量级和输出数量级之间的关系. fan_in和fan_out pytorch计算fan_in和fan_out的源码 def _calculate_fan_in_and_fan_out(tensor): dimensions = tensor.ndimension() if dimensions < 2:
-
基于python及pytorch中乘法的使用详解
numpy中的乘法 A = np.array([[1, 2, 3], [2, 3, 4]]) B = np.array([[1, 0, 1], [2, 1, -1]]) C = np.array([[1, 0], [0, 1], [-1, 0]]) A * B : # 对应位置相乘 np.array([[ 1, 0, 3], [ 4, 3, -4]]) A.dot(B) : # 矩阵乘法 ValueError: shapes (2,3) and (2,3) not aligned: 3 (dim
-
PyTorch中permute的用法详解
permute(dims) 将tensor的维度换位. 参数:参数是一系列的整数,代表原来张量的维度.比如三维就有0,1,2这些dimension. 例: import torch import numpy as np a=np.array([[[1,2,3],[4,5,6]]]) unpermuted=torch.tensor(a) print(unpermuted.size()) # --> torch.Size([1, 2, 3]) permuted=unpermuted.permute(
-
Pytorch Tensor基本数学运算详解
1. 加法运算 示例代码: import torch # 这两个Tensor加减乘除会对b自动进行Broadcasting a = torch.rand(3, 4) b = torch.rand(4) c1 = a + b c2 = torch.add(a, b) print(c1.shape, c2.shape) print(torch.all(torch.eq(c1, c2))) 输出结果: torch.Size([3, 4]) torch.Size([3, 4]) tensor(1, dt
-
pytorch中的自定义数据处理详解
pytorch在数据中采用Dataset的数据保存方式,需要继承data.Dataset类,如果需要自己处理数据的话,需要实现两个基本方法. :.getitem:返回一条数据或者一个样本,obj[index] = obj.getitem(index). :.len:返回样本的数量 . len(obj) = obj.len(). Dataset 在data里,调用的时候使用 from torch.utils import data import os from PIL import Image 数
-
Pytorch 中retain_graph的用法详解
用法分析 在查看SRGAN源码时有如下损失函数,其中设置了retain_graph=True,其作用是什么? ############################ # (1) Update D network: maximize D(x)-1-D(G(z)) ########################### real_img = Variable(target) if torch.cuda.is_available(): real_img = real_img.cuda() z = V
-
PyTorch中的Variable变量详解
一.了解Variable 顾名思义,Variable就是 变量 的意思.实质上也就是可以变化的量,区别于int变量,它是一种可以变化的变量,这正好就符合了反向传播,参数更新的属性. 具体来说,在pytorch中的Variable就是一个存放会变化值的地理位置,里面的值会不停发生片花,就像一个装鸡蛋的篮子,鸡蛋数会不断发生变化.那谁是里面的鸡蛋呢,自然就是pytorch中的tensor了.(也就是说,pytorch都是有tensor计算的,而tensor里面的参数都是Variable的形式).如果