Pandas数据分析之groupby函数用法实例详解
目录
- 正文
- 一、了解groupby
- 二、数据文件简介
- 三、求各个商品购买量
- 四、求各个商品转化率
- 五、转化率最高的30个商品及其转化率
- 小小の总结
正文
今天本人在赶学校课程作业的时候突然发现groupby这个分组函数还是蛮有用的,有了这个分组之后你可以实现很多统计目标。
当然,最主要的是,他的使用非常简单
本期我们以上期作业为例,单走一篇文章来看看这个函数可以实现哪些功能:
(本期需要准备的行囊):
- jupyter notebook环境(anaconda自带)
- pandas第三方库
- numpy第三方库(也许会用吧)
- 能运行以上依赖的电脑和舒服的外设
- 一定的python基础
- 需要是吃饱喝足的你,带上能运作的小脑瓜来继续
一、了解groupby
这是一个函数,一般作用于dataframe上,有返回值,不改变原变量。输出的是原dataframe按照传入参数分组后的结果。
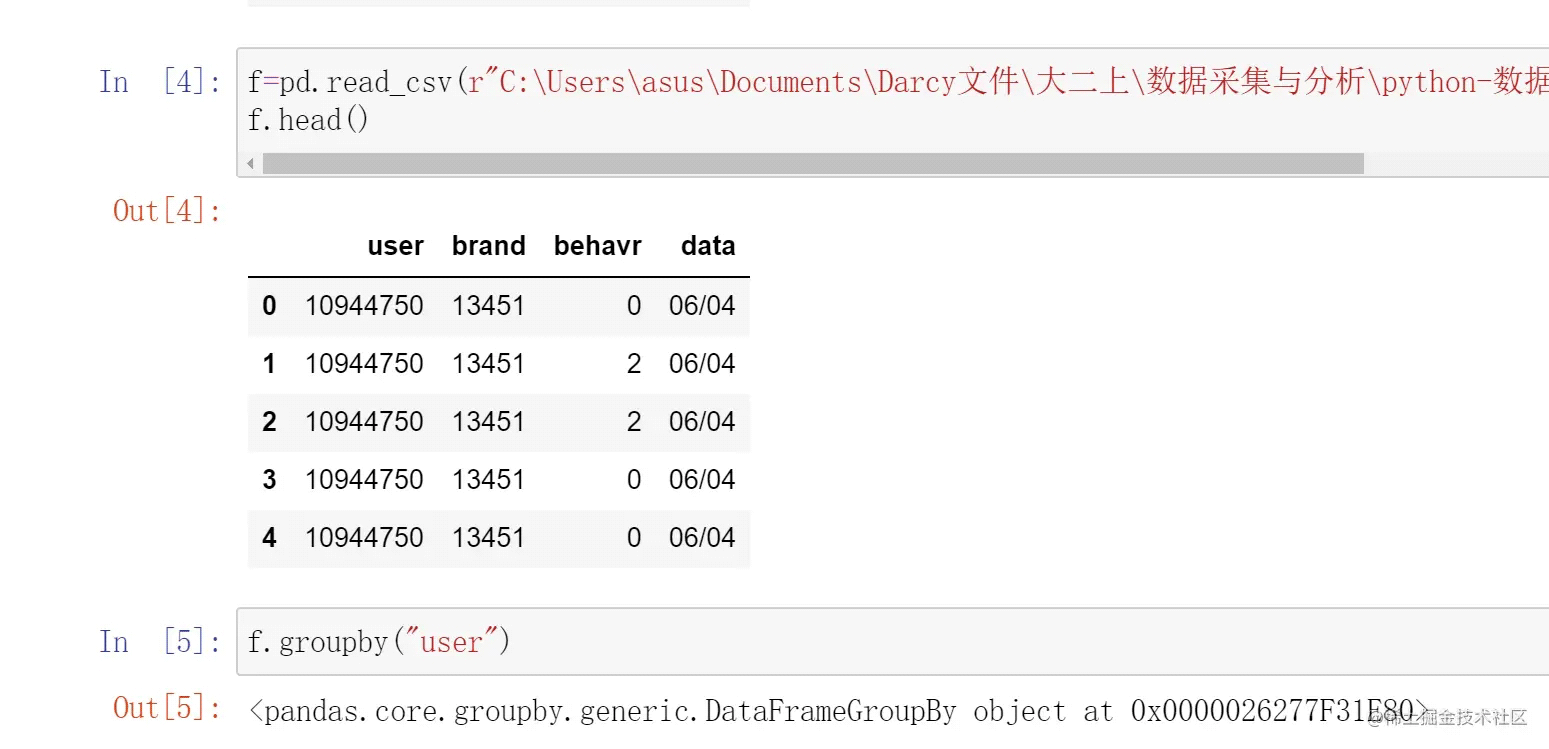
