mysql一次将多条不同sql查询结果并封装到一个结果集的实现方法
目录
- 前言
- 问题处理过程
- 1.使用union all进行并列查询
- 2.求和处理
- 总结
前言
最近遇到一个统计查询需求,要求一次性查询多个统计信息,其中两个查询信息不在一个表中,也没有业务关联,表中也没有做连接处理。不考虑产品设计是否合理,完全是实际需求如此,需要一次性查询出来返回给前端进行展示,对于这种“非常规”的统计查询平常肯定会遇见,感觉有点代表性,所以简单记录一下。希望对有相同需求的同学可以作为参考。
问题处理过程
简单交代一下业务场景,为方便理解,对业务需求做了简化处理。
现在有一个分销活动,每个人都可以成为分销人进行分享活动,一旦有人通过分享的活动连接购买之后分销人会有收益信息,当然分销活动商品也可以不通过分享链接而是直接购买,但是不会存在分销收益一说。表结构方面,所有的订单都存入订单表order中,对于存在分销关系的会将分销绑定信息(分销人与被分销人)记录到record表中,不通过分销直接购买的不会在record表中添加记录。现在要求统计一下当天的订单总数与分销记录总数,假设当天为2022.11.08。
如果是单独统计计算很简单,直接统计总数就可以:
统计当天的总订单数:
SELECT COUNT(1) total_couut FROM order WHERE DATE_FORMAT(order_create_time,'%Y-%m-%d') = '2022-11-08'
统计当天的分销总的分销记录数:
SELECT COUNT(1) record _count FROM record WHEREDATE_FORMAT(create_time,'%Y-%m-%d') = '2022-11-08'
但是如何将两个不同的统计信息封装到一个结果集中,这里提供一种处理方案,使用union all进行并列查询,然后进行求和查询。具体实现方式如下。
1.使用union all进行并列查询
为保证查询出来的参数信息一致,查询订单总数时补充上分销记录总数,查询分销记录总数补充上订单总数,具体实现如下:
SELECT COUNT(1) total_couut,0 record_count FROM order WHERE DATE_FORMAT(order_create_time,'%Y-%m-%d') = '2022-11-08' union all SELECT 0 total_count,COUNT(1) record _count FROM record WHEREDATE_FORMAT(create_time,'%Y-%m-%d') = '2022-11-08'
查询结果如下:
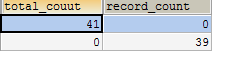
2.求和处理
现在已经查询出总订单数和总分销记录数,下面需要处理的是如何封装到一个结果集中,处理的方式也很简单,就是直接求和,因为对应的字段值都为0,。具体实现如下:
select sum(t.total_count) total_count, sum(t.record_count) record_count from (SELECT COUNT(1) total_couut,0 record_count FROM order WHERE DATE_FORMAT(order_create_time,'%Y-%m-%d') = '2022-11-08' union all SELECT 0 total_count,COUNT(1) record _count FROM record WHEREDATE_FORMAT(create_time,'%Y-%m-%d') = '2022-11-08') t
查询结果如下:

至此问题解决,一条sql将多条无法进行关联的sql封装到一个结果集中。
总结
到此这篇关于mysql一次将多条不同sql查询结果并封装到一个结果集实现的文章就介绍到这了,更多相关mysql多条sql查询结果封装到一个结果集内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
mysql一次将多条不同sql查询结果并封装到一个结果集的实现方法
目录 前言 问题处理过程 1.使用union all进行并列查询 2.求和处理 总结 前言 最近遇到一个统计查询需求,要求一次性查询多个统计信息,其中两个查询信息不在一个表中,也没有业务关联,表中也没有做连接处理.不考虑产品设计是否合理,完全是实际需求如此,需要一次性查询出来返回给前端进行展示,对于这种“非常规”的统计查询平常肯定会遇见,感觉有点代表性,所以简单记录一下.希望对有相同需求的同学可以作为参考. 问题处理过程 简单交代一下业务场景,为方便理解,对业务需求做了简化处理. 现在有一个分销
-
SpringDataJPA原生sql查询方式的封装操作
工具类相关代码 使用到了apache的map2bean工具类 导入方法 <dependency> <groupId>commons-beanutils</groupId> <artifactId>commons-beanutils</artifactId> <version>1.9.3</version> </dependency> import org.apache.commons.beanutils.Bea
