SQL数据去重的3种方法实例详解
目录
- 1、使用distinct去重
- 2、使用group by
- 3、使用ROW_NUMBER() OVER 或 GROUP BY 和 COLLECT_SET/COLLECT_LIST
- 3.1 ROW_NUMBER() OVER
- 3.2 GROUP BY 和 COLLECT_SET/COLLECT_LIST
- distinct与group by的去重方面的区别
- 使用去重distinct方法的示例详解
- 总结
1、使用distinct去重
distinct用来查询不重复记录的条数,用count(distinct id)来返回不重复字段的条数。用法注意:
- distinct【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
- 只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
- DISTINCT 表示对后面的所有参数的拼接取不重复的记录,即查出的参数拼接每行记录都是唯一的
- 不能与all同时使用,默认情况下,查询时返回的就是所有的结果。
distinct支持单列、多列的去重方式。
- 作用于单列
单列去重的方式简明易懂,即相同值只保留1个。
select distinct name from A //对A表的name去重然后显示
- 作用于多列
多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。注意,distinct作用于多列的时候只在开头加上即可,并不用每个字段都加上。distinct必须在开头,在中间是不可以的,会报错,`select id,distinct name from A //错误
select distinct id,name from A //对A表的id和name去重然后显示
- 配合count使用
select count(distinct name) from A //对A表的不同的name进行计数
按顺序去重时,order by 的列必须出现在 distinct 中
出错代码
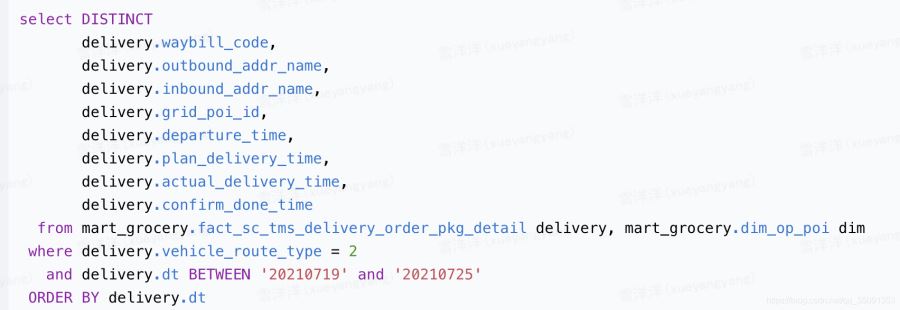
改正后的代码

讨论:若不使用Distinct关键字,则order by后面的字段不一定要放在seletc中

MySQL中使用去重distinct方法的示例详解
【Hive】数据去重
2、使用group by
GROUP BY 语句根据一个或多个列对结果集进行分组。在分组的列上我们可以使用 COUNT, SUM, AVG,等函数,形式为select 重复的字段名 from 表名 group by 重复的字段名;
group by 对age查询结果进行了分组,自动将重复的项归结为一组。

