OpenCV使用KNN完成OCR手写体识别
目录
- 目标
- 手写数字的OCR
- 也可以用来预测单个数字
- 英文字母的OCR
目标
在本章中,将学习
- 使用kNN来构建基本的OCR应用程
- 使用OpenCV自带的数字和字母数据集
手写数字的OCR
目标是构建一个可以读取手写数字的应用程序。为此,需要一些 train_data 和test_data 。OpenCV git项目中有一个图片 digits.png (opencv/samples/data/ 中),其中包含 5000 个手写数字(每个数字500个),每个数字都是尺寸大小为 20x20 的图像。

因此,第一步是将上面这张图像分割成 5000 (500*10)个不同的数字。对于每个数字,将其展平为 400 像素的一行,这就是训练集,即所有像素的强度值。这个是可以创建的最简单的特征集合。将每个数字的前 250个样本用作训练集train_data ,然后将 250 个样本用作 测试集test_data 。
import cv2
import numpy as np
img = cv2.imread('digits.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Now we split the image to 5000 cells, each 20x20 size
cells = [np.hsplit(row, 100) for row in np.vsplit(gray, 50)]
# Make it into a numpy array: its size will be (50, 100, 20, 20)
x = np.array(cells)
# Now we prepare the training data and test data
train = x[:,:50].reshape(-1,400).astype(np.float32) # Size = (2500,400)
test = x[:,50:100].reshape(-1,400).astype(np.float32) # Size = (2500,400)
# Create labels for train and test data
k = np.arange(10)
train_labels = np.repeat(k, 250)[:, np.newaxis]
test_labels = train_labels.copy()
# Initiate kNN, train it on the training data, then test it with the test data with k=1
knn = cv2.ml.KNearest_create()
knn.train(train, cv2.ml.ROW_SAMPLE, train_labels)
ret, result, neighbours, dist = knn.findNearest(test, k=5)
# Now we check the accuracy of classification
# For that, compare the result with test_labels and check which are wrong
matches = result==test_labels
correct = np.count_nonzero(matches)
accuracy = correct * 100.0/result.size
print( accuracy ) # 91.76
可以看到,上述构建了一个基础的数字手写体OCR应用程序已准备就绪。在这个特定的例子中的准确度是91.76%。
提高准确度方法:
- 一种提高准确性的选择是添加更多数据进行训练,尤其是错误的数据。
- 另外一种是更换更优的算法
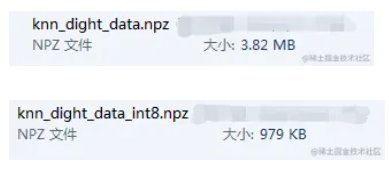
本文中,每次启动应用程序时都找不到该训练数据,不如将其保存,以便下次直接从文件中读取此数据并开始分类。可以借助一些Numpy函数(例如np.savetxt,np.savez,np.load等)来完成此操作。
# Save the data
np.savez('knn_dight_data.npz', train=train, train_labels=train_labels)
# Now load the data
whit np.load('knn_data.npz') as data:
print(data.files)
train = data['train']
train_labels = data['train_labels']
在windows系统下,大约需要大约 3.82 MB 的内存。由于仅使用强度值(uint8数据)作为特征,如果需要考虑内存的问题时候,可以先将数据转换为 np.uint8 ,然后再将其保存。在这种情况下,仅占用 0.98MB 。然后在加载时,可以转换回 float32 。
train_uint8 = train.astype(np.uint8)
train_labels_uint8 = train_labels.astype(np.uint8)
np.savez('knn_dight_data_int8.npz', train=train_uint8, train_labels=train_labels_uint8)
也可以用来预测单个数字
# 取测试集中的一个元素 single_data = testData[0].reshape(-1, 400) single_label = labels[0] ret, result, neighbours, dist = knn.findNearest(data, k=5) print(result) # [[0]] print(label) # [[0.]] print(result==label) # True
英文字母的OCR
接下来,对英语字母执行相同的操作,但是数据和特征集会稍有变化。OpenCV使用文件letter-recognition.data( /data/samples/data/letter-recognition.data)代替图像 。如果打开它,将看到20000行,乍一看可能看起来像垃圾数字。

实际上,在每一行中,第一列是字母,这是标签。接下来的16个数字是它的不同特征,这些特征是从UCI机器学习存储库获得的。可以在此页面中找到这些功能的详细信息。
现有20000个样本,将前10000个数据作为训练样本,剩余的10000个作为测试样本。字母应该更改为ASCII字符,因为不能直接使用字母。
import numpy as np
import cv2
# Load the data and convert the letters to numbers
data = np.loadtxt('letter-recognition.data', dtype='float32', delimiter=',', converters={0: lambda ch: ord(ch)-ord('A')})
# Split the dataset in two, with 10000 samples each for training and test sets
train, test = np.vsplit(data, 2)
# Split trainData and testData into features and responses
responses, trainData = np.hsplit(train, [1])
labels, testData = np.hsplit(test, [1])
# Initiate the kNN, classify, measure accuracy
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, result, neighbours, dist = knn.findNearest(testData, k=5)
correct = np.count_nonzero(result==labels)
accuracy = correct * 100 / result.size
print(accuracy) # 93.06
它给我的准确性为 93.06% 。同样,如果要提高准确性,则可以迭代地在每个类别中添加错误数据。
附加资源
以上就是OpenCV使用KNN完成OCR手写体识别的详细内容,更多关于OpenCV KNN识别OCR手写体的资料请关注我们其它相关文章!
