如何使用Python程序完成描述性统计分析需求
目录
- 一、前言
- 1.1 关于描述性统计分析
- 1.2 本篇目的
- 1.3 提示
- 二、程序内容的编写
- 2.1 导入数据与前期处理
- 2.2 描述性统计分析所要计算的数据
- 2.3 数据可视化
- 2.3.1 概述
- 2.3.2 思路
- 2.4 补充内容
- 三、完整代码与总结
一、前言
1.1 关于描述性统计分析
概括地来说,描述性统计分析就是在收集到的数据的基础上,运用制表和分类,图形以及计算概括性数据来描述数据特征的各项活动。重要的是,该方法主要内容包括频数分析、集中趋势分析、离散程度分析、分布以及一些基本的统计图形。
1.2 本篇目的
本篇内容主要是编写python代码,以实现描述性统计的基本需求,即通过程序获得在描述性统计分析时所需要的数据内容。具体见下。
1.3 提示
本系列篇属于实践类型的代码编写,需要一定的代码基础,因此有不理解的函数或方法可以查找他人的教程或是看本人所写的基础篇分享。本篇的中心内容是2.1与2.2部分,该部分代码可直接使用,根据需要可自行修改;而2.3可视化部分了解思路与代码框架即可,代码可根据个人需要重写。
二、程序内容的编写
2.1 导入数据与前期处理
首先是导入excel表格里的数据,并进行一些基本的设置。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
pd.set_option('display.max_columns',1000)
pd.set_option("display.width",1000)
pd.set_option('display.max_colwidth',1000)
pd.set_option('display.max_rows',1000)#将行和列的最大展示值设置到1000,则可展示更多的行而不是以省略号形式展示。
df=pd.read_excel(r'D:\杂货\编码数据.xlsx',sheet_name='编码数据')
第一、二、三行分别是导入pandas,numpy,matplotlib库,后面会用到库的内容来编写。
第四到第七行分别是将导入列表的输出展示内容扩大到1000的数量(按照需要,1000这个数值还可以设置的更大),这样在打印输出表格的时候,就不会出现省略号省略掉中间内容的情况。就像我在第一篇基础篇中导入excel时出现的情况:
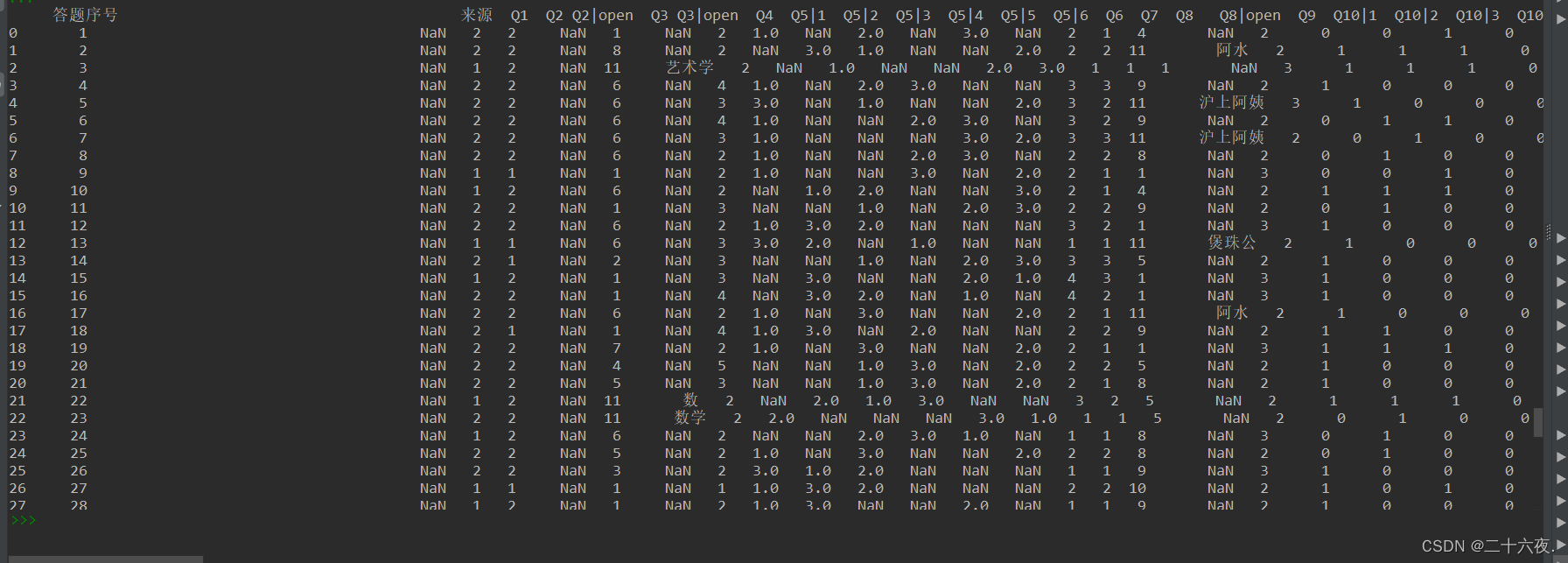
设置好后的输出情况:
导入excel表格具体可看我第一篇内容:如何在Python中导入EXCEL数据
2.2 描述性统计分析所要计算的数据
通常,描述性统计分析需要各变量的观测值数量、均值、方差、标准差、最大最小值等,而在python中可运用库的方法计算出各个数据。详细代码见以下:
obs=df.count()#观测值
means=df.mean()#均值
var=df.var()#方差
std=df.std()#标准差
min=df.min()#最小值
max=df.max()#最大值
mode=df.mode()#众数
siyi=df.quantile(0.25)#四分之一位数
sisan=df.quantile(0.75)#四分之三位数
median=df.median()#中位数
skew=df.skew()#偏度
kurt=df.kurt()#峰度
print("最大值:\n",max,'\n',"最小值:\n",min,'\n','观测量:\n',obs,'\n','均值:\n',means,'\n',