还可以使用count函数,统计重复的数据有多少个

3、使用ROW_NUMBER() OVER 或 GROUP BY 和 COLLECT_SET/COLLECT_LIST
说到要去重,自然会想到 DISTINCT,但是在 Hive SQL 里,它有两个问题:
- DISTINCT 会以 SELECT 出的全部列作为 key 进行去重。也就是说,只要有一列的数据不同,DISTINCT 就认为是不同数据而保留。
- DISTINCT 会将全部数据打到一个 reducer 上执行,造成严重的数据倾斜,耗时巨大。
3.1 ROW_NUMBER() OVER
DISTINCT 的两个问题,用 ROW_NUMBER() OVER 可解。比如,如果我们要按 key1 和 key2 两列为 key 去重,就会写出这样的代码:
WITH temp_table AS (
SELECT
key1,
key2,
[columns]...,
ROW_NUMBER() OVER (
PARTITION BY key1, key2
ORDER BY column ASC
) AS rn
FROM
table
)
SELECT
key1,
key2,
[columns]...
FROM
temp_table
WHERE
rn = 1;
这样,Hive 会按 key1 和 key2 为 key,将数据打到不同的 mapper 上,然后对 key1 和 key2 都相同的一组数据,按 column 升序排列,并最终在每组中保留排列后的第一条数据。借此就完成了按 key1 和 key2 两列为 key 的去重任务。注意 PARTITION BY 在此起到的作用:
- 一是按 key1 和 key2 打散数据,解决上述问题 (2);
- 二是与 ORDER BY 和 rn = 1 的条件结合,按 key1 和 key2 对数据进行分组去重,解决上述问题 (1)。
但显然,这样做十分不优雅(not-elegant),并且不难想见其效率比较低。
row_number() OVER (PARTITION BY
COL1ORDER BYCOL2) as num 表示根据COL1分组,在分组内部根据COL2排序,此函数计算的值num就表示每组内部排序后的顺序编号(组内连续的唯一的)
3.2 GROUP BY 和 COLLECT_SET/COLLECT_LIST
ROW_NUMBER() OVER 解法的一个核心是利用 PARTITION BY 对数据按 key 分组,同样的功能用 GROUP BY 也可以实现。但是,GROUP BY 需要与聚合函数搭配使用。我们需要考虑,什么样的聚合函数能实现或者间接实现这样的功能呢?不难想到有 COLLECT_SET 和 COLLECT_LIST。
SELECT key1, key2, [COLLECT_LIST(column)[1] AS column]... FROM temp_table GROUP BY key1, key2
对于 key1 和 key2 以外的列,我们用 COLLECT_LIST 将他们收集起来,然后输出第一个收集进来的结果。这里使用 COLLECT_LIST 而非 COLLECT_SET 的原因在于 SET 内是无序的,因此你无法保证输出的 columns 都来自同一条数据。若对于此没有要求或限制,则可以使用 COLLECT_SET,它会更节省资源。
相比前一种办法,由于省略了排序和(可能的)落盘动作,所以效率会高不少。但是因为(可能)不落盘,所以 COLLECT_LIST 中的数据都会缓存在内存当中。如果重复数量特别大,这种方法可能会触发 OOM。此时应考虑将数据进一步打散,然后再合并;或者干脆换用前一种办法。
distinct与group by的去重方面的区别
distinct简单来说就是用来去重的,而group by的设计目的则是用来聚合统计的,两者在能够实现的功能上有些相同之处,但应该仔细区分。
单纯的去重操作使用distinct,速度是快于group by的。
distinct支持单列、多列的去重方式。
单列去重的方式简明易懂,即相同值只保留1个。
多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。
group by使用的频率相对较高,但正如其功能一样,它的目的是用来进行聚合统计的,虽然也可能实现去重的功能,但这并不是它的长项。
区别:
1)distinct只是将重复的行从结果中出去;
group by是按指定的列分组,一般这时在select中会用到聚合函数。
2)distinct是把不同的记录显示出来。
group by是在查询时先把纪录按照类别分出来再查询。
group by 必须在查询结果中包含一个聚集函数,而distinct不用。
distinct和group by有啥区别,大概总结以下几点:
distinct适合查单个字段去重,支持单列、多列的去重方式。 单列去重的方式简明易懂,即相同值只保留1个。
多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。
而 group by 可以针对要查询的全部字段中的部分字段去重,它的作用主要是:获取数据表中以分组字段为依据的其他统计数据。
补充:MySQL中distinct和group by去重性能对比
前言
- MySQL:5.7.17
- 存储引擎:InnoDB
- 实验目的:本文主要测试在某字段有无索引、各种不同值个数情况下,记录对此字段其使用
DISTINCT/GROUP BY去重的查询语句执行时间,对比两者在不同场景下的去重性能,实验过程中关闭MySQL查询缓存。 - 实验表格:
| 表名 | 记录数 | 查询字段有无索引 | 查询字段不同值个数 | DISTINCT | GROUP BY |
