基于LinkedHashMap实现LRU缓存
目录
- 概述
- 分析
- LRU缓存实现
- 总结
概述
LinkedHashMap是Java集合中一个常用的容器,它继承了HashMap, 是一个有序的Hash表。那么该如何基于LinkedHashMap实现一个LRU缓存呢?这也是面试经常被问到的题目,主要是考察你对Java集合容器的了解程度以及LinkedHashMap的实现原理。
分析
什么是LRU?
LRU(Least Recently Used)指的是最近最少使用,是一种缓存淘汰算法,淘汰掉那个最少使用的的数据。
- LinkedHashMap是有序的,它默认通过双向链表维护元素的插入顺序,同时,通过构造函数设置accessOrder属性为true的情况,维护元素的访问顺序,这里的访问包括插入、修改、查询等元素,每次操作都会记录顺序,所以LRU缓存其实是包括访问的,所以我们需要通过构造函数设置LinkedHashMap设置accessOrder为true。
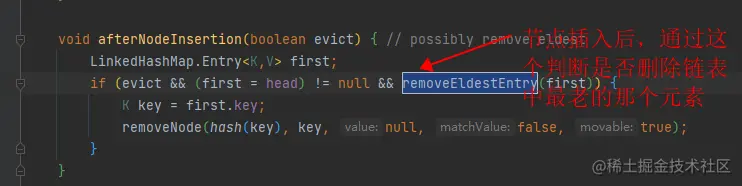
- 已经解决了顺序的问题,也就是最近访问的会在双向链表的尾部,最老的数据会在头部。那么如何删除头部的元素呢?其实LinkedHashMap也提供了一个回调函数removeEldestEntry,它也会在添加元素的时候调用, 默认返回false,我们可以通过重写这个方法的逻辑,如果LinkedHashMap大于缓存指定数量,就进行淘汰。
LRU缓存实现
场景:我们需要设计一个缓存最多只能存储10个元素,当元素个数超过10的时候,删除(淘汰)那些最近最少使用的数据,仅保存热点数据。
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
/**
* 缓存允许的最大容量
*/
private final int maxSize;
public LRUCache(int initialCapacity, int maxSize) {
// accessOrder必须为true
super(initialCapacity, 0.75f, true);
this.maxSize = maxSize;
}
// 重写
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当键值对个数超过最大容量时,返回true,触发删除操作
return size() > maxSize;
}
public static void main(String[] args) {
LRUCache<String, String> cache = new LRUCache<>(5, 5);
cache.put("1", "1");
cache.put("2", "2");
cache.put("3", "3");
cache.put("4", "4");
// 做一次查询
cache.get("1");
cache.put("5", "5");
cache.put("6", "6");
cache.put("7", "7");
System.out.println(cache);
}
}
运行结果:
{4=4, 1=1, 5=5, 6=6, 7=7}
因为做了一次cache.get("1"),相当于操作了1这个元素,变"新"了,所以只能淘汰3, 4。
总结
通过本文想必大家对LinkedHashMap有了更深的了解,可以用它来实现一个LRU缓存,实际上,通过LinkedHashMap实现LRU还是挺常见的,比如logback框架的LRUMessageCache。
到此这篇关于基于LinkedHashMap实现LRU缓存的文章就介绍到这了,更多相关LinkedHashMap实现LRU缓存内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解Java LinkedHashMap与HashMap的使用
目录 HashMap存储自定义类型键值 LinkedHashMap Map集合练习 JDK9对集合添加的优化 HashMap存储自定义类型键值 练习:每位学生(姓名,年龄)都有自己的家庭住址.那么,既然有对应关系,则将学生对象和家庭住址存储到map集合中.学生作为键, 家庭住址作为值. 注意,学生姓名相同并且年龄相同视为同一名学生. 编写学生类: public class Student { private String name; private int age; public Student
-
LinkedHashMap如何保证有序问题
目录 LinkedHashMap如何保证有序 属性信息 AccessOrder newNode() 按访问顺序有序 LinkedHashMap实现有序的原理 LinkedHashMap如何保证有序 我们常说linkedHashMap是有序的,这个有序也是分为两种的,分别是:插入顺序和访问顺序,我们可以通俗的认为:linkedHashMap = hashmap + 双向链表 以下的学习是基于jdk8 根据linkedHashMap的结构来看,是依赖于hashmap的,通过查看源码,我们也会发现,l
-
Java LinkedHashMap深入分析源码
目录 一.LinkedHashMap的类继承关系 二.源码分析 1.自己对LinkedHashMap的理解 2.如何做到双向链的增删改查 (1).增 (2).删 (3).改 (4).查 3.遍历 一.LinkedHashMap的类继承关系 二.源码分析 1.自己对LinkedHashMap的理解 从继承关系上,我们看到LinkedHashMap继承了HashMap,它里面的增删改差遍历的逻辑都是使用的HashMap中的,但是LinkedHashMap比HashMap多了一个双向链,这个双向链是从
-
详解Java实现LRU缓存
