LyScript实现计算片段Hash并写出Excel的示例代码
本案例将学习运用LyScript计算特定程序中特定某些片段的Hash特征值,并通过xlsxwriter这个第三方模块将计算到的hash值存储成一个excel表格,本例中的知识点可以说已经具备了简单的表格输出能力,如果时间充裕完全可以实现自动化报告生成。
第一步实现计算特定片段的特征值,此类代码实现原理用户传入一个rva相对地址以及读入指令长度,并通过内置的hashlib库实现计算内存段内指令的特征,如下代码先来实现计算两段指令特征。
import hashlib
import zlib,binascii
from LyScript32 import MyDebug
# 计算哈希
def calc_hash(dbg, rva,size):
read_list = bytearray()
ref_hash = { "va": None, "size": None, "md5":None, "sha256":None, "sha512":None, "crc32":None }
# 得到基地址
base = dbg.get_local_module_base()
# 读入数据
for index in range(0,size):
readbyte = dbg.read_memory_byte(base + rva + index)
read_list.append(readbyte)
# 计算特征
md5hash = hashlib.md5(read_list)
sha512hash = hashlib.sha512(read_list)
sha256hash = hashlib.sha256(read_list)
# crc32hash = binascii.crc32(read_list) & 0xffffffff
ref_hash["va"] = hex(base+rva)
ref_hash["size"] = size
ref_hash["md5"] = md5hash.hexdigest()
ref_hash["sha256"] = sha256hash.hexdigest()
ref_hash["sha512"] = sha512hash.hexdigest()
ref_hash["crc32"] = hex(zlib.crc32(read_list))
return ref_hash
if __name__ == "__main__":
dbg = MyDebug()
connect = dbg.connect()
# 传入相对地址,计算计算字节
ref = calc_hash(dbg,0x19fd,10)
print(ref)
# 计算第二段
ref = calc_hash(dbg,0x1030,26)
print(ref)
dbg.close()
计算后输出字典格式:

第二部使用第三方库,将读入的hash参数写出到表格内,并在下方生成hash图例,方便观察。
import hashlib
import time
import zlib,binascii
from LyScript32 import MyDebug
import xlsxwriter
# 计算哈希
def calc_hash(dbg, rva,size):
read_list = bytearray()
ref_hash = { "va": None, "size": None, "md5":None, "sha256":None, "sha512":None, "crc32":None }
# 得到基地址
base = dbg.get_local_module_base()
# 读入数据
for index in range(0,size):
readbyte = dbg.read_memory_byte(base + rva + index)
read_list.append(readbyte)
# 计算特征
md5hash = hashlib.md5(read_list)
sha512hash = hashlib.sha512(read_list)
sha256hash = hashlib.sha256(read_list)
# crc32hash = binascii.crc32(read_list) & 0xffffffff
ref_hash["va"] = hex(base+rva)
ref_hash["size"] = size
ref_hash["md5"] = md5hash.hexdigest()
ref_hash["sha256"] = sha256hash.hexdigest()
ref_hash["sha512"] = sha512hash.hexdigest()
ref_hash["crc32"] = hex(zlib.crc32(read_list))
return ref_hash
