mysql常用函数之group_concat()、group by、count()、case when then的使用
目录
- 场景:
- 一、行转列函数 group_concat(arg)
- 二、分组 group by、count()、sum() 函数的组合使用
- 三、count() 配合 case when then 的使用
场景:
在mysql的关联查询或子查询中,函数 group_concat(arg) 可以合并多行的某列(或多列)数据为一行,默认以逗号分隔。以及分组函数和统计函数的组合使用
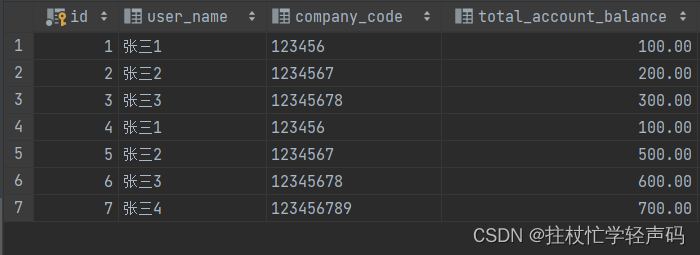
测试数据准备:
一、行转列函数 group_concat(arg)
1、单列合并,默认以逗号分隔
select
group_concat(ttop.user_name) as testStr
from t_table_one_parent ttop;
输出:
张三1,张三2,张三3,张三1,张三2,张三3,张三4
2、单列合并,指定冒号分隔符
select
group_concat(ttop.user_name separator ';') as testStr
from t_table_one_parent ttop;
输出:
张三1;张三2;张三3;张三1;张三2;张三3;张三4
3、单列合并,并去重
select
group_concat(distinct ttop.user_name separator ';') as testStr
from t_table_one_parent ttop;
输出:
张三1;张三2;张三3;张三4
4、多列拼接合并
select
group_concat(distinct ttop.user_name, ttop.company_code separator ';') as testStr
from t_table_one_parent ttop;
输出:
张三1123456;张三21234567;张三312345678;张三4123456789
5、多列拼接合并,列和列之间指定分隔符
select
group_concat(distinct ttop.user_name, ',', ttop.company_code separator ';') as testStr
from t_table_one_parent ttop;
输出:
张三1,123456;张三2,1234567;张三3,12345678;张三4,123456789
小结:
1、group_concat() 函数默认合并后以逗号分隔,也可以自定义分隔符
2、group_concat() 函数可以多列合并,列和列之间可以自定义分隔符
3、group_concat() 函数可以使用 distinct 进行去重合并
二、分组 group by、count()、sum() 函数的组合使用
1、分组和统计
select
user_name as userName,
count(user_name) as ctUserName
from t_table_one_parent ttop group by user_name;
输出: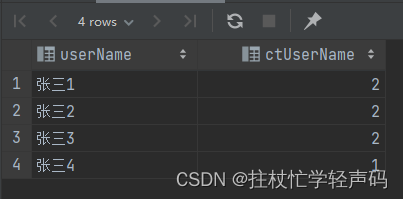
2、分组和求和
select
user_name as userName,
count(user_name) as ctUserName,
sum(total_account_balance) as sumTab
from t_table_one_parent ttop group by user_name;
输出:

小结:
1、group by 分组可以配合 count() 统计函数综合使用,输出每组中的数量
2、group by 分组可以配合 sum() 求和函数综合使用,输出每组中的数字的和
3、group by 分组可以配合 count()、sum() 一起使用,输出每组中的数量以及和
三、count() 配合 case when then 的使用
脚本备份:
create table if not exists t_department_info
(
id bigint not null primary key auto_increment comment '主键id',
dept_name varchar(50) not null comment '部门名称',
dept_director varchar(20) not null comment '部门主管',
create_by bigint comment '创建人Id',
create_date datetime not null default now() comment '创建时间',
update_by bigint comment '更新人Id',
update_date datetime not null default now() on update now() comment '更新时间'
) engine = InnoDB
auto_increment = 1
default charset = utf8 comment '部门信息表';
create table if not exists t_person_info
(
id bigint not null primary key auto_increment comment '主键id',
person_name varchar(10) not null comment '人员名称',
id_number varchar(50) not null comment '省份证号',
gender varchar(5) not null comment '性别,M男、F女',