我们一通引入获得了一个dataframe,按照“user”进行了分组,发现得到的是一个dataframegroupby对象。这个对象内部是什么呢?我们用遍历循环来看看:
for i in f.groupby("user"):
print(i)
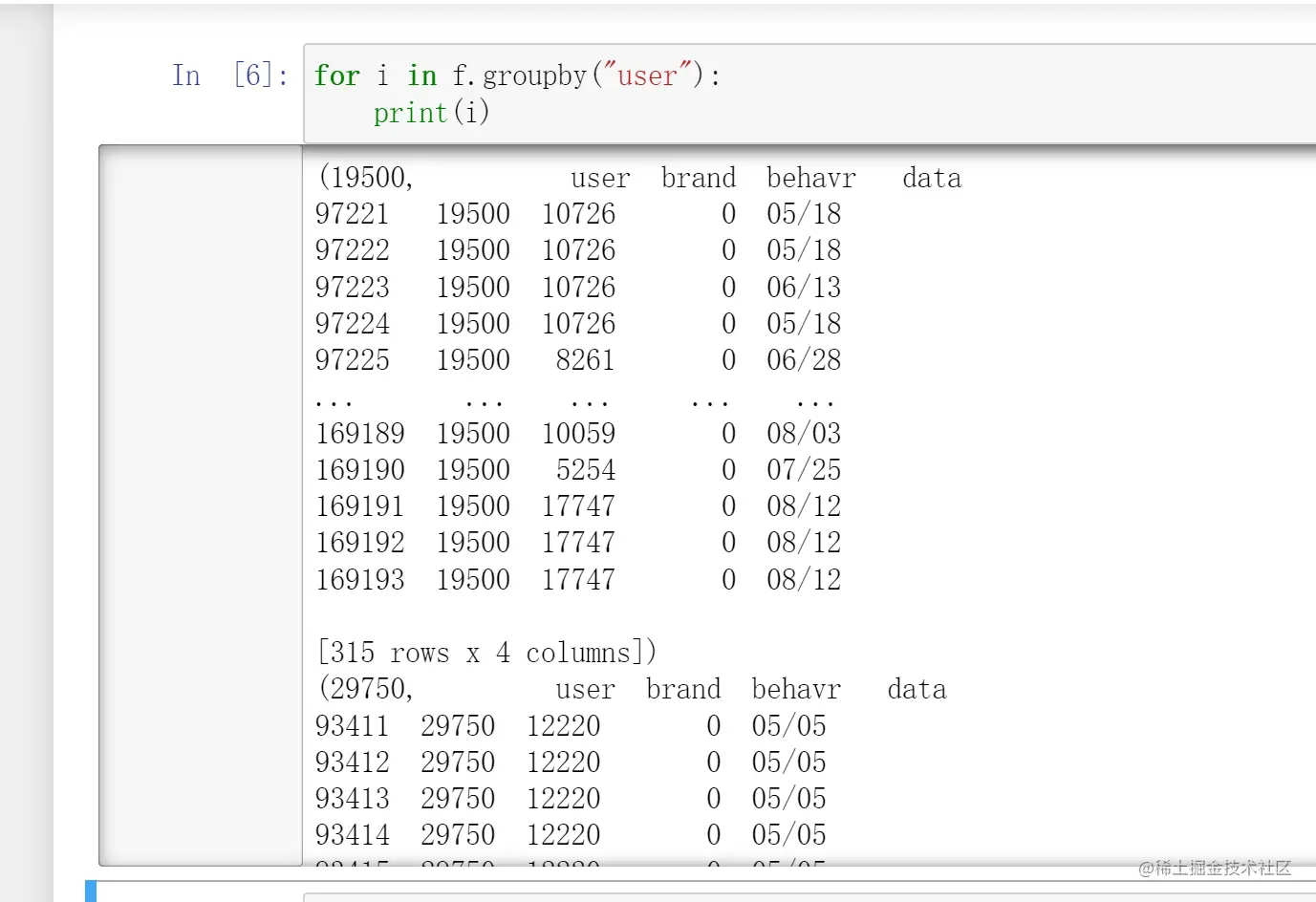
发现这个对象内部是一个个元组,每个元组的第一个元素是我们设定的分组依据的值
(例如这里我们设定的分组依据是user,这里第一个元组包含的是user为19500时的所有记录,元组第一个元素就是19500)
而当我们输出元组里的第二个元素的时候,发现得到的是类似dataframe的结果
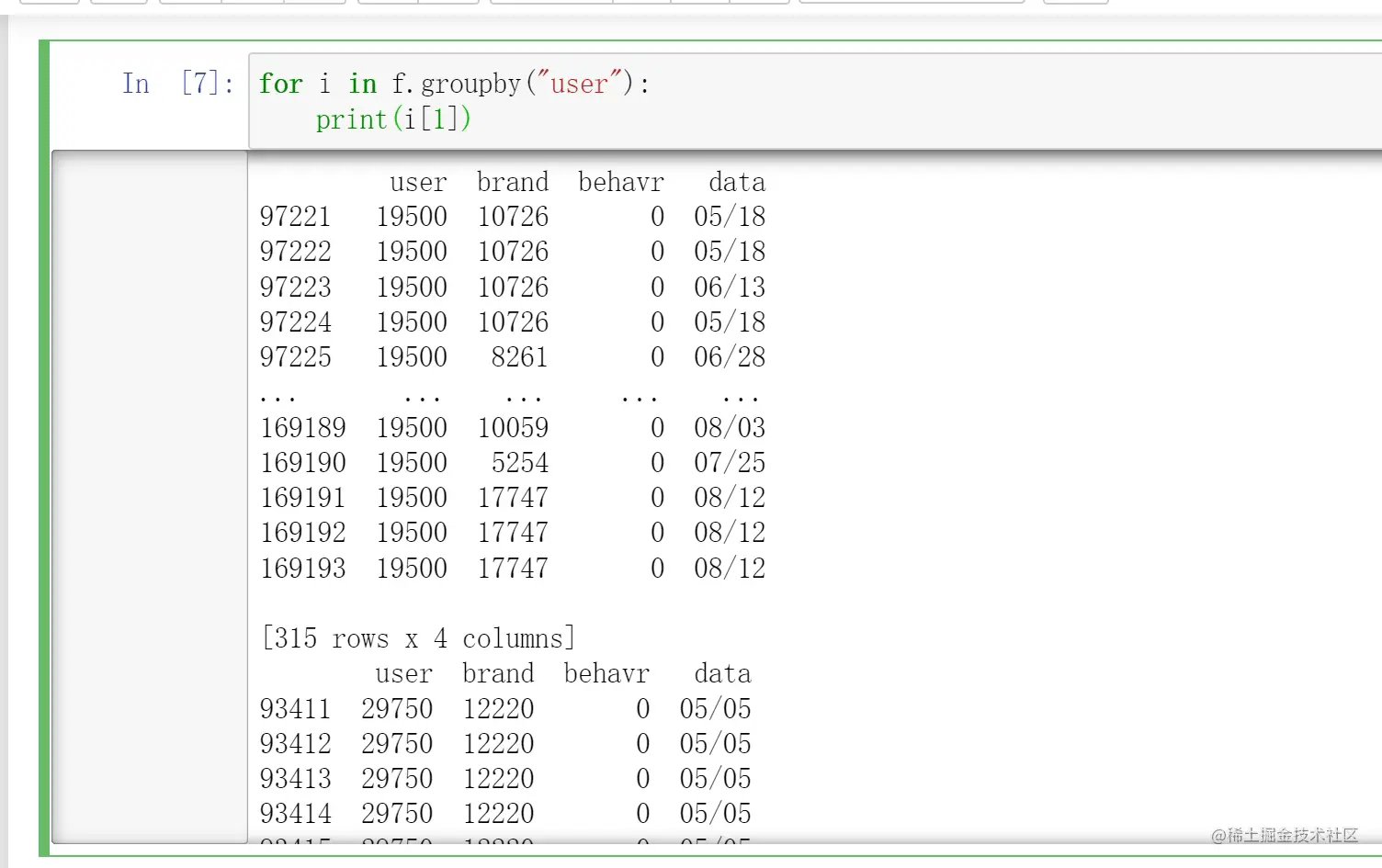
看前面user下面的数据,整齐划一,是不是?o(〃^▽^〃)o
二、数据文件简介
文章中所用数据为某时段内消费者的行为数据。user为消费者编号,brand为品牌编号,behavr为消费者行为(0代表浏览,1代表购买,2代表收藏,3代表加入购物车。且允许存在不浏览直接购买的行为)
接下来我们要针对这些数据进行处理,输出一些有用的结果
三、求各个商品购买量
