详解lodash中的cloneDeep使用细节
目录
- 正文
- 支持的数据类型
- cloneDeepWith
- 拷贝算法介绍
- structuredClone VS cloneDeep
- 循环引用处理方法
- 总结
正文
lodash中的cloneDeep是一个使用频率比较高的方法,然而你真的理解其中的细节处理吗?如果下面几个问题你还有疑惑那么本文对你或多或少有些帮助。
- cloneDeep中支持拷贝函数、Error对象、DOM节点以及WeakMap对象吗?
- cloneDeep中使用了哪种算法呢?
- 浏览器中提供的实现深拷贝的方式除了JSON.parse(JSON.stringify()),还有其他方法吗?
- 当遇到循环引用时,如何进行深拷贝操作来避免出现栈溢出呢?
当上面这些问题你还有疑惑时,可能会在一些比较少见的场景中遇到一些出乎意料的问题,希望本文能够对你有所帮助。
支持的数据类型
lodash中支持了很多种的数据类型,包括 arrays、array buffers、 booleans、 date objects、maps、 numbers、Object、regexes、sets、 strings、symbols、typed arrays,以及包括arguments这个参数(不过拷贝后会丢失一些信息)。
但是由于一些原因,还有一些类型,lodash中默认时不支持的。至于error objects、functions、DOM nodes、以及WeakMaps默认是不支持的,lodash默认会返回一个控对象,所以如果数据中存在这些数据类型时需要特别关注一下,拷贝之后就无法获取对应的数据了。
cloneDeepWith
如果拷贝的数据中存在不支持的数据类型时,我们改怎么办呢?
lodash为我们提供了另外一个方法,与cloneDeep比较类似,只不过我们可以在这个方法中传入一个自定义函数,当遇到不支持的数据类型时,我们可以根据场景来定义自己的深拷贝的实现逻辑。比如说当拷贝函数时,返回函数本身等。
lodash官网 有着比较详细的例子,也可以参考一下。
拷贝算法介绍
lodash作为一个使用非常广泛的库,在拷贝算法上使用了structured clone algorithm,这个算法细节描述可以参考 html.spec.whatwg.org/multipage/s… ,与目前浏览器中的structuredClone方法实现采用的是一样的算法,在其他一些场景中大家进行拷贝方式的实现基本是一致的,这也保证了使用cloneDeep方法具有良好的兼容性。
structuredClone VS cloneDeep
目前浏览器中提供了structuredClone 方法来处理需要深拷贝的场景,那我们还需要使用lodash提供的cloneDeep方法吗?从目前来看这个API在web场景的兼容性:

目前看来兼容性还不是特别高,大家可以根据自己的场景来进行选用,毕竟使用lodash会增加包体积大小,对于一些追求极致性能的场景包体积肯定越小越好。
循环引用处理方法
在处理拷贝过程中一般都会遇到一个比较棘手的问题:循环引用, 看下面这段简单的代码:
const objb = {
b: null
};
const obja = {
a: objb
};
objb.b = obja;
console.log(objb);
在控制台中输出objb对象,展开其属性,我们可以看到这个结果:

可以看到objb对象的属性可以无限展开下去,这样就形成了循环引用。形成循环引用的原因就是,objb.b引用了obja对象;但是obja.a属性又引用了objb对象。

如果我们进行不断的拷贝而不做针对循环引用的处理,必然会出现这个错误:

那么lodash中是如何处理这个问题的呢?
其实lodash中处理循环引用的方法非常简单清晰,下面这段代码是处理循环引用的核心代码。可以看出lodash中主要通过缓存每个值对应的拷贝结果来解决循环引用的问题。