induction_date datetime null comment '入职日期',
quit_date datetime null comment '离职日期',
if_on_job tinyint(1) default 1 comment '是否在职状态,0-否,1-是',
dept_id bigint null comment '部门Id',
create_by bigint comment '创建人Id',
create_date datetime not null default now() comment '创建时间',
update_by bigint comment '更新人Id',
update_date datetime not null default now() on update now() comment '更新时间'
) engine = InnoDB
auto_increment = 1
default charset = utf8 comment '人员资料信息表';
-- 写入数据
INSERT INTO any_case.t_department_info (id, dept_name, dept_director, create_by, create_date, update_by, update_date) VALUES (1, '研发部', '张三', 1, '2022-12-22 16:38:10', null, '2022-12-22 16:38:10');
INSERT INTO any_case.t_department_info (id, dept_name, dept_director, create_by, create_date, update_by, update_date) VALUES (2, '测试部', '张三', 1, '2022-12-22 16:38:10', null, '2022-12-22 16:38:10');
INSERT INTO any_case.t_department_info (id, dept_name, dept_director, create_by, create_date, update_by, update_date) VALUES (3, '运维部', '李四', 1, '2022-12-22 16:38:10', null, '2022-12-22 16:38:10');
INSERT INTO any_case.t_person_info (id, person_name, id_number, gender, induction_date, quit_date, if_on_job, dept_id, create_by, create_date, update_by, update_date) VALUES (1, '张三', '123456789987654321', 'M', '2022-11-23 00:40:35', null, 1, 1, 1, '2022-12-22 16:40:48', null, '2022-12-22 16:40:48');
INSERT INTO any_case.t_person_info (id, person_name, id_number, gender, induction_date, quit_date, if_on_job, dept_id, create_by, create_date, update_by, update_date) VALUES (2, '李四', '123456789987654321', 'F', '2022-11-23 00:40:35', '2022-12-23 00:54:47', 0, 1, 1, '2022-12-22 16:40:48', null, '2022-12-22 16:54:40');
INSERT INTO any_case.t_person_info (id, person_name, id_number, gender, induction_date, quit_date, if_on_job, dept_id, create_by, create_date, update_by, update_date) VALUES (3, '王五', '123456789987654321', 'M', '2022-11-23 00:40:35', '2022-11-30 00:54:54', 0, 1, 1, '2022-12-22 16:40:48', null, '2022-12-23 02:13:29');
INSERT INTO any_case.t_person_info (id, person_name, id_number, gender, induction_date, quit_date, if_on_job, dept_id, create_by, create_date, update_by, update_date) VALUES (4, '赵六', '123456789987654321', 'F', '2022-11-23 00:40:35', null, 1, 2, 1, '2022-12-22 16:40:48', null, '2022-12-22 16:40:48');
INSERT INTO any_case.t_person_info (id, person_name, id_number, gender, induction_date, quit_date, if_on_job, dept_id, create_by, create_date, update_by, update_date) VALUES (5, '李七', '123456789987654321', 'M', '2022-11-23 00:40:35', null, 1, 2, 1, '2022-12-22 16:40:48', null, '2022-12-22 16:40:48');