因为要求统计的“购买”行为属于behavr列中的某特殊值。很容易想到先用条件筛选选出所有购买的记录,再用groupby按各个商品分类,再用size()方法统计分组后每组的数量,以此输出各个商品的购买量。
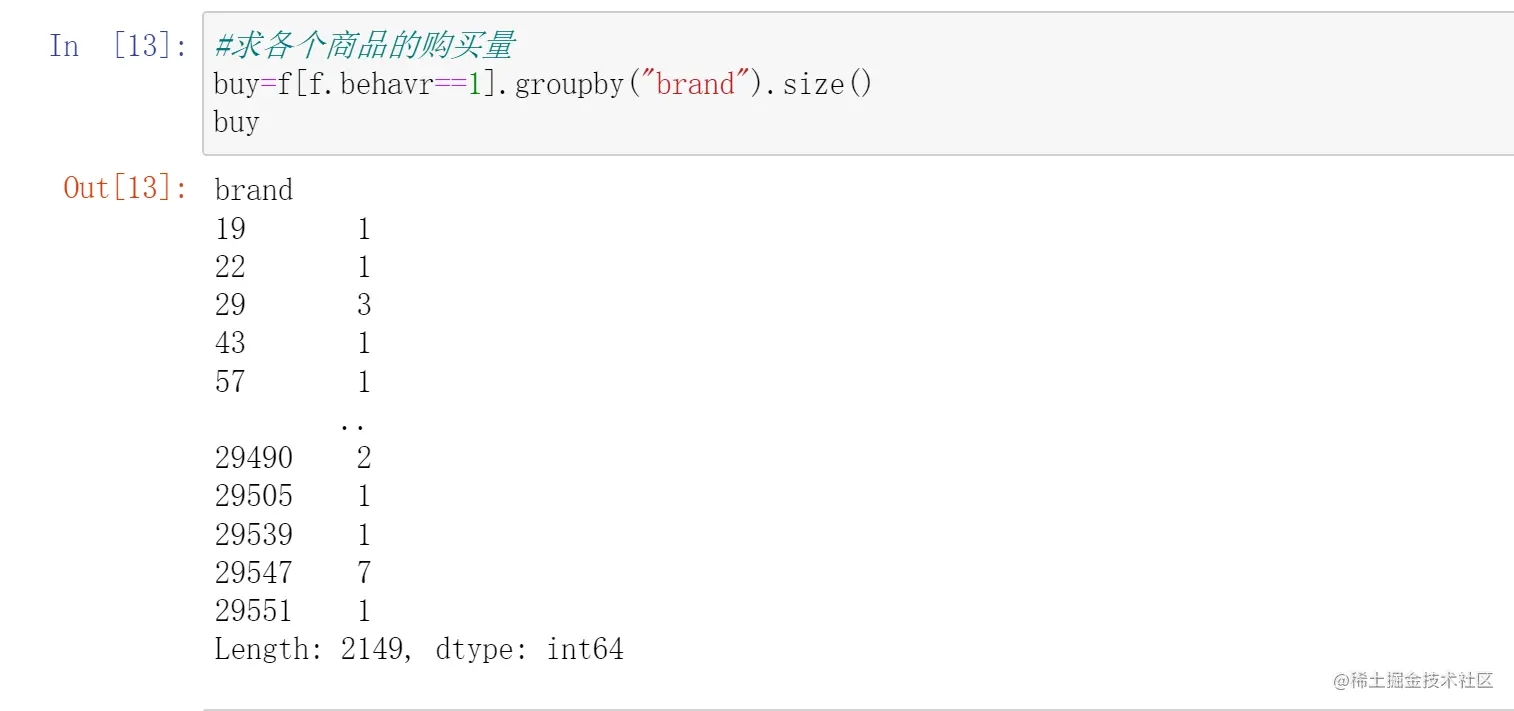
那么会了这个之后来举一反三一下:求各个商品浏览量
自行思考一下再往下翻哦
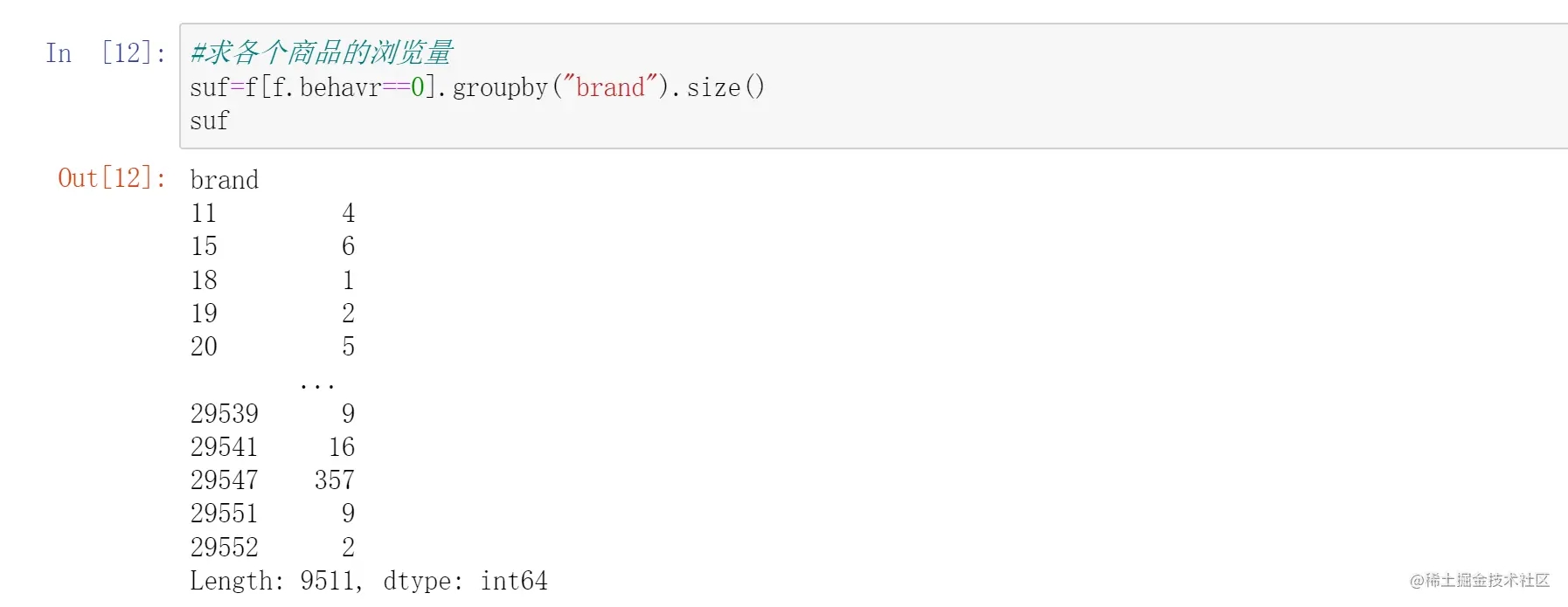
没错,就是改一下一开始条件过滤的数值即可。把购买(1)改成浏览(0)
四、求各个商品转化率
商业数据分析经常会遇到一个数据量——转化率,其实就是购买的数量比上浏览的数量。以此来看这个商品是否足够吸引人。
我们这里在上面已经计算出了各个商品的浏览量和购买量,事实上只需要比一比就可以了。
正好,pandas的series计算是我们想要的,他会根据键值对去分别计算
这个series里user名字是键,数量是值,非常完美符合series计算设定,我们直接除一下就行。
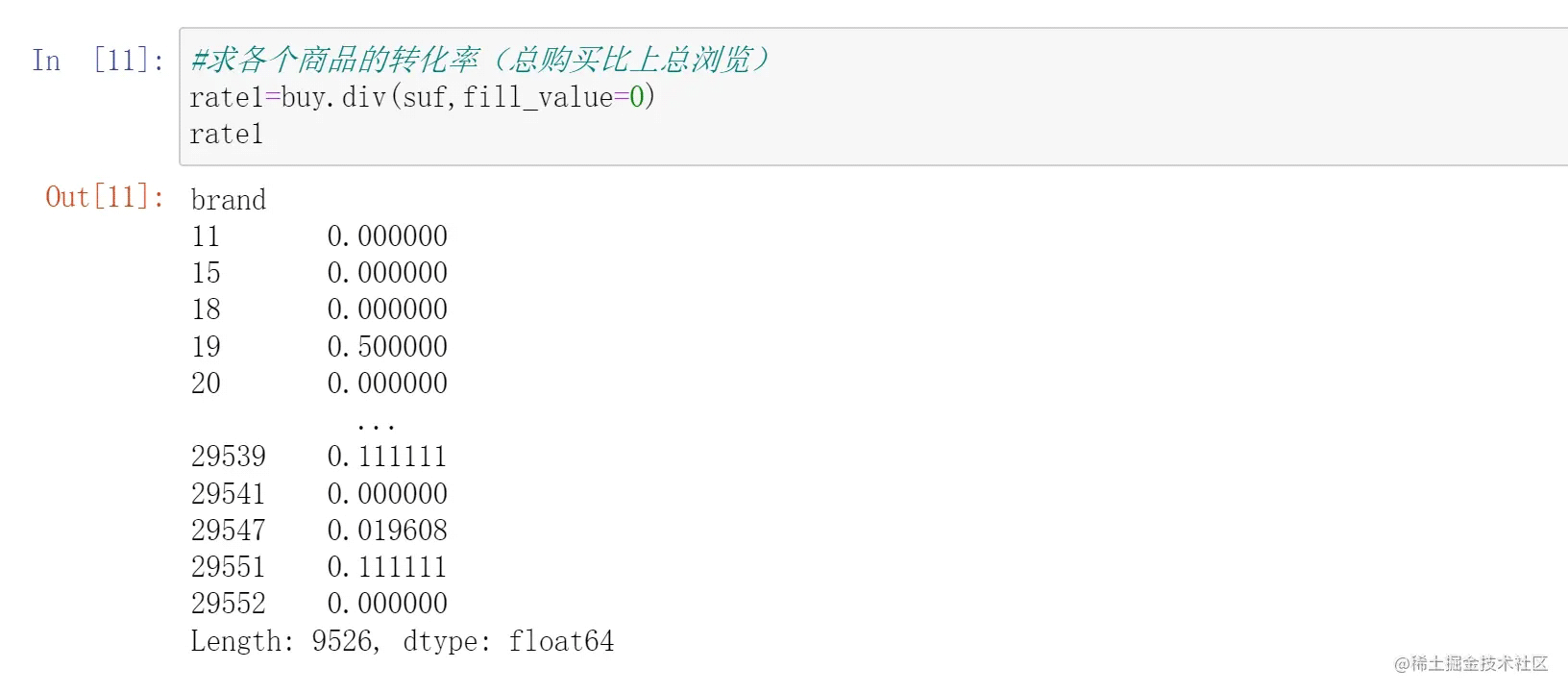
pandas用.div()来实现比值功能(前面的比后面的)。
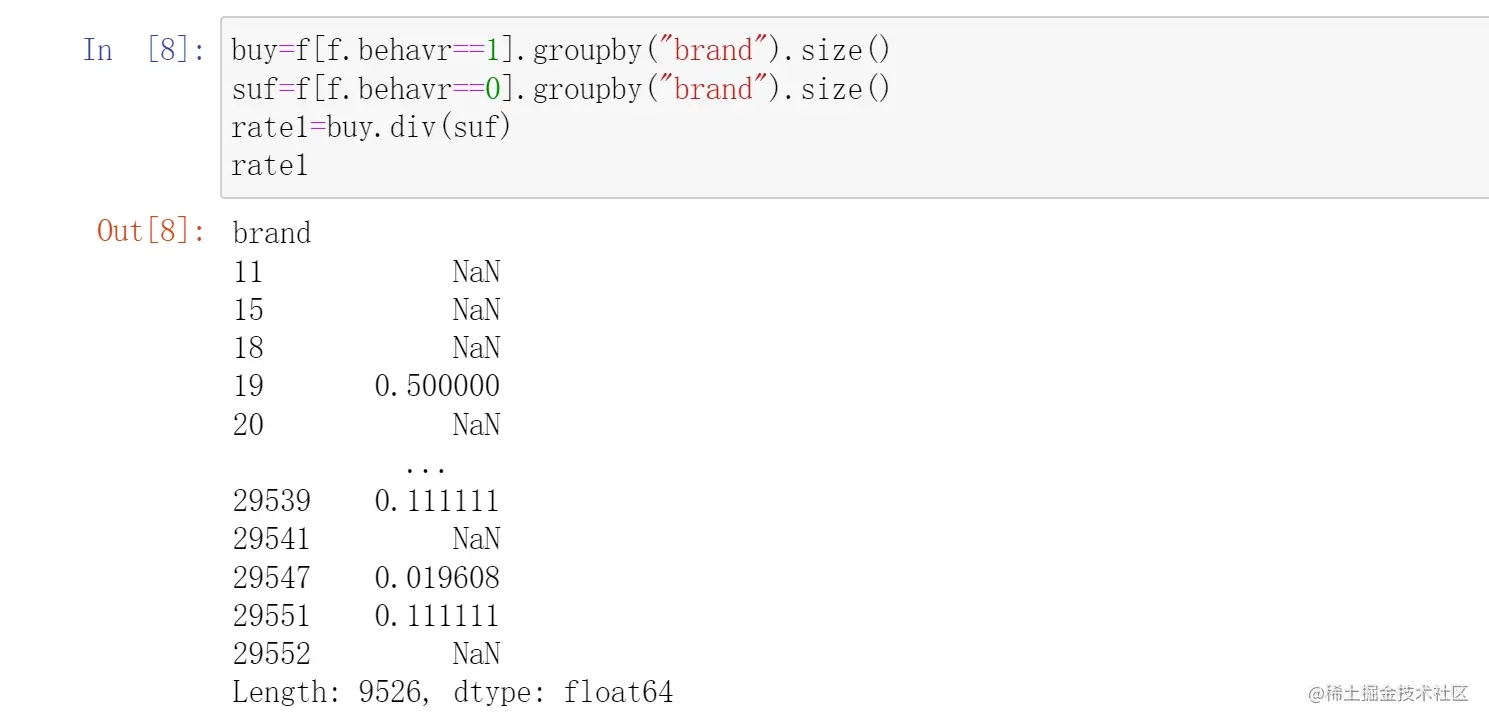