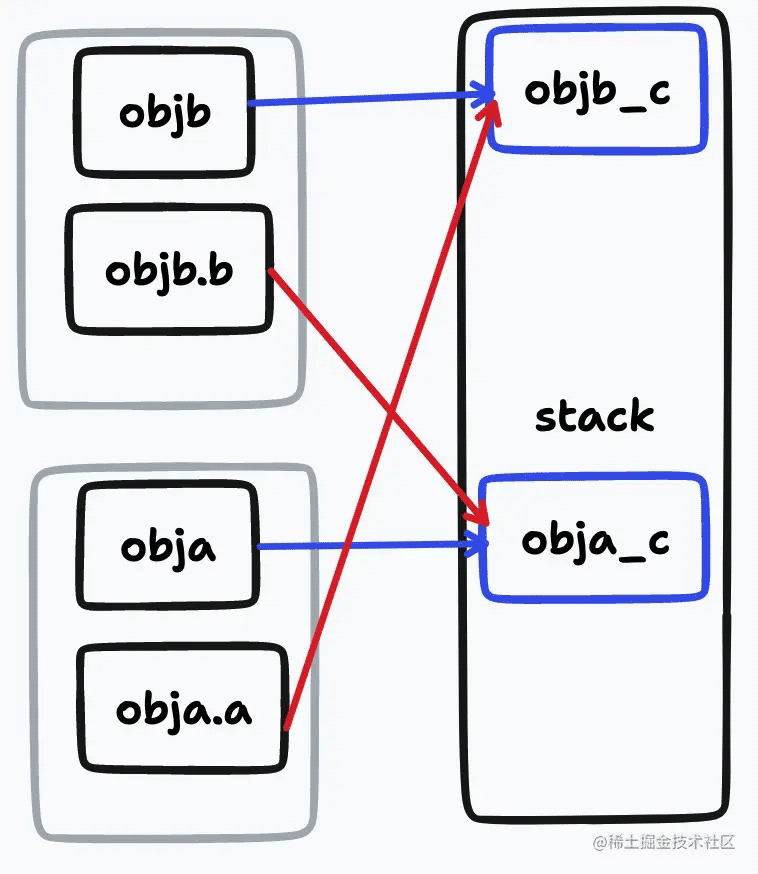
针对上面的这个存在循环引用的对象,我们可以来按步骤进行分析一下cloneDeep(objb)时是如何解决循环引用的:
- 处理objb对象,stack.get(objb)不存在,所以将代表objb的拷贝结果result放到stack中,然后逐个处理objb上的属性
- 处理objb中的b属性,stack.get(obj.b)其实也就是stack.get(obja),此时stacka也在stack中,因此也将代表obja的拷贝结果result放置到stack中,然后逐个处理obja上的属性
- 处理obja上的a属性,stack.get(obja.a)其实也就是stack.get(objb),经过前两步的处理,我们只在此时,objb已经存在stack中了,stack.get(objb)返回一个拷贝后的对象
拷贝过程结束,返回拷贝的结果 可以结合下面这幅图来进行理解:
总结
深拷贝看起来简单,但是实现中有很多细节需要注意,lodash这类工具库确实帮我们解决了不少问题,感谢开源!
以上就是详解lodash中的cloneDeep使用细节的详细内容,更多关于lodash cloneDeep使用的资料请关注我们其它相关文章!
相关推荐
-
lodash内部方法getData和setData实例解析
目录 getData metaMap WeakMap noop getData源码实现 setData baseSetData metaMap shortOut setData源码实现 小结 getData getData方法主要是获取方法的元数据metadata. getData实现上借助metaMap和noop两个内部方法. metaMap metaMap方法获取当前环境下的WeakMap对象. import WeakMap from './_WeakMap.js'; var metaMap
-