相关推荐
-
python OpenCV实现图像特征匹配示例详解
目录 目标 Brute-Force匹配器的基础 使用ORB描述符进行Brute-Force匹配 什么是Matcher对象? 带有SIFT描述符和比例测试的Brute-Force匹配 基于匹配器的FLANN 目标 在本章中,将学习: 如何将一个图像中的特征与其他图像进行匹配 在OpenCV中使用Brute-Force匹配器和FLANN匹配器 Brute-Force匹配器的基础 暴力匹配器很简单.它使用第一组中一个特征的描述符,并使用一些距离计算将其与第二组中的所有其他特征匹配.并返回最接近的一个.
-

基于Opencv图像识别实现答题卡识别示例详解
目录 1. 项目分析 2.项目实验 3.项目结果 总结 在观看唐宇迪老师图像处理的课程中,其中有一个答题卡识别的小项目,在此结合自己理解做一个简单的总结. 1. 项目分析 首先在拿到项目时候,分析项目目的是什么,要达到什么样的目标,有哪些需要注意的事项,同时构思实验的大体流程. 图1. 答题卡测试图像 比如在答题卡识别的项目中,针对测试图片如图1 ,首先应当实现的功能是: 能够捕获答题卡中的每个填涂选项. 将获取的填涂选项与正确选项做对比计算其答题正确率. 2.项目实验 在对测试图像进行形态学操
-
OpenCV之理解KNN邻近算法k-Nearest Neighbour
目录 目标 理论 OpenCV中的kNN 目标 在本章中,将理解 k最近邻(kNN)算法的概念 理论 kNN是可用于监督学习的最简单的分类算法之一.这个想法是在特征空间中搜索测试数据的最近邻.用下面的图片来研究它. 在图像中,有两个族类,蓝色正方形和红色三角形.称每一种为类(Class).他们的房屋显示在他们的城镇地图中,我们称之为特征空间( Feature Space). (可以将特征空间视为投影所有数据的空间.例如,考虑一个2D坐标空间.每个数据都有两个特征,x和y坐标.可以在2D坐标空间中
-
OpenCV特征匹配和单应性矩阵查找对象详解
目录 目标 基础 实现 附加资源 目标 在本章中,将学习 将从Calib3D模块中混淆特征匹配和找到(单应性矩阵)homography,以查找复杂图像中的已知对象. 基础 在之前的内容中,使用了一个query image,在其中找到了一些特征点,拍摄了另一张train image,也在该图像中找到了特征,找到了其中最好的匹配.简而言之,在另一张杂乱的图像中找到了物体某些部分的位置.该信息足以准确地在train image上找到对象. 为此,可以使用calib3d模块的函数,即cv2.findHo
-
OpenCV 光流Optical Flow示例
目录 目标 光流 OpenCV 中的 Lucas-Kanade 光流 OpenCV 中的密集光流 目标 在本章中,将学习: 使用 Lucas-Kanade 方法理解光流的概念及其估计 使用cv2.calcOpticalFlowPyrLK()等函数来跟踪视频中的特征点 使用cv2.calcOpticalFlowFarneback()方法创建一个密集的光流场 光流 光流是由物体或相机的运动引起的图像物体在两个连续帧之间的明显运动的模式.它是二维向量场,其中每个向量都是一个位移向量,显示点从第一帧到第
-
OpenCV目标检测Meanshif和Camshift算法解析
目录 学习目标 Meanshift OpenCV中的Meanshift Camshift OpenCV中的Camshift 附加资源 学习目标 在本章中,将学习用于跟踪视频中对象的Meanshift和Camshift算法 Meanshift Meanshift背后的原理很简单,假设有点的集合(它可以是像素分布,例如直方图反投影). 给定一个小窗口(可能是一个圆形),必须将该窗口移动到最大像素密度(或最大点数)的区域.如下图所示: 初始窗口以蓝色圆圈显示,名称为“C1”.其原始中心以蓝色矩形标记,
-
OpenCV立体图像深度图Depth Map基础
目录 目标 基础 代码 目标 在本节中,将学习 根据立体图像创建深度图 基础 在上一节中,看到了对极约束和其他相关术语等基本概念.如果有两个场景相同的图像,则可以通过直观的方式从中获取深度信息.下面是一张图片和一些简单的数学公式证明了这种想法. 上图包含等效三角形.编写它们的等式将产生以下结果: xxx和x′x'x′是图像平面中与场景点3D相对应的点与其相机中心之间的距离.BBB是两个摄像机之间的距离(已知),fff是摄像机的焦距(已知).简而言之,上述方程式表示场景中某个点的深度与相应图像点及
-
python使用KNN算法手写体识别
本文实例为大家分享了用KNN算法手写体识别的具体代码,供大家参考,具体内容如下 #!/usr/bin/python #coding:utf-8 import numpy as np import operator import matplotlib import matplotlib.pyplot as plt import os ''''' KNN算法 1. 计算已知类别数据集中的每个点依次执行与当前点的距离. 2. 按照距离递增排序. 3. 选取与当前点距离最小的k个点 4. 确定前k个点所
-
Python实现基于KNN算法的笔迹识别功能详解