-
MySQL的一条慢SQL查询导致整个网站宕机的解决方法
直接切入正题吧: 通常来说,我们看到的慢查询一般还不致于导致挂站,顶多就是应用响应变慢 不过这个恰好今天被我撞见了,一个慢查询把整个网站搞挂了 先看看这个SQL张撒样子: # Query_time: 70.472013 Lock_time: 0.000078 Rows_sent: 7915203 Rows_examined: 15984089 Rows_affected: 0 # Bytes_sent: 1258414478 use js_sku; SET timestamp=146585011
-
一个sql查询器,自动画表格填字段
一个什么都不懂的家伙非跟我要个sql查询器 随便写了一个,当然为了数据安全,要过滤掉一个sql关键词和系统中的一些表了 哦,对了,里面的一些函数你可能不知道哪里来的,是我现在开发一些东西一直用的自己写的一个小框架 把常用的功能封装一下,写程序主要是思路,看一下代码思想就知道我的原理了 <% function QuerySql(sql) %> <table width="680" cellspacing="1" cellpadding="3
-

分析mysql中一条SQL查询语句是如何执行的
目录 一.MySQL 逻辑架构概览 二.连接器(Connector) 三.查询缓存(Query Cache) 四.解析器(Parser) 五.优化器(Optimizer) 六.执行器 七.小结 一.MySQL 逻辑架构概览 MySQL 最重要.最与众不同的特性就是它的可插拔存储引擎架构(pluggable storage engine architecture),这种架构的设计将查询处理及其他系统任务和数据的存储/提取分离开来.来看官网的解释: The MySQL pluggable stora
-
MySQL中一条SQL查询语句是如何执行的
目录 前言 1. 处理连接 1.1 客户端和服务端的通信方式 1.1.1 TCP/IP协议 1.1.2 UNIX域套接字 1.1.3 命名管道和共享内存 1.2 权限验证 1.3 查看MySQL连接 2. 解析与优化 2.1 查询缓存 2.2 解析器 & 预处理器(Parser & Preprocessor) 2.2.1 词法解析 2.2.2 语法分析 2.2.3 预处理器 2.3 查询优化器(Optimizer)与查询执行计划 2.3.1 什么是查询优化器? 2.3.2 优化器究竟做了什
-
Java使用JDBC向MySQL数据库批次插入10W条数据(测试效率)
使用JDBC连接MySQL数据库进行数据插入的时候,特别是大批量数据连续插入(100000),如何提高效率呢? 在JDBC编程接口中Statement 有两个方法特别值得注意: 通过使用addBatch()和executeBatch()这一对方法可以实现批量处理数据. 不过值得注意的是,首先需要在数据库链接中设置手动提交,connection.setAutoCommit(false),然后在执行Statement之后执行connection.commit(). import java.io.Bu
-
MySQL数据库开发的36条原则(小结)
前言 这些原则都是经历过实战总结而成 每一条原则背后都是血淋淋的教训 这些原则主要是针对数据库开发人员,在开发过程中务必注意 一.核心原则 1.尽量不在数据库做运算 俗话说:别让脚趾头想事情,那是脑瓜子的职责 作为数据库开发人员,我们应该让数据库多做她所擅长的事情: 尽量不在数据库做运算 复杂运算移到程序端CPU 尽可能简单应用MYSQL 举例: 在mysql中尽量不要使用如:md5().Order by Rand()等这类运算函数 2.尽量控制单表数据量 大家都知道单表数据量过大后会影响数据查
-
mySql关于统计数量的SQL查询操作
我就废话不多说了,大家还是直接看代码吧~ select project_no, sum(case when device_state=0 then 1 else 0 end)as offTotal , sum(case when device_state=1 then 1 else 0 end)as onlineTotal, sum(1)total from iot_d_device group by project_no order by project_no 补充:MySQL一条SQL语句查
-
mysql查询优化之100万条数据的一张表优化方案
1.两种查询引擎查询速度(myIsam 引擎 ) InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行. MyISAM只要简单的读出保存好的行数即可. 注意的是,当count(*)语句包含 where条件时,两种表的操作有些不同,InnoDB类型的表用count(*)或者count(主键),加上where col 条件.其中col列是表的主键之外的其他具有唯一约束索引的列.这样查询时速度会很快.就是可