手写Spirit防抖函数underscore和节流函数lodash
目录 前言 防抖函数和节流函数的区别 防抖函数的实现 基本实现 立即执行 取消功能 返回结果 节流函数的实现 基本实现 leading实现 trailing实现 取消功能和返回结果 前言 防抖函数和节流函数,无论是写业务的时候还是面试的时候,想必大家已经听过很多次了吧.但是大家在用到的时候,有了解过他们之间的区别嘛,他们是如何实现的呢?还是说只是简单的调用下像lodash和underscore这种第三方库提供给我们的节流和防抖函数呢? 防抖函数和节流函数的区别 防抖函数:是指触发了一个事件,在规
-
lodash里to系列之将数据转换成数字类型实现示例
目录 正文 toNumber toFinit toInteger toSafeInteger 小结 正文 在lodash里的to系列里,将目标数据转换为数字类型的数据的方法,包括了toNumber方法.toFinit方法.toInteger方法,toSafeInteger方法,下面来看看各个方法的使用和实现. toNumber toNumber方法主要是将参数value转换为一个数字类型. 使用如下: toNumber(3.2) // => 3.2 toNumber(Number.MIN_VAL
-
lodash内部方法getFuncName及setToString剖析详解
目录 getFuncName realNames setToString baseSetToString constant defineProperty identity shortOut 小结 getFuncName getFuncName方法主要是获取参数func的name属性. 实现上主要通过函数的name属性去获取,同时也兼容原型链上属性判断. 源码如下: import realNames from './_realNames.js'; var objectProto = Object.
-
lodash里的toLength和toPairs方法详解
目录 正文 toLength toPairs createToPairs baseToParis arrayMap mapToArray setToPairs 小结 正文 本篇章我们将认识lodash里的toLength方法和toPairs方法实现,同时在实现toPairs方法的过程中也能了解到其他封装的内部方法的实现. toLength toLength方法主要是将参数value转换为用作类数组对象的长度整数. 使用如下: toLength(3.2) // => 3 toLength(Numb
-
详解lodash中的cloneDeep使用细节
目录 正文 支持的数据类型 cloneDeepWith 拷贝算法介绍 structuredClone VS cloneDeep 循环引用处理方法 总结 正文 lodash中的cloneDeep是一个使用频率比较高的方法,然而你真的理解其中的细节处理吗?如果下面几个问题你还有疑惑那么本文对你或多或少有些帮助. cloneDeep中支持拷贝函数.Error对象.DOM节点以及WeakMap对象吗? cloneDeep中使用了哪种算法呢? 浏览器中提供的实现深拷贝的方式除了JSON.parse(JSO
-
详解java中保持compareTo和equals同步
详解java中保持compareTo和equals同步 摘要 : 介绍重写equlas()和comparable接口,两者进行不相同的判断.从而使两者的对应的list.indexOf()与 Collections.binarySearch()得到的不一样. 在Java中我们常使用Comparable接口来实现排序,其中compareTo是实现该接口方法.我们知道compareTo返回0表示两个对象相等,返回正数表示大于,返回负数表示小于.同时我们也知道equals也可以判断两个对象是否相等,那么
-
详解Javascript 中的 class、构造函数、工厂函数
到了ES6时代,我们创建对象的手段又增加了,在不同的场景下我们可以选择不同的方法来建立.现在就主要有三种方法来构建对象,class关键字,构造函数,工厂函数.他们都是创建对象的手段,但是却又有不同的地方,平时开发时,也需要针对这不同来选择. 首先我们来看一下,这三种方法是怎样的 // class 关键字,ES6新特性 class ClassCar { drive () { console.log('Vroom!'); } } const car1 = new ClassCar(); consol
-
详解SQL中Group By的使用教程
1.概述 "Group By"从字面意义上理解就是根据"By"指定的规则对数据进行分组,所谓的分组就是将一个"数据集"划分成若干个"小区域",然后针对若干个"小区域"进行数据处理. 2.原始表 3.简单Group By示例1 select 类别, sum(数量) as 数量之和from Agroup by 类别 返回结果如下表,实际上就是分类汇总. 4.Group By 和 Order By示例2 sele
-
详解JAVA中static的作用
1.深度总结 引用一位网友的话,说的非常好,如果别人问你static的作用:如果你说静态修饰 类的属性 和 类的方法 别人认为你是合格的:如果是说 可以构成 静态代码块,那别人认为你还可以: 如果你说可以构成 静态内部类, 那别人认为你不错:如果你说了静态导包,那别人认为你很OK: 那我们就先在这几方面一一对static进行总结:然后说一些模糊的地方,以及一些面试中容易问道的地方: 1)static方法 static方法一般称作静态方法,由于静态方法不依赖于任何对象就可以进行访问,因此对于静态方
-
详解java中的static关键字
Java中的static关键字可以用于修饰变量.方法.代码块和类,还可以与import关键字联合使用,使用的方式不同赋予了static关键字不同的作用,且在开发中使用广泛,这里做一下深入了解. 静态资源(静态变量与静态方法) 被static关键字修饰的变量和方法统一属于类的静态资源,是类实例之间共享的.被static关键字修饰的变量.方法属于类变量.类方法,可以通过[类名.变量名].[类名.方法名]直接引用,而不需要派生一个类实例出来. 静态资源分类存放的好处 JDK把不同的静态资源放在了不同的
-
详解c# 中的DateTime
日期和时间,在我们开发中非常重要.DateTime在C#中,专门用来表达和处理日期和时间. 本文算是多年使用DateTime的一个总结,包括DateTime对象的整体应用,以及如何处理不同的区域.时区.格式等内容. 一.什么是DateTime 跟我们想的不一样,DateTime不是一个类(class),而是一个结构(struct),它存在于System命名空间下,在Dotnet Core中,处于System.Runtime.dll中. 看一下DateTime的定义: public struct
-
详解Java中的BigDecimal
今天碰到一个问题,金额计算用double类型会丢失经度,就改用了BigDecimal类型,这个类型之前用的比较少,没怎么接触.就到网上看了一下相关教程,写个总结记一下. BigDecimal类 对于不需要任何准确计算精度的数字可以直接使用float或double,但是如果需要精确计算的结果,则必须使用BigDecimal类,而且使用BigDecimal类也可以进行大数的操作. BigDecimal构造方法 1.public BigDecimal(double val) 将double表示形式转换
-
详解mysql中的存储引擎
mysql存储引擎概述 什么是存储引擎? MySQL中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛的不同的功能和能力.通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能. 例如,如果你在研究大量的临时数据,你也许需要使用内存存储引擎.内存存储引擎能够在内存中存储所有的表格数据.又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力). 这些不同的技术以及配套的相关
-
详解mysql中explain的type
导语: 很多情况下,有很多人用各种select语句查询到了他们想要的数据后,往往便以为工作圆满结束了. 这些事情往往发生在一些学生亦或刚入职场但之前又没有很好数据库基础的小白身上,但所谓闻道有先后,只要我们小白好好学习,天天向上,还是很靠谱的. 当一个sql查询语句被写出来之后,其实你的工作只完成了一小半,接下来更重要的工作是评估你自己写的sql的质量与效率.mysql为我们提供了很有用的辅助武器explain,它向我们展示了mysql接收到一条sql语句的执行计划.根据explain返回的结果