"方差:\n",var,"\n",'标准差:\n',std,'\n',"众数: ",mode,"\n",'四分之一位数:\n',siyi,'\n',
'四分之三位数:\n',sisan,'\n','中位数:\n',median,'\n','偏度:\n',skew,'\n','峰度:\n',kurt)
代码的含义在注释中已经标注出来了,不再赘述。(print里的“\n”表示换行输出)在运行以上代码后,可以得到excel表格中每一列的对应数据,展示如下:
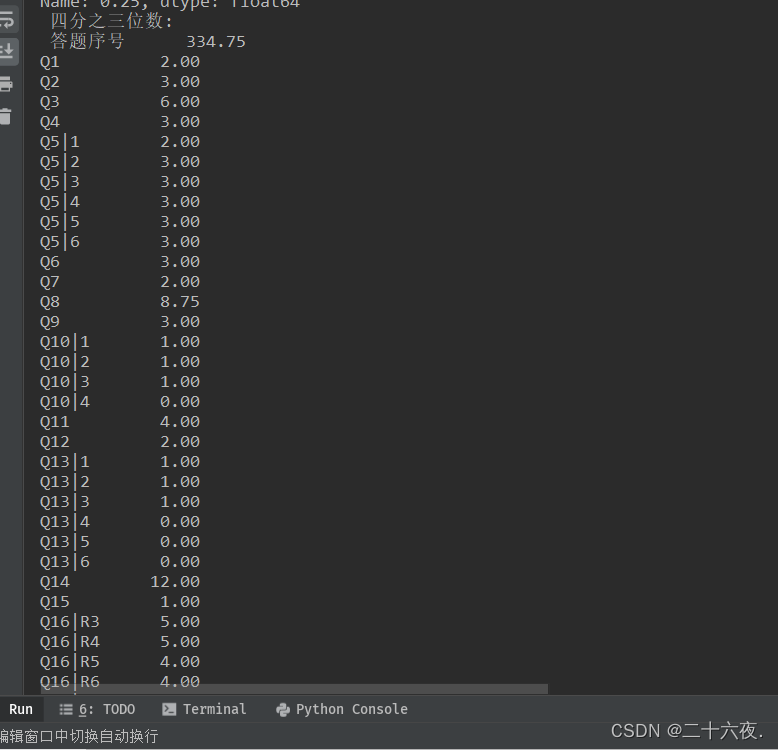
输出的样式如上图,由于结果太多太长,就不一一展示。
2.3 数据可视化
2.3.1 概述
描述性统计分析中,除了列出以上的分析数据以外,在多数情况下仍然需要对重要的数据给出可视化的内容,即作图。数据可视化的图的类型有很多种,比如说折线图、柱状图、条形图、散点图、气泡图、雷达图、箱线图等。而在一般的数据分析类报告中,最常用的便是折线图、柱状图,因此在本篇中只介绍这两种可视化方法,其他的在后续教程分享中会按需要给出。
2.3.2 思路
可视化之前要有一个编写代码的思路,而作图的基本思路如下:
建立画布建立坐标系输入x轴数据与y轴数据设定x轴与y轴的刻度并给刻度命名作图2.3.3 编写代码
fig=plt.figure()#建立画布 ax1=fig.add_subplot(1,1,1)#建立坐标系 x=np.arange(7)#x轴数据 y=np.array([jishu1,jishu2,jishu3,jishu4,jishu5,jishu6,jishu7])#y轴数据 plt.xticks(np.arange(7),['0-50元','50-100元','100-150元','150-200元','200-250元','250-300元','300元及以上'])#x轴长度与命名 plt.yticks(np.arange(0,350,50))#y轴长度与命名 plt.plot(x,y)#作图
建立坐标系:
建立坐标系中,add_subplot()方法括号里的数字的含义是:一行一列的第一个坐标系。这么说可能有点抽象,我给出以下例子:
#代码1: fig=plt.figure()#建立画布 ax1=fig.add_subplot(1,1,1)#建立坐标系 #代码2: fig=plt.figure()#建立画布 ax1=fig.add_subplot(2,2,1)#建立坐标系1 ax2=fig.add_subplot(2,2,2)#建立坐标系2 ax3=fig.add_subplot(2,2,3)#建立坐标系3 ax4=fig.add_subplot(2,2,4)#建立坐标系4
代码1中的(1,1,1)表示一行一列的第一个坐标系;代码二中的(2,2,1)表示二行二列的第一个坐标系,(2,2,2)表示二行二列的第二个坐标系,(2,2,3)表示二行二列的第三个坐标系,(2,2,4)表示二行二列的第四个坐标系。
而这两段代码展示出的坐标图是不一样的,见下图:
代码1:
代码2:
对比两个输出结果,可以很容易地知道,代码1一张图中只作了一个坐标系,而代码2的一张图中作出了四个坐标系。一行一列的第一个坐标系指的就是代码1唯一的这一个坐标系,而二行二列的第一个坐标系指的是左上角的坐标系,二行二列的第四个坐标系指的是右下角的坐标系。这样应该就能比较好地理解这个函数的意义了。
附上数据(坐标):