if __name__ == "__main__":
dbg = MyDebug()
connect = dbg.connect()
# 打开一个被调试进程
dbg.open_debug("D:\\Win32Project.exe")
# 传入相对地址,计算计算字节
ref = calc_hash(dbg,0x19fd,10)
print(ref)
ref2 = calc_hash(dbg,0x1030,26)
print(ref2)
ref3 = calc_hash(dbg,0x15EB,46)
print(ref3)
ref4 = calc_hash(dbg,0x172B,8)
print(ref4)
# 写出表格
workbook = xlsxwriter.Workbook("pe_hash.xlsx")
worksheet = workbook.add_worksheet()
headings = ["VA地址", "计算长度", "MD5", "SHA256", "SHA512","CRC32"]
data = [
[ref.get("va"),ref.get("size"),ref.get("md5"),ref.get("sha256"),ref.get("sha512"),ref.get("crc32")],
[ref2.get("va"), ref2.get("size"), ref2.get("md5"), ref2.get("sha256"), ref2.get("sha512"), ref2.get("crc32")],
[ref3.get("va"), ref3.get("size"), ref3.get("md5"), ref3.get("sha256"), ref3.get("sha512"), ref3.get("crc32")],
[ref4.get("va"), ref4.get("size"), ref4.get("md5"), ref4.get("sha256"), ref4.get("sha512"), ref4.get("crc32")]
]
# 定义表格样式
head_style = workbook.add_format({"bold": True, "align": "center", "fg_color": "#D7E4BC"})
worksheet.set_column("A1:F1", 15)
# 逐条写入数据
worksheet.write_row("A1", headings, head_style)
for i in range(0, len(data)):
worksheet.write_row("A{}".format(i + 2), data[i])
# 添加条形图,显示前十个元素
chart = workbook.add_chart({"type": "line"})
chart.add_series({
"name": "=Sheet1!$B$1", # 图例项
"categories": "=Sheet1!$A$2:$A$10", # X轴 Item名称
"values": "=Sheet1!$B$2:$B$10" # X轴Item值
})
chart.add_series({
"name": "=Sheet1!$C$1",
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$C$2:$C$10"
})
chart.add_series({
"name": "=Sheet1!$D$1",
"categories": "=Sheet1!$A$2:$A$10",
"values": "=Sheet1!$D$2:$D$10"
})
# 添加柱状图标题
chart.set_title({"name": "计算HASH统计图"})
# chart.set_style(8)
chart.set_size({'width': 500, 'height': 250})
chart.set_legend({'position': 'top'})
# 在F2处绘制
worksheet.insert_chart("H2", chart)
workbook.close()
# 关闭被调试进程
time.sleep(1)
dbg.close_debug()
dbg.close()
生成后的图例效果如下:
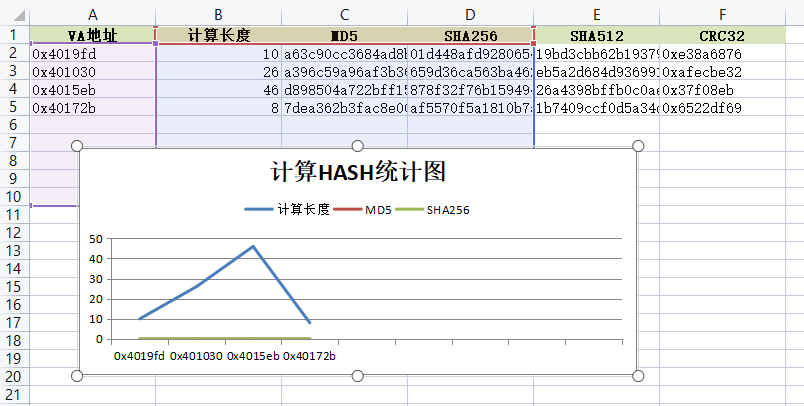
到此这篇关于LyScript实现计算片段Hash并写出Excel的示例代码的文章就介绍到这了,更多相关LyScript算片段Hash内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

LyScript实现对内存堆栈扫描的方法详解