|---|---|---|---|---|---|
| tab_1 | 100000 | N | 3 | ||
| tab_2 | 100000 | Y | 3 | ||
| tab_3 | 100000 | N | 10000 | ||
| tab_4 | 100000 | Y | 10000 |
实验过程
1)创建测试表
表创建语句:
DROP TABLE IF EXISTS `tab_1`; CREATE TABLE `tab_1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `value` int(10) unsigned NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `tab_2`; CREATE TABLE `tab_2` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `value` int(10) unsigned NOT NULL, PRIMARY KEY (`id`), KEY `idx_value` (`value`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `tab_3`; CREATE TABLE `tab_3` LIKE `tab_1`; DROP TABLE IF EXISTS `tab_4`; CREATE TABLE `tab_4` LIKE `tab_2`;
2)生成测试数据
表数据插入过程:
DROP PROCEDURE IF EXISTS generateRandomData;
delimiter $$
-- tblName为插入表,field为插入字段,num为插入字段值上限,count为插入的记录数
CREATE PROCEDURE generateRandomData(IN tblName VARCHAR(30),IN field VARCHAR(30),IN num INT UNSIGNED,IN count INT UNSIGNED)
BEGIN
-- 声明循环变量
DECLARE i INT UNSIGNED DEFAULT 1;
-- 循环插入随机整数1~num,共插入count条数据
w1:WHILE i<=count DO
set i=i+1;
set @val = FLOOR(RAND()*num+1);
set @statement = CONCAT('INSERT INTO ',tblName,'(`',field,'`) VALUES(',@val,')');
PREPARE stmt FROM @statement;
EXECUTE stmt;
END WHILE w1;
END $$
delimiter ;
调用过程随机生成测试数据:
call generateRandomData('tab_1','value',3,100000);
INSERT INTO tab_2 SELECT * FROM tab_1;
call generateRandomData('tab_3','value',10000,100000);
INSERT INTO tab_4 SELECT * FROM tab_3;
3)执行查询语句,记录执行时间
查询语句及对应执行时间如下:
SELECT DISTINCT(`value`) FROM tab_1; SELECT `value` FROM tab_1 GROUP BY `value`; SELECT DISTINCT(`value`) FROM tab_2; SELECT `value` FROM tab_2 GROUP BY `value`; SELECT DISTINCT(`value`) FROM tab_3; SELECT `value` FROM tab_3 GROUP BY `value`; SELECT DISTINCT(`value`) FROM tab_4; SELECT `value` FROM tab_4 GROUP BY `value`;
4)实验结果
| 表名 | 记录数 | 查询字段有无索引 | 查询字段不同值个数 | DISTINCT | GROUP BY |
|---|---|---|---|---|---|
| tab_1 | 100000 | N | 3 | 0.058s | 0.059s |
| tab_2 | 100000 | Y | 3 | 0.030s | 0.027s |
| tab_3 | 100000 | N | 10000 | 0.072s | 0.073s |
| tab_4 | 100000 | Y | 10000 | 0.047s | 0.049s |
实验结论
MySQL 5.7.17中使用distinct和group by进行去重时,性能相差不大
使用去重distinct方法的示例详解
一 distinct
含义:distinct用来查询不重复记录的条数,即distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段
用法注意:
1.distinct【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
2.只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
3.DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,即查出的参数拼接每行记录都是唯一的
4.不能与all同时使用,默认情况下,查询时返回的就是所有的结果。
1.1只对一个字段查重
对一个字段查重,表示选取该字段一列不重复的数据。
示例表:psur_list