INSERT INTO any_case.t_person_info (id, person_name, id_number, gender, induction_date, quit_date, if_on_job, dept_id, create_by, create_date, update_by, update_date) VALUES (6, '郑八', '123456789987654321', 'F', '2022-11-23 00:40:35', null, 1, 1, 1, '2022-12-22 16:41:17', null, '2022-12-22 17:00:22');
1、主从表关联查询统计示例脚本
select tdi.dept_name,
tdi.dept_director
,count(tpi.id) as allPersonNum -- 全部人数
,count(case when tpi.if_on_job = 1 then tpi.id end) as ifOnJobNum -- 在职全部人数
,count(case when tpi.if_on_job = 1 and tpi.gender = 'M' then tpi.id end) as ifOnJobMNum -- 在职男性人数
,count(case when tpi.if_on_job = 1 and tpi.gender = 'F' then tpi.id end) as ifOnJobFNum -- 在职女性人数
,count(case when tpi.if_on_job = 0 then tpi.id end) as quitNum -- 离职总人数
,count(case when tpi.if_on_job = 0 and date_format(tpi.quit_date, '%Y-%m') = date_format(now(), '%Y-%m') then tpi.id end) as quitNumThisMonth -- 本月离职人数
from t_department_info tdi
left join t_person_info tpi on tpi.dept_id = tdi.id
#支持主表和从表过滤
where tdi.dept_director like '%张%'
and (tpi.if_on_job = 0 and date_format(tpi.quit_date, '%Y-%m') = date_format(now(), '%Y-%m')) > 0
and tpi.person_name like '%李%'
group by tdi.dept_name, tdi.dept_director;
可见主与从表关系为一对多,而查询列中的 count() 中根据从表中的条件来判断是否统计入该条数据,符合条件的话返回给 count() 统计依据列,不符合条件返回给 count() 统计依据为 null(默认null不统计)
2、这样写的好处比关联多个 left join 对象这种方式的查询效率要快很多,而且还简洁明了不混乱
到此这篇关于mysql常用函数之group_concat()、group by、count()、case when then的使用的文章就介绍到这了,更多相关mysql group_concat()、group by、count()、case when then内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈MySQL中group_concat()函数的排序方法
group_concat()函数的参数是可以直接使用order by排序的.666.. 下面通过例子来说明,首先看下面的t1表. 比如,我们要查看每个人的多个分数,将该人对应的多个分数显示在一起,分数要从高到底排序. 可以这样写: SELECT username,GROUP_CONCAT(score ORDER BY score DESC) AS myScore FROM t1 GROUP BY username; 效果如下: 以上这篇浅谈MySQL中group_concat()函数的排序方法就
-
Mysql的GROUP_CONCAT()函数使用方法
语法: GROUP_CONCAT([DISTINCT] expr [,expr ...][ORDER BY {unsigned_integer | col_name | expr}[ASC | DESC] [,col_name ...]][SEPARATOR str_val]) 下面演示一下这个函数,先建立一个学生选课表student_courses,并填充一些测试数据. SQL代码 复制代码 代码如下: CREATE TABLE student_courses ( stude
-
MySQL group by和order by如何一起使用
假设有一个表:reward(奖励表),表结构如下: CREATE TABLE test.reward ( id int(11) NOT NULL AUTO_INCREMENT, uid int(11) NOT NULL COMMENT '用户uid', money decimal(10, 2) NOT NULL COMMENT '奖励金额', datatime datetime NOT NULL COMMENT '时间', PRIMARY KEY (id) ) ENGINE = INNODB A
-
mysql获取group by总记录行数的方法