本文实例讲述了Python实现基于KNN算法的笔迹识别功能.分享给大家供大家参考,具体如下: 需要用到: Numpy库 Pandas库 手写识别数据 点击此处本站下载. 数据说明: 数据共有785列,第一列为label,剩下的784列数据存储的是灰度图像(0~255)的像素值 28*28=784 KNN(K近邻算法): 从训练集中找到和新数据最接近的K条记录,根据他们的主要分类来决定新数据的类型. 这里的主要分类,可以有不同的判别依据,比如"最多","最近邻",或者
-
C++ OpenCV技术实战之身份证离线识别
目录 总体思路 图像的预处理 主要代码 实现效果 OpenCV身份证离线识别技术的主要技术就是通过OpenCV找到身份证号码区域,然后通过OCR进行数字识别该区域的截图即可得到身份证号码.本地ORC使用tess-two来完成,Tesseract是C++实现的OCR引擎,在Android中使用不是很方便,需要封装JavaAPI才能在Android平台中进行调用,然而tess-two已经帮我们做好了这些事情,通过集成tess-two就可以很方便的完成文字识别. 总体思路 图像的预处理 1.无损压缩
-
C++ OpenCV实战之手写数字识别
目录 前言 一.准备数据集 二.KNN训练 三.模型预测及结果显示 四.源码 总结 前言 本案例通过使用machine learning机器学习模块进行手写数字识别.源码注释也写得比较清楚啦,大家请看源码注释!!! 一.准备数据集 原图如图所示:总共有0~9数字类别,每个数字共20个.现在需要将下面图片切分成训练数据图片.测试数据图片.该图片尺寸为560x280,故将其切割成28x28大小数据图片.具体请看源码注释. const int classNum = 10; //总共有0~9个数字类别
-
Python3实现简单可学习的手写体识别(实例讲解)
1.前言 版本:Python3.6.1 + PyQt5 + SQL Server 2012 以前一直觉得,机器学习.手写体识别这种程序都是很高大上很难的,直到偶然看到了这个视频,听了老师讲的思路后,瞬间觉得原来这个并不是那么的难,原来我还是有可能做到的. 于是我开始顺着思路打算用Python.PyQt.SQLServer做一个出来,看看能不能行.然而中间遇到了太多的问题,数据库方面的问题有十几个,PyQt方面的问题有接近一百个,还有数十个Python基础语法的问题.但好在,通过不断的Google
-
java实现腾讯ocr图片识别接口调用
最近开发了一个拍车牌识别车牌号的功能,主要调用了腾讯的ocr车牌识别接口,直接上代码: 首先生成签名以及读取配置的工具类: package com.weaver.formmodel.integration.ocr; import java.util.Random; import javax.crypto.Mac; import javax.crypto.spec.SecretKeySpec; import weaver.general.Base64; public class SignUtil
-
Java使用OCR技术识别验证码实现自动化登陆方法
如论实施敏捷的团队,或者实施 DevOps 的团队,通过自动化测试提高测试效率和软件质量都是其共同的选择.UI 自动化测试是自动化化测试当中的重要环节,在 UI 自动化测试中验证码识别一直是令自动化测试人员头疼的问题.今年来随着 OCR 技术.人工智能计算机视觉(AI Computer Vision)技术的成熟与使用大大提高了验证码的识别成功率.从而使得自动识别验证码自动化登陆目标系统成为可能. 本Chat 主要内容包括: OCR 技术与人工智能计算机视觉(AI Computer Vision)
-
java实现百度云OCR文字识别 高精度OCR识别身份证信息
本文为大家分享了java实现百度云OCR识别的具体代码,高精度OCR识别身份证信息,供大家参考,具体内容如下 1.通用OCR文字识别 这种OCR只能按照识别图片中的文字,且是按照行识别返回结果,精度较低. 首先引入依赖包: <dependency> <groupId>com.baidu.aip</groupId> <artifactId>java-sdk</artifactId> <version>4.6.0</version&
-
python实现百度OCR图片识别过程解析
这篇文章主要介绍了python实现百度OCR图片识别过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 import base64 import requests class CodeDemo: def __init__(self,AK,SK,code_url,img_path): self.AK=AK self.SK=SK self.code_url=code_url self.img_path=img_path self.ac
-
使用PyTorch实现MNIST手写体识别代码
实验环境 win10 + anaconda + jupyter notebook Pytorch1.1.0 Python3.7 gpu环境(可选) MNIST数据集介绍 MNIST 包括6万张28x28的训练样本,1万张测试样本,可以说是CV里的"Hello Word".本文使用的CNN网络将MNIST数据的识别率提高到了99%.下面我们就开始进行实战. 导入包 import torch import torch.nn as nn import torch.nn.functional