pytorch的Backward过程用时太长问题及解决
目录
- pytorch Backward过程用时太长
- 问题描述
- 解决方案
- Pytorch backward()简单理解
- 有几个重要的点
- 总结
pytorch Backward过程用时太长
问题描述
使用pytorch对网络进行训练的时候遇到一个问题,forward阶段很快(只需要几毫秒),backward阶段却用时很长(需要十多秒)。
导致这个问题的原因很容易被大家忽视,而且网上基本上没有直接的解决方案,经过一天的折腾,总算把导致这个问题的原因搞清楚了。
解决方案
导致这个问题的原因在于训练数据的浅拷贝,由于backward过程中的梯度是和模型推理过程中的张量相关的,如果这些张量在被模型使用之前没有被深拷贝,意味着backward过程的会重复从这些张量的原始内存地址中取值,这个过程非常耗时。所以为了避免这个问题,需要养成一个好习惯,就是将张量数据输入模型之前进行深拷贝
pytorch的深拷贝方式如下:
tensor_a = tensor_b.clone().detach()
Pytorch backward()简单理解
backward()是反向传播求梯度,具体实现过程如下
import torch x=torch.tensor([1,2,3],requires_grad=True,dtype=torch.double) y=x**2 z=y.mean() z.backward() print(x.grad)
结果
tensor([0.6667, 1.3333, 2.0000], dtype=torch.float64)
有几个重要的点
1.必须要加上requires_grad=True才能求
2. 一般来说,需要标量才能求梯度。
3.具体过程如下:
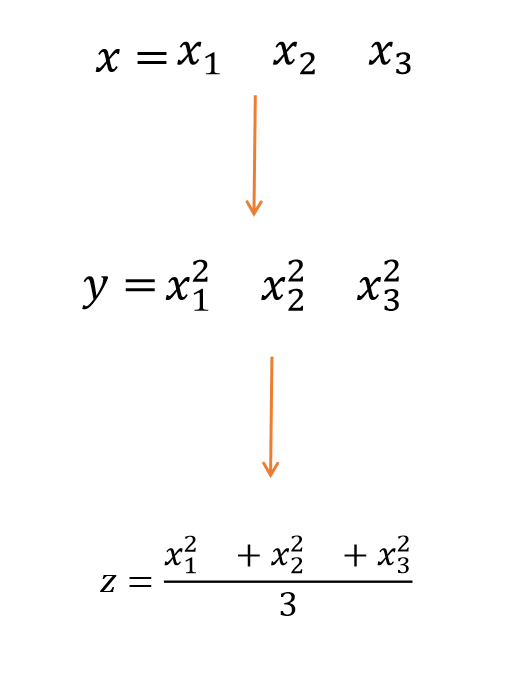
z是一个标量(1*1矩阵)分别对x1,x2,x3求偏导, 再代入x1,x2,x3的数值,就是如上程序输出的结果
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Pytorch中的backward()多个loss函数用法
Pytorch的backward()函数 假若有多个loss函数,如何进行反向传播和更新呢? x = torch.tensor(2.0, requires_grad=True) y = x**2 z = x # 反向传播 y.backward() x.grad tensor(4.) z.backward() x.grad tensor(5.) ## 累加 补充:Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析 backward函数 官方定义
-
浅谈Pytorch中的自动求导函数backward()所需参数的含义
正常来说backward( )函数是要传入参数的,一直没弄明白backward需要传入的参数具体含义,但是没关系,生命在与折腾,咱们来折腾一下,嘿嘿. 对标量自动求导 首先,如果out.backward()中的out是一个标量的话(相当于一个神经网络有一个样本,这个样本有两个属性,神经网络有一个输出)那么此时我的backward函数是不需要输入任何参数的. import torch from torch.autograd import Variable a = Variable(torch.Te
-
pytorch中backward()方法如何自动求梯度
目录 pytorch backward()方法自动求梯度 1.区分源张量和结果张量 2.如何使用backward()方法自动求梯度 pytorch中的梯度计算 什么是梯度? 自动计算梯度和偏导数 梯度的清空 总结 pytorch backward()方法自动求梯度 1.区分源张量和结果张量 x = torch.arange(-8.0, 8.0, 0.1, requires_grad= True) y = x.relu() x为源张量,基于源张量x得到的张量y为结果张量. 2.如何使用backwa
-
pytorch的梯度计算以及backward方法详解
基础知识 tensors: tensor在pytorch里面是一个n维数组.我们可以通过指定参数reuqires_grad=True来建立一个反向传播图,从而能够计算梯度.在pytorch中一般叫做dynamic computation graph(DCG)--即动态计算图. import torch import numpy as np # 方式一 x = torch.randn(2,2, requires_grad=True) # 方式二 x = torch.autograd.Variabl
-
PyTorch训练LSTM时loss.backward()报错的解决方案
训练用PyTorch编写的LSTM或RNN时,在loss.backward()上报错: RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time. 千万别改成loss.backward(retain_graph=Tru
-
pytorch的Backward过程用时太长问题及解决
目录 pytorch Backward过程用时太长 问题描述 解决方案 Pytorch backward()简单理解 有几个重要的点 总结 pytorch Backward过程用时太长 问题描述 使用pytorch对网络进行训练的时候遇到一个问题,forward阶段很快(只需要几毫秒),backward阶段却用时很长(需要十多秒). 导致这个问题的原因很容易被大家忽视,而且网上基本上没有直接的解决方案,经过一天的折腾,总算把导致这个问题的原因搞清楚了. 解决方案 导致这个问题的原因在于训练数据的
-