看到x与y轴数据的代码,其中np.arange()函数是调用的np库的函数方法。arange()中,方法与range()长的比较像:arange(start,end,step)。具体含义可以查看后续基础篇分享。若了解range()函数的话,那么arange(7)中的数字7的含义我也不用多说。x=np.arange(7)则表示横坐标x分别等于0,1,2,3,4,5,6时对应的情况。对于y中的array()函数,其主要是用于矩阵或数组的输入的,而本篇中的代码:y=np.array([jishu1,jishu2,jishu3,jishu4,jishu5,jishu6,jishu7]),其中的jishu1这一系列的命名是我定义的变量名,其具体含义我在后文补充,总之在array()中需要输入的也是数字。(按照各个问题的需要,本篇使用了array(),而x与y都适用np.arange()来输入数据都是可以的)。
由此,x与y的数值组成了一个坐标(x,y),从而能定义一个点的位置。
设定刻度(又可称长度)与名称:
最后三行代码中的plt.xticks()与plt.yticks()方法分别是为了设定坐标刻度(又可称长度)与名称准备的。其中,括号内的方法为:(刻度,命名),而np.arange(7)表示横坐标轴设定的长度为7,列表['0-50元','50-100元','100-150元','150-200元','200-250元','250-300元','300元及以上']即每一个刻度的命名。
最后一行代码则是作出符合以上条件的坐标图。
其结果展示如下:
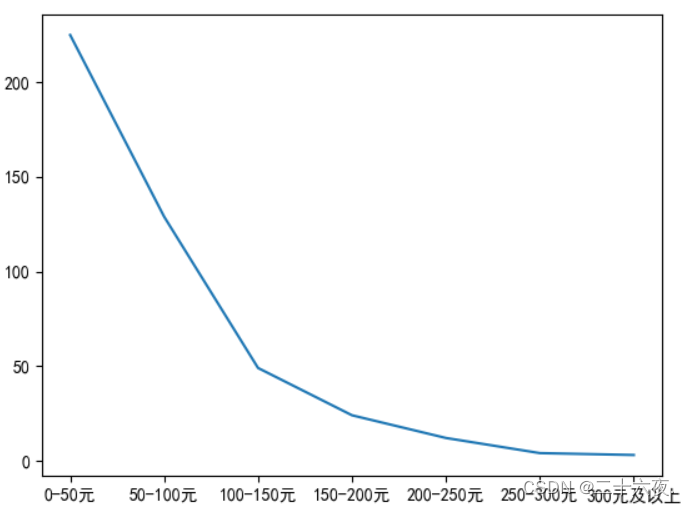
显而易见,x轴的刻度编程了我所设定的名称,y轴没有设定名称,则以数值的形式出现。
为了使坐标图更加直观,我们也可以给x轴和y轴赋上标签,代码如下:
plt.xlabel('消费金额')#x轴的标签
plt.ylabel('人数')#y轴的标签
此时坐标图如下:
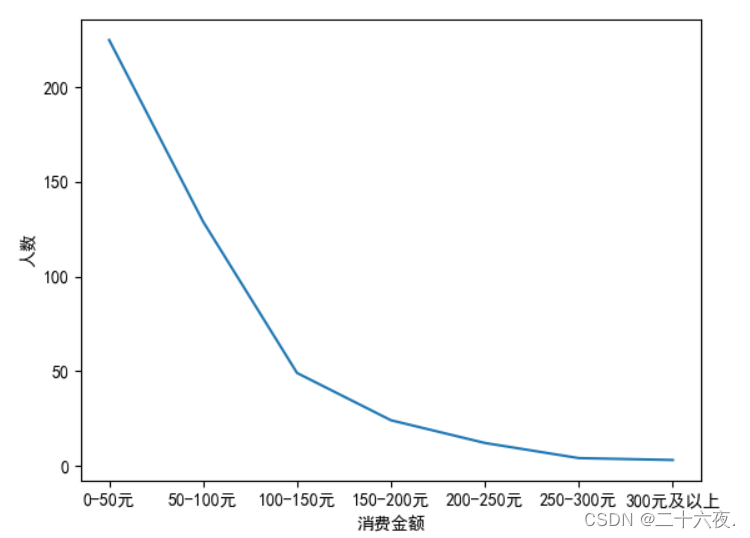
对比前面的坐标图,此时的坐标图中x轴和y轴都有了它们的“名字”,这样图的关系就更加明朗了。
2.4 补充内容
前面提到,array()函数中的列表是什么意思。我是以我自己所收集的数据为例,写的本篇内容,因此有的地方是看个人研究需要而写的代码,在该部分我加以解释。
Q7=df.iloc[:,15]
q7=[]
for i in Q7:
q7.append(i)
print(q7)#读取所要分析的列的数据
jishu1=int(q7.count(1))
jishu2=int(q7.count(2))
jishu3=int(q7.count(3))
jishu4=int(q7.count(4))
jishu5=int(q7.count(5))
jishu6=int(q7.count(6))
jishu7=int(q7.count(7))#计数
print('0-50元的有:',jishu1,'\n','50-100元的有:',jishu2,'\n','100-150元的有:',jishu3,'\n',
'150-200元的有:',jishu4,'\n','200-250元的有:',jishu5,'\n','250-300元的有:',jishu6,'\n','300元及以上的有:',jishu7,'\n')
第一行的df.iloc[:,15]表示的含义是我要读取第十五列的变量的数据,该内容为“选取excel表格中的某一列”的方法的内容,属于基础篇的操作,在后续我会在基础篇中分享给部分的内容,不在此地赘述。
下面的循环是我将读取的函数放入列表中,并用count()函数计算个数(该数据为人数计数,因此count()实际上是在数人数),由此得出以下各个消费段的人数,输出结果如下:
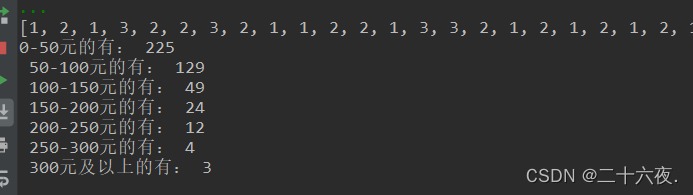
这七个数值就是y轴输入的数据。由此应该就能理解我在编写y轴输入数据的代码时列表里的几个变量名是啥意思了。
三、完整代码与总结
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
pd.set_option('display.max_columns',1000)
pd.set_option("display.width",1000)
pd.set_option('display.max_colwidth',1000)
pd.set_option('display.max_rows',1000)#将行和列的最大展示值设置到1000,则可展示更多的行而不是以省略号形式展示。
df=pd.read_excel(r'D:\杂货\编码数据.xlsx',sheet_name='编码数据')
obs=df.count()#观测值
means=df.mean()#均值
var=df.var()#方差
std=df.std()#标准差
min=df.min()#最小值
max=df.max()#最大值
mode=df.mode()#众数
siyi=df.quantile(0.25)#四分之一位数
sisan=df.quantile(0.75)#四分之三位数
median=df.median()#中位数
skew=df.skew()#偏度
kurt=df.kurt()#峰度
print("最大值:\n",max,'\n',"最小值:\n",min,'\n','观测量:\n',obs,'\n','均值:\n',means,'\n',
"方差:\n",var,"\n",'标准差:\n',std,'\n',"众数: ",mode,"\n",'四分之一位数:\n',siyi,'\n',
'四分之三位数:\n',sisan,'\n','中位数:\n',median,'\n','偏度:\n',skew,'\n','峰度:\n',kurt)
#作图
Q7=df.iloc[:,15]
q7=[]
for i in Q7:
q7.append(i)
print(q7)#读取所要分析的列的数据
jishu1=int(q7.count(1))
jishu2=int(q7.count(2))
jishu3=int(q7.count(3))
jishu4=int(q7.count(4))
jishu5=int(q7.count(5))
jishu6=int(q7.count(6))
jishu7=int(q7.count(7))#计数
print('0-50元的有:',jishu1,'\n','50-100元的有:',jishu2,'\n','100-150元的有:',jishu3,'\n',
'150-200元的有:',jishu4,'\n','200-250元的有:',jishu5,'\n','250-300元的有:',jishu6,'\n','300元及以上的有:',jishu7,'\n')
fig=plt.figure()#建立画布
ax1=fig.add_subplot(1,1,1)#建立坐标系
x=np.arange(7)#x轴数据
y=np.array([jishu1,jishu2,jishu3,jishu4,jishu5,jishu6,jishu7])#y轴数据
plt.xticks(np.arange(7),['0-50元','50-100元','100-150元','150-200元','200-250元','250-300元','300元及以上'])#x轴长度与命名