本文实例讲述了mysql获取group by总记录行数的方法,分享给大家供大家参考.具体方法分析如下: 一般来说,mysql获取group by内部可以获取到某字段的记录分组统计总数,而无法统计出分组的记录数. mysql中可以使用SQL_CALC_FOUND_ROWS来获取查询的行数,在很多分页的程序中都这样写: 复制代码 代码如下: SELECT COUNT(*) from `table` WHERE ......; 查出符合条件的记录总数: 复制代码 代码如下: SELECT * FROM
-
mysql中group by与having合用注意事项分享
group by函数应该的使用应该是SELECT 列表中指定的每一列也必须出现在 GROUP BY 子句中,除非这列是用于聚合函数,但是今天帮同事调试一个mysql中的group by函数,让我大跌眼镜,当时感觉不可思议,然后回来做了个简化版试验,试验过程如下: mysql表结构 复制代码 代码如下: mysql> desc t;+---+----–+--+-–+---+---+| Field | Type | Null | Key | Default | Extra |+---+----–+-
-
mysql group_concat()函数用法总结
本文实例讲述了mysql group_concat()函数用法.分享给大家供大家参考,具体如下: group_concat(),手册上说明:该函数返回带有来自一个组的连接的非NULL值的字符串结果.比较抽象,难以理解. 通俗点理解,其实是这样的:group_concat()会计算哪些行属于同一组,将属于同一组的列显示出来.要返回哪些列,由函数参数(就是字段名)决定.分组必须有个标准,就是根据group by指定的列进行分组. group_concat函数应该是在内部执行了group by语句,这
-
mysql使用GROUP BY分组实现取前N条记录的方法
本文实例讲述了mysql使用GROUP BY分组实现取前N条记录的方法.分享给大家供大家参考,具体如下: MySQL中GROUP BY分组取前N条记录实现 mysql分组,取记录 GROUP BY之后如何取每组的前两位下面我来讲述mysql中GROUP BY分组取前N条记录实现方法. 这是测试表(也不知道怎么想的,当时表名直接敲了个aa,汗~~~~): 结果: 方法一: 复制代码 代码如下: SELECT a.id,a.SName,a.ClsNo,a.Score FROM aa a LEFT J
-
深入解析mysql中order by与group by的顺序问题
mysql 中order by 与group by的顺序是:selectfromwheregroup byorder by注意:group by 比order by先执行,order by不会对group by 内部进行排序,如果group by后只有一条记录,那么order by 将无效.要查出group by中最大的或最小的某一字段使用 max或min函数.例:select sum(click_num) as totalnum,max(update_time) as update_time,
-
MySQL优化GROUP BY方案
执行GROUP BY子句的最一般的方法:先扫描整个表,然后创建一个新的临时表,表中每个组的所有行应为连续的,最后使用该临时表来找到组并应用聚集函数(如果有聚集函数).在某些情况中,MySQL通过访问索引就可以得到结果,而不用创建临时表.此类查询的 EXPLAIN 输出显示 Extra列的值为 Using index for group-by. 一. 松散索引扫描 1.满足条件 查询针对一个表. GROUP BY 使用索引的最左前缀. 只可以使用MIN()和MAX()聚集函数,并且它们均指向相
-
mysql筛选GROUP BY多个字段组合时的用法分享
想实现这样一种效果如果使用group by一个条件的话,得到的结果会少了很多,如何多个条件组合筛选呢 复制代码 代码如下: group by fielda,fieldb,fieldc... 循环的时候可以通过判断后一个跟前面一个是否相同来分组,一个示例 复制代码 代码如下: $result = mysql_query("SELECT groups,name,goods FROM table GROUP BY groups,name ORDER BY name"); $arr = arr
-
MySQL基于group_concat()函数合并多行数据
一个很有用的函数 group_concat(),手册上说明:该函数返回带有来自一个组的连接的非NULL值的字符串结果. 通俗点理解,其实是这样的:group_concat()会计算哪些行属于同一组,将属于同一组的列合并显示出来.要返回哪些列,由函数参数(就是字段名)决定.分组必须有个标准,就是根据group by指定的列进行分组. 合并的字段分隔符默认为逗号,可通过参数separator指定. 比如在student表中,有如下5条数据: 有要求如下:"小明"的两行成绩可以放在一行展示,
-
mysql利用group_concat()合并多行数据到一行
假设两个表a,b,b中通过字段id与a表关联,a表与b表为一对多的关系.假设b表中存在一字段name,现需要查询a表中的记录,同时获取存储在b表中的name信息,按照常规查询,b表中有多少记录,则会显示多少行,如果需要只显示a表记录行数,则需要把查询name字段得到的多行记录进行合并,可以通过程序实现,但也可直接在sql层完成. 方法: 利用group_concat()方法,参数为需要合并的字段,合并的字段分隔符默认为逗号,可通过参数separator指定,该方法往往配合group by 一起使