解决pytorch GPU 计算过程中出现内存耗尽的问题
Pytorch GPU运算过程中会出现:"cuda runtime error(2): out of memory"这样的错误.通常,这种错误是由于在循环中使用全局变量当做累加器,且累加梯度信息的缘故,用官方的说法就是:"accumulate history across your training loop".在默认情况下,开启梯度计算的Tensor变量是会在GPU保持他的历史数据的,所以在编程或者调试过程中应该尽力避免在循环中累加梯度信息. 下面举个栗子: 上代
-
Laravel 5.4因特殊字段太长导致migrations报错的解决
前言 本文主要介绍了关于Laravel 5.4因特殊字段太长导致migrations报错的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍: laravel 5.4 改变了默认的数据库字符集,现在utf8mb4包括存储emojis支持.MySQL 需要v5.7.7或者更高版本,当你试着在一些MariaDB或者一些老版本的的MySQL上运行 migrations 命令时,你会碰到下面这个错误: [Illuminate\Database\QueryException] SQLS
-
insert语句太长用StringBuilder优化一下
private void btnSave_Click(object sender, RoutedEventArgs e) { if (IsInsert) { //如果日历控件没有选日期,那帮它赋一个当前日期.下面有三个日历控件中,我只为其中一个日历控件做了赋值. DateTime time1 = dpEditTime.SelectedDate == null ? DateTime.Now : dpEditTime.SelectedDate.Value; DataUpdate updata = n
-
ubuntu中终端命令提示符太长的修改方法汇总
ubuntu的终端命令提示符太长,主要原因: 1:计算机名太长: 2:多层直接显示出来: 针对计算机名太长的处理: 如:下面的计算机名提示太长了: ningcaichen-virtual-machine是计算机名: ningcaichen@ningcaichen-virtual-machine:/mytmp$ sudo vim /etc/hostname 修改为: ningcaichen@ningcaichen-virtual-machine:/mytmp$ sudo vim /etc/host
-
解决vue-quill-editor上传内容由于图片是base64的导致字符太长的问题
vue-quill-editor是个较为轻量级富文本框,相较于ueditor,开发更编辑,更加直观,如果大家伙在需求允许的情况下,还是会比较建议使用vue-quill-editor. vue-quill-editor的使用方法在这边就不多说了,大家网上查下,一抓一大把 但是在使用vue-quill-editor有一个致命的问题,vue-quill-editor默认插入图片是直接将图片转为base64再放入内容中,如果图片比较大的话,富文本的内容就会很大,即使图片不大,只要图片较为多,篇幅较长,富
-
python一行sql太长折成多行并且有多个参数的方法
sql语句 有一个非常长的sql,用编辑器打开编写的时候太长了导致编写非常吃力,而且容易错乱,我想做的是把A,B,C三个变量赋值到sql中的字段中去 A=1 B=2 C=3 sql = "update student t set t.name = '',t.sex = '',t.age = '',t.height = '',t.weight = '',t.class = '',t.stuid = '',t.xxx = '' where t.stuid= '' and t.xxx = '';&qu
-
Pytorch.nn.conv2d 过程验证方式(单,多通道卷积过程)
今天在看文档的时候,发现pytorch 的conv操作不是很明白,于是有了一下记录 首先提出两个问题: 1.输入图片是单通道情况下的filters是如何操作的? 即一通道卷积核卷积过程 2.输入图片是多通道情况下的filters是如何操作的? 即多通道多个卷积核卷积过程 这里首先贴出官方文档: classtorch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1
-
Windows10+anacond+GPU+pytorch安装详细过程
1.查看自己电脑是否匹配GPU版本. 设备管理器查看. 查看官网是否匹配.地址:https://developer.nvidia.com/cuda-gpus ** 2.进入NVIDIA对电脑版本进行查**看. 如果可以的的话可以自己卸载原来版本,后安装新版本.安装地址https://developer.nvidia.com/cuda-toolkit-archive 接下来,进入NVIDIA安装过程,在这安装过程中,我一开始直接选择的精简安装,但由于VS的原因,导致无法正常安装,于是我换成了自定
-
解决Android Studio日志太长或滚动太快问题
前言 安卓开发经常遇到那种日志太长或滚动得太快, 我们直接的解决办法就是进行日志输出长度增大和添加日志过滤器,个人推荐用adb logcat处理更加方便灵活. 解决办法 1. 搜索过滤器 2. 修改日志缓冲大小 找到 " Android Studio安装目录\bin\idea.properties" 文件中的 idea.cycle.buffer.size=1024 修改成你要的缓冲大小即可. 3. adb logcat 输出日志到指定文件(不能解决日志过长的问题) i. 配置adb环境