LRU是Least Recently Used 的缩写,翻译过来就是"最近最少使用",LRU缓存就是使用这种原理实现,简单的说就是缓存一定量的数据,当超过设定的阈值时就把一些过期的数据删除掉,比如我们缓存10000条数据,当数据小于10000时可以随意添加,当超过10000时就需要把新的数据添加进来,同时要把过期数据删除,以确保我们最大缓存10000条,那怎么确定删除哪条过期数据呢,采用LRU算法实现的话就是将最老的数据删掉,废话不多说,下面来说下Java版的LRU缓存实现 Java里
-
Java实现LRU缓存的实例详解
Java实现LRU缓存的实例详解 1.Cache Cache对于代码系统的加速与优化具有极大的作用,对于码农来说是一个很熟悉的概念.可以说,你在内存中new 了一个一段空间(比方说数组,list)存放一些冗余的结果数据,并利用这些数据完成了以空间换时间的优化目的,你就已经使用了cache. 有服务级的缓存框架,如memcache,Redis等.其实,很多时候,我们在自己同一个服务内,或者单个进程内也需要缓存,例如,lucene就对搜索做了缓存,而无须依赖外界.那么,我们如何实现我们自己的缓存?还
-
Java和Android的LRU缓存及实现原理
一.概述 Android提供了LRUCache类,可以方便的使用它来实现LRU算法的缓存.Java提供了LinkedHashMap,可以用该类很方便的实现LRU算法,Java的LRULinkedHashMap就是直接继承了LinkedHashMap,进行了极少的改动后就可以实现LRU算法. 二.Java的LRU算法 Java的LRU算法的基础是LinkedHashMap,LinkedHashMap继承了HashMap,并且在HashMap的基础上进行了一定的改动,以实现LRU算法. 1.Hash
-
基于Nginx的Mencached缓存配置详解
简介 memcached是一套分布式的高速缓存系统,memcached缺乏认证以及安全管制,这代表应该将memcached服务器放置在防火墙后.memcached的API使用三十二比特的循环冗余校验(CRC-32)计算键值后,将数据分散在不同的机器上.当表格满了以后,接下来新增的数据会以LRU机制替换掉.由于memcached通常只是当作缓存系统使用,所以使用memcached的应用程序在写回较慢的系统时(像是后端的数据库)需要额外的代码更新memcached内的数据 特征 memcached作
-

手动实现Redis的LRU缓存机制示例详解
前言 最近在逛博客的时候看到了有关Redis方面的面试题,其中提到了Redis在内存达到最大限制的时候会使用LRU等淘汰机制,然后找了这方面的一些资料与大家分享一下. LRU总体大概是这样的,最近使用的放在前面,最近没用的放在后面,如果来了一个新的数,此时内存满了,就需要把旧的数淘汰,那为了方便移动数据,肯定就得使用链表类似的数据结构,再加上要判断这条数据是不是最新的或者最旧的那么应该也要使用hashmap等key-value形式的数据结构. 第一种实现(使用LinkedHashMap) pub
-
Java手动实现Redis的LRU缓存机制
前言 最近在逛博客的时候看到了有关Redis方面的面试题,其中提到了Redis在内存达到最大限制的时候会使用LRU等淘汰机制,然后找了这方面的一些资料与大家分享一下. LRU总体大概是这样的,最近使用的放在前面,最近没用的放在后面,如果来了一个新的数,此时内存满了,就需要把旧的数淘汰,那为了方便移动数据,肯定就得使用链表类似的数据结构,再加上要判断这条数据是不是最新的或者最旧的那么应该也要使用hashmap等key-value形式的数据结构. 第一种实现(使用LinkedHashMap) pub
-
Java 手写LRU缓存淘汰算法
概述 LRU 算法全称为 Least Recently Used 是一种常见的页面缓存淘汰算法,当缓存空间达到达到预设空间的情况下会删除那些最久没有被使用的数据 . 常见的页面缓存淘汰算法主要有一下几种: LRU 最近最久未使用 FIFO 先进先出置换算法 类似队列 OPT 最佳置换算法 (理想中存在的) NRU Clock 置换算法 LFU 最少使用置换算法 PBA 页面缓冲算法 LRU 的原理 LRU 算法的设计原理其实就是计算机的 局部性原理(这个 局部性原理 包含了 空间局部性 和 时间
-
浅谈java如何实现Redis的LRU缓存机制
目录 LRU概述 使用LinkedHashMap实现 使用LinkedHashMap简单方法实现 双链表+hashmap LRU概述 最近使用的放在前面,最近没用的放在后面,如果来了一个新的数,此时内存满了,就需要把旧的数淘汰,那为了方便移动数据,肯定就得使用链表类似的数据结构,再加上要判断这条数据是不是最新的或者最旧的那么应该也要使用hashmap等key-value形式的数据结构. 使用LinkedHashMap实现 package thread; import java.util.Link
-
Python 如何手动编写一个自己的LRU缓存装饰器的方法实现
LRU缓存算法,指的是近期最少使用算法,大体逻辑就是淘汰最长时间没有用的那个缓存,这里我们使用有序字典,来实现自己的LRU缓存算法,并将其包装成一个装饰器. 1.首先创建一个my_cache.py文件 编写自己我们自己的LRU缓存算法,代码如下: import time from collections import OrderedDict ''' 基于LRU,近期最少用缓存算法写的装饰器. ''' class LRUCacheDict: def __init__(self, max_size=
-
Python使用LRU缓存策略进行缓存的方法步骤
目录 一.Python 缓存 ① 缓存作用 ② 使用 Python 字典实现缓存 二.深入理解 LRU 算法 ① 查看 LRU 缓存的特点 ② 查看 LRU 缓存的结构 三.使用 lru_cache 装饰器 ① @lru_cache 装饰器的实现原理 ② 斐波拉契数列 ③ 使用 @lru_cache 缓存输出结果 ④ 限制 @lru_cache 装饰器大小 ⑤ 使用 @lru_cache 实现 LRU 缓存 ⑥ 解包 @lru_cache 的功能 四.添加缓存过期 五.@lru_cache 装饰