plt.yticks(np.arange(0,350,50))#y轴长度与命名
plt.plot(x,y)#作图
plt.xlabel('消费金额')#x轴代表的名字
plt.ylabel('人数')#y轴代表的名字
到此这篇关于如何使用Python程序完成描述性统计分析需求的文章就介绍到这了,更多相关Python完成描述性统计分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

利用Python分析一下最近的股票市场
目录 一.数据获取 二.合并数据 三.绘制股票每日百分比变化 四.箱线图 五.计算月化夏普比率 六.结论 一.数据获取 数据获取范围为2022年一月一日到2022年2月25日,获取的数据为俄罗斯黄金,白银,石油,银行,天然气: # 导入模块 import numpy as np import pandas as pd import yfinance as yf # GC=F黄金,SI=F白银,ROSN.ME俄罗斯石油,SBER.ME俄罗斯银行,天然气 tickerSymbols = ['GC=F
-
Python分析微信好友性别比例和省份城市分布比例的方法示例【基于itchat模块】
本文实例讲述了Python分析微信好友性别比例和省份城市分布比例的方法.分享给大家供大家参考,具体如下: 安装itchat pip install itchat 使用 新建wxfx.py,拷贝以下代码 # -*- coding: utf-8 -*- #导入模块 from wxpy import * ''' 微信机器人登录有3种模式, (1)极简模式:robot = Bot() (2)终端模式:robot = Bot(console_qr=True) (3)缓存模式(可保持登录状态):robot
-
如何利用Python分析出微信朋友男女统计图
写在前面 现在人人都有微信,一句"咱们加个微信呗"搭载了你我之间的友谊桥梁,浑然不知自己的微信朋友已经四五百了,甚至上千,几千的都有:然而那个是那个,谁是谁,是男是女都分不清楚了,今天咱们就来统计一下你微信朋友的男女比例,来看你平常喜欢加男性朋友还是女性朋友,哈哈,暴露了吧. 下面话不多说了,来一起看看详细的介绍吧 环境安装 有一个挺有意思的库是itchat,它是一个开源的微信个人接口,咱们就用itchat来统计自己微信朋友的性别比例,并且用柱状图呈现出来,使自己一目了然. (1)首先
-
python分析inkscape路径数据方案简单介绍
目录 前言 inkscape生成路径 将形状转换为路径 python分析svg 前言 开发过程中有时需要使用路径数据,虽然python有自己的svg或其他矢量库,但这里只是出于实验的目的,没必要深入研究,所以采用一些简单的方案:用inkscape生成svg,然后python分析并输出,从而达到相应目的 inkscape生成路径 设置文档属性: 设置网格: 导入png图像作为参考: 注意导入图像.文档属性,都是已左下角为原点: 在图层与对象属性栏,修改图像可见性.锁定图像: 在当前图层之上新建一个
-
Python分析最近大火的网剧《隐秘的角落》
前言 估计最近很火的连续剧<隐秘的角落>大家趁着端午假期都看过了吧?小编也跟着潮流,一口气把12集的连续剧全部看完了.看过的人肯定对朋友圈里有人发的"一起去爬山"."小白船"."还有机会吗"的意思心照不宣.没看过的,如果已为人父人母的,强烈要求看一下. 剧很精彩,但追剧界有句俗话说得好:"弹幕往往比剧更精彩",为了让精彩延续下去,咱们来看看该剧弹幕的部分.电视剧是在爱奇艺独播,因此从爱奇艺上爬虫最为合适. 爬取弹幕