要注意的是,series计算可能会带来缺失值,因为两个series计算的时候并不能保证两个series的键完全一样
即有可能出现前一个series有的键而后一个没有。比如这里可以看出brand 11就只有浏览没有购买,因此统计购买量的时候没有11这个键,但是浏览量中有11这个键。
在计算的时候不共有的键会以缺失值的形式出现,即NaN:
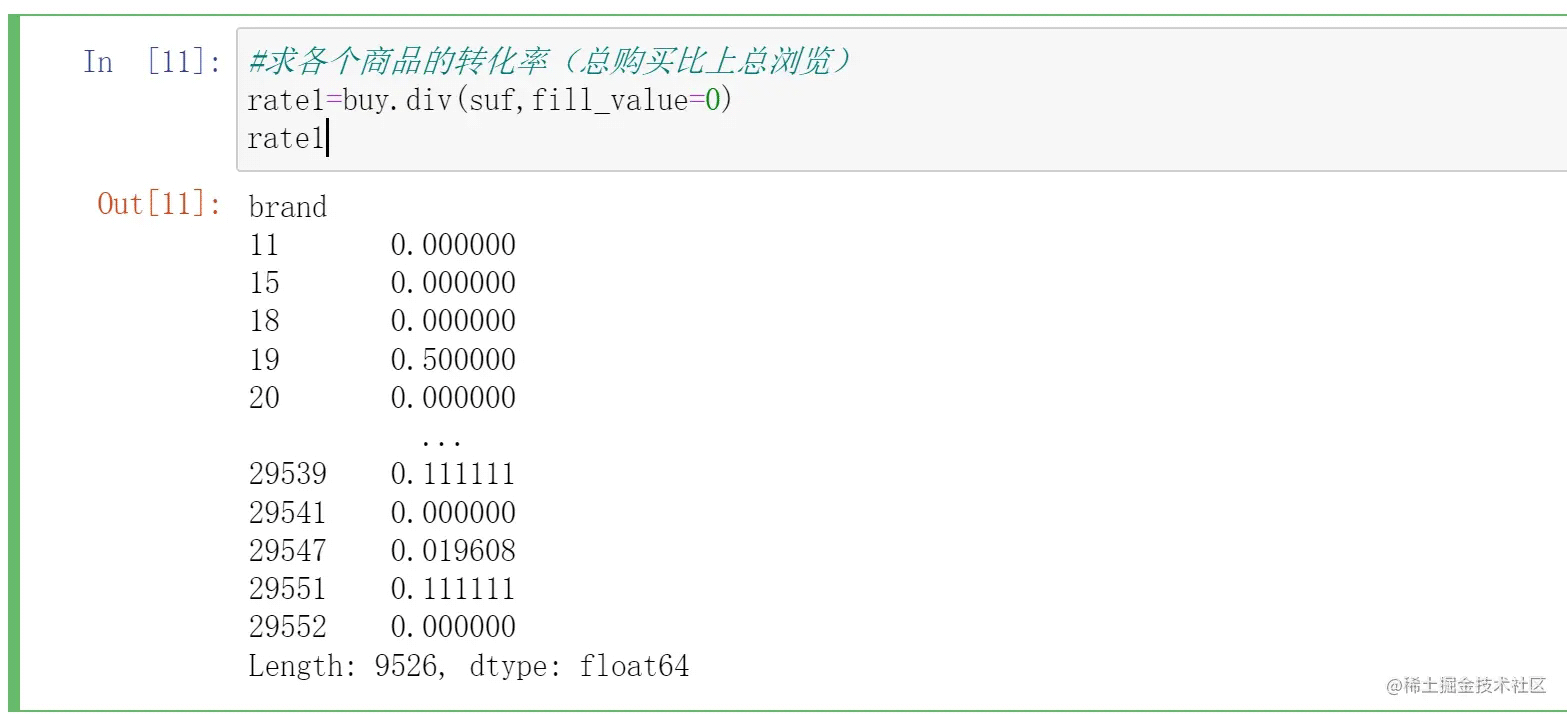
如果我们不想看到这个缺失值NaN,在div内添加fill_value参数可以把缺失值补充上
五、转化率最高的30个商品及其转化率
这就需要用到排序了。其实也很简单。我们把前面计算好的转化率用sort_values()函数排序之后输出前30个即可:
- sort_value()函数中设置ascending参数为False即为降序,默认为True升序
- head(n)用来输出前n个,同理tail(n)用来输出最后n个
小小の总结
其实我们不难发现,python语言其实本身过于“高级”。他不需要你思考用什么算法来完成这些操作(特别是你本身还在用第三方库的时候)。