LyScript插件中提供了三种基本的堆栈操作方法,其中push_stack用于入栈,pop_stack用于出栈,而最有用的是peek_stack函数,该函数可用于检查指定堆栈位置处的内存参数,利用这个特性就可以实现,对堆栈地址的检测,或对堆栈的扫描等. LyScript项目地址:https://github.com/lyshark/LyScript peek_stack命令传入的是堆栈下标位置默认从0开始,并输出一个十进制有符号长整数,首先实现有符号与无符号数之间的转换操作,为后续堆栈扫描做准
-
LyScript寻找ROP漏洞指令片段的方法详解
ROP绕过片段简单科普一下,你可以理解成一个可以关闭系统自身内存保护的一段机器指令,这段代码需要我们自己构造,这就涉及到在对端内存搜寻这样的指令,LyScript插件增强了指令片段的查找功能,但需要我们在LyScript插件基础上封装一些方法,实现起来也不难. LScript项目地址:https://github.com/lyshark/LyScript 封装机器码获取功能: 首先封装一个方法,当用户传入指定汇编指令的时候,自动的将其转换成对应的机器码,这是为搜索ROP片段做铺垫的,代码很简单,
-
LyScript实现绕过反调试保护的示例详解
LyScript插件中内置的方法可实现各类反调试以及屏蔽特定API函数的功能,这类功能在应对病毒等恶意程序时非常有效,例如当程序调用特定API函数时我们可以将其拦截,从而实现保护系统在调试时不被破坏的目的. LyScript项目地址: https://github.com/lyshark/LyScript 绕过反调试机制: 最常用的反调试机制就是用IsDebuggerPresent该标志检查PEB+2位置处的内容,如果为1则表示正在被调试,我们运行脚本直接将其设置为0即可绕过反调试机制. 也就是
-
通过LyScript实现从文本中读写ShellCode
LyScript 插件通过配合内存读写,可实现对特定位置的ShellCode代码的导出,或者将一段存储在文本中的ShellCode代码插入到程序堆中,此功能可用于快速将自己编写的ShellCode注入到目标进程中,以用于后续测试工作. LyScript项目地址:https://github.com/lyshark/LyScript 将本地ShellCode注入到堆中: 第一种用法是将一个本地文本中的ShellCode代码导入到堆中. 首先准备一个文本文件,将生成的shellcode放入文件内.
-
利用LyScript实现应用层钩子扫描器
Capstone 是一个轻量级的多平台.多架构的反汇编框架,该模块支持目前所有通用操作系统,反汇编架构几乎全部支持,本篇文章将运用LyScript插件结合Capstone反汇编引擎实现一个钩子扫描器. 要实现应用层钩子扫描,我们需要得到程序内存文件的机器码以及磁盘中的机器码,并通过capstone这个第三方反汇编引擎,对两者进行反汇编,最后逐条对比汇编指令,实现进程钩子扫描的效果. LyScript项目地址:https://github.com/lyshark/LyScript 通过LyScri
-
LyScript获取上一条与下一条汇编指令的方法详解
LyScript 插件默认并没有提供上一条与下一条汇编指令的获取功能,当然你可以使用LyScriptTools工具包直接调用内置命令得到,不过这种方式显然在效率上并不理想,我们需要在LyScript插件API基础上自己封装实现这个功能. LyScript项目地址:https://github.com/lyshark/LyScript 获取下一条汇编指令 下一条汇编指令的获取需要注意如果是被命中的指令则此处应该是CC断点占用一个字节,如果不是则正常获取到当前指令即可. 1.我们需要检查当前内存断点
-
LyScript实现计算片段Hash并写出Excel的示例代码
本案例将学习运用LyScript计算特定程序中特定某些片段的Hash特征值,并通过xlsxwriter这个第三方模块将计算到的hash值存储成一个excel表格,本例中的知识点可以说已经具备了简单的表格输出能力,如果时间充裕完全可以实现自动化报告生成. 第一步实现计算特定片段的特征值,此类代码实现原理用户传入一个rva相对地址以及读入指令长度,并通过内置的hashlib库实现计算内存段内指令的特征,如下代码先来实现计算两段指令特征. import hashlib import zlib,bina
-
如何写出优雅的JS 代码
变量 使用有意义和可发音的变量名 // 不好的写法 const yyyymmdstr = moment().format("YYYY/MM/DD"); // 好的写法 const currentDate = moment().format("YYYY/MM/DD"); 对同一类型的变量使用相同的词汇 // 不好的写法 getUserInfo(); getClientData(); getCustomerRecord(); // 好的写法 getUser(); 使用可
-
一篇文章教你写出干净的JavaScript代码