-
python分析实现微信钉钉等软件多开分身
目前很多软件都限制单实例,大多数软件都是用Mutex来实现的 而这个东西咱们可以用handle去干掉它,并且不影响使用. 钉钉也是一样的步骤 不过Mutex的名字不一样 我测试的钉钉的是: ”\Sessions\1\BaseNamedObjects\{{239B7D43-86D5-4E5C-ADE6-CEC42155B475}}DingTalk“ 这里要借助微软的两个软件 分别是:procexp handle 接下来开始正文: 首先咱们要手动判断下Mutex是哪个. 这就要用到procexp.e
-
Python分析特征数据类别与预处理方法速学
目录 前言 一.特征类型判别 二.定量数据特征处理 三.定类数据特征处理 1.LabelEncoding 2.OneHotcoding 优点: 缺点: 应用场景: 无用场景: 代码实现 方法二: 前言 当我们开始准备数据建模.构建机器学习模型的时候,第一时间考虑的不应该是就考虑到选择模型的种类和方法.而是首先拿到特征数据和标签数据进行研究,挖掘特征数据包含的信息以及思考如何更好的处理这些特征数据.那么数据类型本身代表的含义就需要我们进行思考,究竟是定量计算还是进行定类分析更好呢?这就是这篇文章将
-
Python程序语言快速上手教程
本来打算从网上找一篇入门教程,但因为Python很少是程序员的第一次接触程序所学的语言,所以网上现有的教程多不是很基础,还是决定自己写下这些. 如果没有程序基础的话,可能会觉得本文涵盖的内容有点多.对照大学里面常教的C语言的教学速度,本文大约有四五个课时的内容:对照网上程序类的视频 教程,大致相当于两三个小时的内容:对于翻一本程序书籍,大约相当于翻一个小时书.也因此,如果有深入学习的打算的话,为了效率还是推荐看书. 如果暂时不能理解本文中的一些内容也没关系,因为都是一些经常会用到的基础知识,在实
-
用Python编写分析Python程序性能的工具的教程
虽然并非你编写的每个 Python 程序都要求一个严格的性能分析,但是让人放心的是,当问题发生的时候,Python 生态圈有各种各样的工具可以处理这类问题. 分析程序的性能可以归结为回答四个基本问题: 正运行的多快 速度瓶颈在哪里 内存使用率是多少 内存泄露在哪里 下面,我们将用一些神奇的工具深入到这些问题的答案中去. 用 time 粗粒度的计算时间 让我们开始通过使用一个快速和粗暴的方法计算我们的代码:传统的 unix time 工具. $ time python yourprogram.py
-
在Python程序员面试中被问的最多的10道题
我们在为大家整Python程序员面试试题中,发现了一些被面试官问到的最多的一些问题,以下就是本篇内容: Python是个非常受欢迎的编程语言,随着近些年机器学习.云计算等技术的发展,Python的职位需求越来越高.下面我收集了10个Python面试官经常问的问题,供大家参考学习. 类继承 有如下的一段代码: class A(object): def show(self): print 'base show' class B(A): def show(self): print 'derived s
-
Python程序员面试题 你必须提前准备!(答案及解析)