她总有相关的函数或者方法可以替你完成。并且这个函数内部可能是C语言等基础语言实现的,代码效率会比你自己在python上手码要快很多
作为使用者,想要快速入门的话,你所需要的——
只是把这些都记住就行了
大概这就是一个像文科一样的编程语言吧……
以上就是Pandas数据分析之groupby函数用法实例详解的详细内容,更多关于Pandas数据分析groupby函数的资料请关注我们其它相关文章!
相关推荐
-
Pandas实现groupby分组统计的实践
目录 1.创建数据和导入包 2.分组使用聚合函数做数据统计 3.遍历groupby的结果理解执行流程 4.实例分组探索天气数据 类似SQL:select city,max(temperature) from city_weather group by city; groupby:先对数据分组,然后在每个分组上应用聚合函数.转换函数 本次演示:一.分组使用聚合函数做数据统计二.遍历groupby的结果理解执行流程三.实例分组探索天气数据 1.创建数据和导入包 import pandas as pd
-
详解Pandas中GroupBy对象的使用
目录 使用 Groupby 三个步骤 将原始对象拆分为组 按组应用函数 Aggregation Transformation Filtration 整合结果 总结 今天,我们将探讨如何在 Python 的 Pandas 库中创建 GroupBy 对象以及该对象的工作原理.我们将详细了解分组过程的每个步骤,可以将哪些方法应用于 GroupBy 对象上,以及我们可以从中提取哪些有用信息 不要再观望了,一起学起来吧 使用 Groupby 三个步骤 首先我们要知道,任何 groupby 过程都涉及以下
-

Pandas中的 transform()结合 groupby()用法示例详解
首先,假设我们有如下餐厅数据集: import pandas as pd df = pd.DataFrame({ 'restaurant_id': [101,102,103,104,105,106,107], 'address': ['A','B','C','D', 'E', 'F', 'G'], 'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'], 'sales': [10,500,48,12,2
-
pandas中pd.groupby()的用法详解
在pandas中的groupby和在sql语句中的groupby有异曲同工之妙,不过也难怪,毕竟关系数据库中的存放数据的结构也是一张大表罢了,与dataframe的形式相似. import numpy as np import pandas as pd from pandas import Series, DataFrame df = pd.read_csv('./city_weather.csv') print(df) ''' date city temperature
-
pandas的排序、分组groupby及cumsum累计求和方式
目录 生成一列sum_age 对age 进行累加 生成一列sum_age_new 按照 gender和is_good 对age进行累加 根据不同的性别对年龄进行 等级 排序 对数据排序之后,分组,并累计求和 pandas分组排序功能 生成一列sum_age 对age 进行累加 df['sum_age'] = df['age'].cumsum() print(df) 生成一列sum_age_new 按照 gender和is_good 对age进行累加 df['sum_age_new'] = df.