目录 1. 变量 使用有意义的名称 避免添加不必要的上下文 避免硬编码值 2. 函数 使用有意义的名称 使用默认参数 限制参数的数量 避免在一个函数中做太多事情 避免使用布尔标志作为参数 避免写重复的代码 避免副作用 3. 条件语句 使用非负条件 尽可能使用简写 避免过多分支 优先使用 map 而不是 switch 语句 4.并发 避免回调 5. 错误处理 6.注释 只注释业务逻辑 使用版本控制 总结 一段干净的代码,你在阅读.重用和重构的时候都能非常轻松.编写干净的代码非常重要,因为在我们日常
-
通过数据库和ajax方法写出地图的实例代码
ajax教程 AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML). AJAX 不是新的编程语言,而是一种使用现有标准的新方法. AJAX 是与服务器交换数据并更新部分网页的艺术,在不重新加载整个页面的情况下. 客户端部分:html.js.css代码部分: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www
-
Java写入写出Excel操作源码分享
这两天帮老师做一个数据库,将所有实验交易的数据导入到数据库中,但是不想天天在实验室里面待着,气氛太压抑,就想着先把数据读进EXCEL中,哪天带到实验室导进去 数据原来是这样的,不同的实验有一个专门的文件夹,实验名的文件夹下有不同班级的文件夹,班级文件夹下有该班级日期文件夹,存储的是不同时间下该班做实验的数据EXCEL,原来的EXCEL中没有班级和时间,现在需要通过读取EXCEL名以及班级名来将该信息作为一列,加入到EXCEL中. 下面是源代码,嘿嘿,顺便还做了一个可视化窗口. 类ExcelRea
-
Java杂谈之如何优化写出漂亮高效的代码
目录 命名中的不一致 方案中的不一致 代码中的不一致 总结 大部分程序员对于一致性本身的重要性是有认知的.但通常来说,大家理解的一致性都表现在比较大的方面,比如,数据库访问是叫 DAO还是叫 Mapper,Repository?在一个团队内,这是有统一标准的,但编码的层面上,要求往往就不是那么细致了.所以,我们才会看到在代码细节上呈现出了各种不一致.我们还是从一段具体的代码来分析问题. 命名中的不一致 有一次,我在代码评审中看到了这样一段代码: enum DistributionChannel
-
PyTorch实现手写数字识别的示例代码
目录 加载手写数字的数据 数据加载器(分批加载) 建立模型 模型训练 测试集抽取数据,查看预测结果 计算模型精度 自己手写数字进行预测 加载手写数字的数据 组成训练集和测试集,这里已经下载好了,所以download为False import torchvision # 是否支持gpu运算 # device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # print(device) # print(torch.cud
-
超详细PyTorch实现手写数字识别器的示例代码
前言 深度学习中有很多玩具数据,mnist就是其中一个,一个人能否入门深度学习往往就是以能否玩转mnist数据来判断的,在前面很多基础介绍后我们就可以来实现一个简单的手写数字识别的网络了 数据的处理 我们使用pytorch自带的包进行数据的预处理 import torch import torchvision import torchvision.transforms as transforms import numpy as np import matplotlib.pyplot as plt
-
利用Java手写阻塞队列的示例代码
目录 前言 需求分析 阻塞队列实现原理 线程阻塞和唤醒 数组循环使用 代码实现 成员变量定义 构造函数 put函数 offer函数 add函数 take函数 重写toString函数 完整代码 总结 前言 在我们平时编程的时候一个很重要的工具就是容器,在本篇文章当中主要给大家介绍阻塞队列的原理,并且在了解原理之后自己动手实现一个低配版的阻塞队列. 需求分析 在前面的两篇文章ArrayDeque(JDK双端队列)源码深度剖析和深入剖析(JDK)ArrayQueue源码当中我们仔细介绍了队列的原理,
-
Java实现手写自旋锁的示例代码
目录 前言 自旋锁 原子性 自己动手写自旋锁 自己动手写可重入自旋锁 总结 前言 我们在写并发程序的时候,一个非常常见的需求就是保证在某一个时刻只有一个线程执行某段代码,像这种代码叫做临界区,而通常保证一个时刻只有一个线程执行临界区的代码的方法就是锁.在本篇文章当中我们将会仔细分析和学习自旋锁,所谓自旋锁就是通过while循环实现的,让拿到锁的线程进入临界区执行代码,让没有拿到锁的线程一直进行while死循环,这其实就是线程自己“旋”在while循环了,因而这种锁就叫做自旋锁. 自旋锁 原子性