在发布<Python程序员面试,这些问题你必须提前准备!>一文后,应广大程序员朋友的强烈要求,小编就Python程序员面试必备问题整理了一份参考答案,希望能对准备换工作的程序员朋友有所帮助.如对答案有疑问,欢迎留言讨论. 小编将这些面试问题大致分为四类: 什么(what)?如何做(how)?说区别/谈优势(difference)以及实践操作(practice). What? 1. 什么是Python? Python是一种编程语言,它有对象.模块.线程.异常处理和自动内存管理.可以加入与其他语言
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-
编写python程序的90条建议
1. 首先 建议1.理解 Pythonic 概念--详见 Python 中的<Python之禅> 建议2.编写 Pythonic 代码 (1)避免不规范代码,比如只用大小写区分变量.使用容易混淆的变量名.害怕过长变量名等.有时候长的变量名会使代码更加具有可读性. (2)深入学习 Python 相关知识,比如语言特性.库特性等,比如Python演变过程等.深入学习一两个业内公认的 Pythonic 的代码库,比如Flask等. 建议3:理解 Python 与 C 的不同之处,比如缩进与 {},单
-
使用Kivy将python程序打包为apk文件
1.概述 Kivy是一套Python下的跨平台开源应用开发框架,官网,我们可以用 它来将Python程序打包为安卓的apk安装文件.以下是在windows环境中使用. 安装和配置的过程中会下载很多东西,确保你能够稳定地访问外网,另外推荐一个视频教程:Youtube 2. 步骤 第一当然是安装了Python,我的版本是Python 2.7.13,然后就是安装Kivy包: 官网有详细的Kivy包的安装步骤,按照该步骤走完就安装ok. 然后就是写一个简单的程序main.py测试一下: import k
-
十个Python程序员易犯的错误
常见错误1:错误地将表达式作为函数的默认参数 在Python中,我们可以为函数的某个参数设置默认值,使该参数成为可选参数.虽然这是一个很好的语言特性,但是当默认值是可变类型时,也会导致一些令人困惑的情况.我们来看看下面这个Python函数定义: >>> def foo(bar=[]): # bar是可选参数,如果没有提供bar的值,则默认为[], ... bar.append("baz") # 但是稍后我们会看到这行代码会出现问题. ... return bar Py
-
以windows service方式运行Python程序的方法
本文实例讲述了以windows service方式运行Python程序的方法.分享给大家供大家参考.具体实现方法如下: #!/usr/bin/env python # coding: utf-8 # SmallestService.py # # A sample demonstrating the smallest possible service written in Python. import win32serviceutil import win32service import win3
-
使用C语言扩展Python程序的简单入门指引
一.简介 Python是一门功能强大的高级脚本语言,它的强大不仅表现在其自身的功能上,而且还表现在其良好的可扩展性上,正因如此,Python已经开始受到越来越多人的青睐,并且被屡屡成功地应用于各类大型软件系统的开发过程中. 与其它普通脚本语言有所不同,Python程序员可以借助Python语言提供的API,使用C或者C++来对Python进行功能性扩展,从而即可以利用Python方便灵活的语法和功能,又可以获得与C或者C++几乎相同的执行性能.执行速度慢是几乎所有脚本语言都具有的共性,也是倍受人