-
Pandas中GroupBy具体用法详解
目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 同时使用多个聚合方法 NamedAgg 不同的列指定不同的聚合方法 转换操作 过滤操作 Apply操作 简介 pandas中的DF数据类型可以像数据库表格一样进行groupby操作.通常来说groupby操作可以分为三部分:分割数据,应用变换和和合并数据. 本文将会详细讲解Pandas中的groupby操作. 分割数据 分割数据的目的是将DF分割成为
-
Pandas数据分析之groupby函数用法实例详解
目录 正文 一.了解groupby 二.数据文件简介 三.求各个商品购买量 四.求各个商品转化率 五.转化率最高的30个商品及其转化率 小小の总结 正文 今天本人在赶学校课程作业的时候突然发现groupby这个分组函数还是蛮有用的,有了这个分组之后你可以实现很多统计目标. 当然,最主要的是,他的使用非常简单 本期我们以上期作业为例,单走一篇文章来看看这个函数可以实现哪些功能: (本期需要准备的行囊): jupyter notebook环境(anaconda自带) pandas第三方库 numpy
-
Python文件操作函数用法实例详解
这篇文章主要介绍了Python文件操作函数用法实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 字符编码 二进制和字符之间的转换过程 --> 字符编码 ascii,gbk,shit,fuck 每个国家都有自己的编码方式 美国电脑内存中的编码方式为ascii ; 中国电脑内存中的编码方式为gbk , 美国电脑无法识别中国电脑写的程序 , 中国电脑无法识别美国电脑写的程序 现在硬盘中躺着 ascii/gbk/shit/fuck 编码的文件,
-
python scatter函数用法实例详解
这篇文章主要介绍了python scatter函数用法实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 函数功能:寻找变量之间的关系. 调用签名:plt.scatter(x, y, c="b", label="scatter figure") x: x轴上的数值 y: y轴上的数值 c:散点图中的标记的颜色 label:标记图形内容的标签文本 代码实现: import matplotlib.pyplot as
-
Python3.2中Print函数用法实例详解
本文实例讲述了Python3.2中Print函数用法.分享给大家供大家参考.具体分析如下: 1. 输出字符串 >>> strHello = 'Hello World' >>> print (strHello) Hello World 2. 格式化输出整数 支持参数格式化,与C语言的printf类似 >>> strHello = "the length of (%s) is %d" %('Hello World',len('Hello
-
ES6新特性八:async函数用法实例详解
本文实例讲述了ES6新特性之async函数用法.分享给大家供大家参考,具体如下: 1. async 函数是什么? node.js 版本7及之后版本才支持该函数. 可以简单的理解为他是Generator 函数的语法糖,即Generator 函数调用next() 返回的结果. ① Generator 函数需要next() 或执行器进行执行,而async 函数只需和普通函数一样执行. ② async和await,比起星号和yield,语义更清楚了.async表示函数里有异步操作,await表示紧跟在后
-
PHP中spl_autoload_register()函数用法实例详解
本文实例分析了PHP中spl_autoload_register()函数用法.分享给大家供大家参考,具体如下: 在了解这个函数之前先来看另一个函数:__autoload. 一.__autoload 这是一个自动加载函数,在PHP5中,当我们实例化一个未定义的类时,就会触发此函数.看下面例子: printit.class.php: <?php class PRINTIT { function doPrint() { echo 'hello world'; } } ?> index.php <
-
jQuery中attr()与prop()函数用法实例详解(附用法区别)
本文实例讲述了jQuery中attr()与prop()函数用法.分享给大家供大家参考,具体如下: 一.jQuery的attr()方法 jquery中用attr()方法来获取和设置元素属性,attr是attribute(属性)的缩写,在jQuery DOM操作中会经常用到attr(),attr()有4个表达式. 1. attr(属性名) //获取属性的值(取得第一个匹配元素的属性值.通过这个方法可以方便地从第一个匹配元素中获取一个属性的值.如果元素没有相应属性,则返回 undefined ) 2.
-
Python回调函数用法实例详解
本文实例讲述了Python回调函数用法.分享给大家供大家参考.具体分析如下: 一.百度百科上对回调函数的解释: 回调函数就是一个通过函数指针调用的函数.如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用为调用它所指向的函数时,我们就说这是回调函数.回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应. 二.什么是回调: 软件模块之间总是存在着一定的接口,从调用方式上,可以把他们分为三类:同步调用.回调和异步调用.同步调用
-
es6函数之箭头函数用法实例详解
本文实例讲述了es6函数之箭头函数用法.分享给大家供大家参考,具体如下: es6允许使用"箭头"(=>)定义函数. var f = v => v // 等同于 var f = function(v) { return v } 如果箭头函数不需要参数或需要多个参数,就使用一个圆括号代表参数部分. var f = () => 5 // 等同于 var f = function() { return 5 } var sum = (num1, num2) => num1
-
pytorch中permute()函数用法实例详解
目录 前言 三维情况 变化一:不改变任何参数 变化二:1与2交换 变化三:0与1交换 变化四:0与2交换 变化五:0与1交换,1与2交换 变化六:0与1交换,0与2交换 总结 前言 本文只讨论二维三维中的permute用法 最近的Attention学习中的一个permute函数让我不理解 这个光说太抽象 我就结合代码与图片解释一下 首先创建一个三维数组小实例 import torch x = torch.linspace(1, 30, steps=30).view(3,2,5) # 设置一个三维