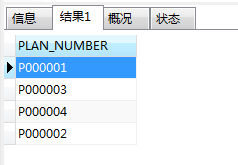
PLAN_NUMBER字段去重,语句:
SELECT DISTINCT PLAN_NUMBER FROM psur_list;
结果如下:
1.2多个字段去重
对多个字段去重,表示选取多个字段拼接的一条记录,不重复的所有记录
示例表:psur_list

PLAN_NUMBER和PRODUCT_NAME字段去重,语句:
SELECT DISTINCT PLAN_NUMBER,PRODUCT_NAME FROM psur_list;
结果如下:

期望结果:只对第一个参数PLAN_NUMBER取唯一值
解决办法一:使用group_concat 函数
语句:
SELECT GROUP_CONCAT(DISTINCT PLAN_NUMBER) AS PLAN_NUMBER,PRODUCT_NAMEFROM psur_list GROUP BY PLAN_NUMBER
解决办法二:使用group by
语句:
SELECT PLAN_NUMBER,PRODUCT_NAME FROM psur_list GROUP BY PLAN_NUMBER
结果如下:

1.3针对null处理
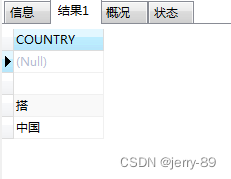
distinct不会过滤掉null值,返回结果包含null值
表psur_list如下:

对COUNTRY字段去重,语句:
SELECT DISTINCT COUNTRY FROM psur_list
结果如下:
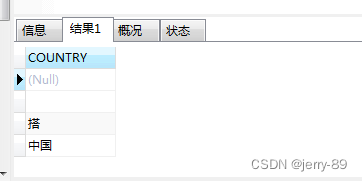
1.4与distinctrow同义
语句:
SELECT DISTINCTROW COUNTRY FROM psur_list
结果如下:
二 聚合函数中使用distinct
在聚合函数中DISTINCT 一般跟 COUNT 结合使用。count()会过滤掉null项
语句:
SELECT COUNT(DISTINCT COUNTRY) FROM psur_list
结果如下:【实际包含null项有4个记录,执行语句后过滤null项,计算为3】

总结
到此这篇关于SQL数据去重的3种方法的文章就介绍到这了,更多相关SQL数据去重方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL数据表合并去重的简单实现方法
场景: 爬取的数据生成数据表,结构与另一个主表相同,需要进行合并+去重 解决:(直接举例) 首先创建两个表pep,pep2,其中pep是主表 CREATE TABLE IF NOT EXISTS `pep/pep2`( `id` INT UNSIGNED AUTO_INCREMENT, `no` VARCHAR(100) NOT NULL, PRIMARY KEY ( `id` ) )ENGINE=InnoDB DEFAULT CHARSET=utf8; 然后向pep中插入两条数据,pep2中插
-
MySQL数据库学习之去重与连接查询详解
目录 1.去重 2.连接查询 使用where进行多表连接查询 内连接 - 等值连接 内连接 - 非等值连接 内连接 - 自连接 外连接 - 左右外连接 三表连接 1.去重 示例表内容参考此文章 有些 MySQL 数据表中可能存在重复的记录,有些情况我们允许重复数据的存在,但有时候我们也需要删除这些重复的数据. 例如:去重显示岗位信息: mysql> select distinct job from emp; +-----------+ | job | +-----------+ | CLERK
-

详解mysql数据去重的三种方式
目录 一.背景 二.数据去重三种方法使用 1.通过MySQL DISTINCT:去重(过滤重复数据) 2.group by 3.row_number窗口函数 三.总结 一.背景 最近在和系统模块做数据联调,其中有一个需求是将两个角色下的相关数据对比后将最新的数据返回出去,于是就想到了去重,再次做一个总结. 二.数据去重三种方法使用 1.通过MySQL DISTINCT:去重(过滤重复数据) 1.1.在使用 mysql SELECT 语句查询数据的时候返回的是所有匹配的行. SELECT
-
MySQL中的多字段相同数据去重复
目录 MySQL多字段相同数据去重复 1.多字段转单字段 2.把多字段合并为单字段 3.将查询到的重复id 4.将获取到重复数据最小的id值 5.bug补充 6.将步骤4的代码多执行几次 总结 MySQL多字段相同数据去重复 MySQL多字段去重复实际上是单字段去重复的衍生,原理就是把多字段数据通过子查询合并为单字段的数据表,再通过单字段数据group by 进行汇总,用 having把 count(字段) > 1的数据都显示出来,最后把查找到的重复数据 用min方法或者max方法获取最小id或
-
浅谈sql数据库去重
关于sql去重,我简单谈一下自己的简介,如果各位有建议或有不明白的欢迎多多指出. 关于sql去重最常见的有两种方式:DISTINCT和ROW_NUMBER(),当然了ROW_NUMBER()除了去重还有很多其他比较重要的功能,一会我给大家简单说说我自己在实际中用到的. 假如有张UserInfo表,如下图: 现在我们要去掉完全重复的数据:SELECT DISTINCT * FROM dbo.UserInfo结果如下图: 但是现在有个新的需求,要把名字为'张三'的去重,也就是相同名字的只要一条数
-
Mysql删除重复的数据 Mysql数据去重复
MySQL数据库中查询重复数据 select * from employee group by emp_name having count (*)>1; Mysql 查询可以删除的重复数据 select t1.* from employee t1 where (t1.emp_name) in (select t4.emp_name from (select t2.emp_name from employee t2 group by t2.emp_name having count(*)>1)
-
MySQL 数据查重、去重的实现语句
有一个表user,字段分别有id.nick_name.password.email.phone. 一.单字段(nick_name) 查出所有有重复记录的所有记录 select * from user where nick_name in (select nick_name from user group by nick_name having count(nick_name)>1); 查出有重复记录的各个记录组中id最大的记录 select * from user where id in (se
-
SQL数据去重的3种方法实例详解
目录 1.使用distinct去重 2.使用group by 3.使用ROW_NUMBER() OVER 或 GROUP BY 和 COLLECT_SET/COLLECT_LIST 3.1 ROW_NUMBER() OVER 3.2 GROUP BY 和 COLLECT_SET/COLLECT_LIST distinct与group by的去重方面的区别 使用去重distinct方法的示例详解 总结 1.使用distinct去重 distinct用来查询不重复记录的条数,用count(disti
-
Android实现定时器的五种方法实例详解
一.Timer Timer是Android直接启动定时器的类,TimerTask是一个子线程,方便处理一些比较复杂耗时的功能逻辑,经常与handler结合使用. 跟handler自身实现的定时器相比,Timer可以做一些复杂的处理,例如,需要对有大量对象的list进行排序,在TimerTask中执行不会阻塞子线程,常常与handler结合使用,在处理完复杂耗时的操作后,通过handler来更新UI界面. timer.schedule(task, delay,period); task: Time
-
springboot单元测试两种方法实例详解
这篇文章主要介绍了springboot单元测试两种方法实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 springboot的单元测试,这里介绍两种方式,一种是在测试类中添加注解:另一种是在代码中启动项目的main方法中继承接口(也可以写在其他方法中). 如 对查看数据库的连接池信息 进行单元测试 1. 在类上使用注解: @RunWith(SpringRunner.class) @SpringBootTest @RunWith(Sprin
-
IOS自带Email的两种方法实例详解
IOS自带Email的两种方法实例详解 IOS系统框架提供的两种发送Email的方法:openURL 和 MFMailComposeViewController.借助这两个方法,我们可以轻松的在应用里加入如用户反馈这类需要发送邮件的功能. 1.openURL 使用openURL调用系统邮箱客户端是我们在IOS3.0以下实现发邮件功能的主要手段.我们可以通过设置url里的相关参数来指定邮件的内容,不过其缺点很明显,这样的过程会导致程序暂时退出.下面是使用openURL来发邮件的一个小例子: #pr
-
Android判断后台服务是否开启的两种方法实例详解
Android判断后台服务是否开启的两种方法实例详解 最近项目用到后台上传,就开启了一个服务service. 但是刚开始用这种方法,有些机型不支持:酷派不支持.然后又换了第二种判断方法. // public boolean isServiceWork(Context mContext, String serviceName) { // boolean isWork = false; // ActivityManager myAM = (ActivityManager) mContext // .
-
JavaScript复制变量三种方法实例详解
这篇文章主要介绍了JavaScript复制变量三种方法实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 直接将一个变量赋给另一个变量时,系统并不会创造一个新的变量,而是将原变量的地址赋给了新变量名.举个栗子: 复制代码 复制代码 let obj = { a: 1, b: 2, }; let copy = obj; obj.a = 5; console.log(copy.a); // Result // a = 5; // 更改obj的值,
-
android studio按钮监听的5种方法实例详解
1.匿名内部类 public class MainActivity extends AppCompatActivity implements View.OnClickListener { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); Button btn1 = fin
-
SQL server分页的四种方法思路详解(最全面教程)
目录 方法一:三重循环 思路 方法二:利用max(主键) 方法三:利用row_number关键字 第四种方法:offset /fetch next(2012版本及以上才有) 总结 这篇博客讲的是SQL server的分页方法,用的SQL server 2012版本.下面都用pageIndex表示页数,pageSize表示一页包含的记录.并且下面涉及到具体例子的,设定查询第2页,每页含10条记录. 首先说一下SQL server的分页与MySQL的分页的不同,mysql的分页直接是用lim
-
php获取POST数据的三种方法实例详解
php获取POST数据的三种方法 方法一,$_POST $_POST或$_REQUEST存放的是PHP以key=>value的形式格式化以后的数据. 方法二,使用file_get_contents("php://input") 对于未指定 Content-Type 的POST数据,则可以使用file_get_contents("php://input");来获取原始数据. 事实上,用PHP接收POST的任何数据均使用本方法.而不用考虑Content-Type,
-
MybatisPlus调用原生SQL的三种方法实例详解
目录 前言 方法一 方法二 方法三 MyBatis-Plus执行原生SQL 前言 在有些情况下需要用到MybatisPlus查询原生SQL,MybatisPlus其实带有运行原生SQL的方法,我这里列举三种 方法一 这也是网上流传最广的方法,但是我个人认为这个方法并不优雅,且采用${}的方式代码审计可能会无法通过,会被作为代码漏洞 public interface BaseMapper<T> extends com.baomidou.mybatisplus.core.mapper.BaseMa