Python实现博客快速备份的脚本分享
目录
- 转存文章到MD
- 转存图片到本地
鉴于有些小伙伴在寻找博客园迁移到个人博客的方案,本人针对博客园实现了一个自动备份脚本,可以快速将博客园中自己的文章备份成Markdown格式的独立文件,备份后的md文件可以直接放入到hexo博客中,快速生成自己的站点,而不需要自己逐篇文章迁移,提高了备份文章的效率。
首先第一步将博客园主题替换为codinglife默认主题,第二步登录到自己的博客园后台,然后选择博客备份,备份所有的随笔文章,如下所示:
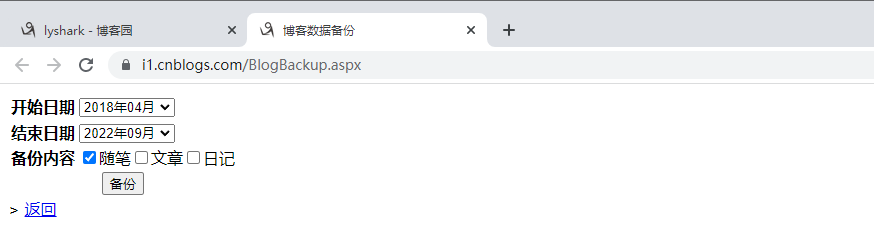
备份出来以后将其命名为backup.xml,然后新建一个main.py脚本,以及一个blog目录,代码实现的原理是,解析xml格式并依次提取出文档内容,然后分别保存为markdown文件。
转存文章到MD
写入备份脚本,代码如下所示,运行后即可自动转存文件到blog目录下,当运行结束后备份也就结束了。
# powerby: LyShark
# blog: www.cnblogs.com/lyshark
from bs4 import BeautifulSoup
import requests, os,re
header = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) By LyShark CnblogsBlog Backup Script"}
# 获取文章,并转成markdown
# blog: www.lyshark.com
def GetMarkDown(xml_file):
con = open(xml_file, 'r', encoding='utf8').read()
# 每篇文章都在 <item> 标签里
items = re.findall("<item>.*?</item>", con, re.I | re.M | re.S)
ele2 = ['<title>(.+?)</title>', '<link>(.+?)</link>', '<description>(.+?)</description>']
# md_name = xml_file.split('.xml')[0] + '.md'
for item in items:
try:
title = re.findall(ele2[0], item, re.I | re.S | re.M)[0]
link = re.findall(ele2[1], item, re.I | re.S | re.M)[0]
des = re.findall(ele2[2], item, re.I | re.S | re.M)[0]
des = re.findall('<!\[CDATA\[(.+?)\]\]>', des, re.I | re.S | re.M)[0] # CDATA 里面放的是文章的内容
des = des.replace('~~~', "```")
lines = des.split('\n')
with open("./blog/" + title.replace("/","") + ".md", mode='w+', encoding='utf8') as f:
f.write("---\n")
f.write("title: '{}'\n".format(title.replace("##","").replace("###","").replace("-","").replace("*","").replace("<br>","").replace(":","").replace(":","").replace(" ","").replace(" ","").replace("`","")))
f.write("copyright: true\n")
setdate = "2018-12-27 00:00:00"
try:
# 读取时间
response = requests.get(url=link, headers=header)
print("读取状态: {}".format(response.status_code))
if response.status_code == 200:
bs = BeautifulSoup(response.text, "html.parser")
ret = bs.select('span[id="post-date"]')[0]
setdate = str(ret.text)
pass
else:
f.write("date: '2018-12-27 00:00:00'\n")
except Exception:
f.write("date: '2018-12-27 00:00:00'\n")
pass
f.write("date: '{}'\n".format(setdate))
# description检测
description_check = lines[0].replace("##","").replace("###","").replace("-","").replace("*","").replace("<br>","").replace(":","").replace(":","").replace(" ","").replace(" ","")
if description_check == "":
f.write("description: '{}'\n".format("该文章暂无概述"))
elif description_check == "```C":
f.write("description: '{}'\n".format("该文章暂无概述"))
elif description_check == "```Python":
f.write("description: '{}'\n".format("该文章暂无概述"))
else:
f.write("description: '{}'\n".format(description_check))
print("[*] 时间: {} --> 标题: {}".format(setdate, title))
f.write("tags: '{}'\n".format("tags10245"))
f.write("categories: '{}'\n".format("categories10245"))
f.write("---\n\n")
f.write('%s' %des)
f.close()
except Exception:
pass
if __name__ == "__main__":
GetMarkDown("backup.xml")
备份后的效果如下所示:
打开Markdown格式看一下,此处的标签和分类使用了一个别名,在备份下来以后,你可以逐个区域进行替换,将其替换成自己需要的分类类型即可。
转存图片到本地
接着就是继续循环将博客中所有图片备份下来,同样新建一个image文件夹,并运行如下代码实现备份。
# powerby: LyShark
# blog: www.cnblogs.com/lyshark
from bs4 import BeautifulSoup
import requests, os,re
header = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) By LyShark CnblogsBlog Backup Script"}
# 从备份XML中找到URL
# blog: www.cnblogs.com/lyshark
def GetURL(xml_file):
blog_url = []
con = open(xml_file, 'r', encoding='utf8').read()
items = re.findall("<item>.*?</item>", con, re.I | re.M | re.S)
ele2 = ['<title>(.+?)</title>', '<link>(.+?)</link>', '<description>(.+?)</description>']
for item in items:
title = re.findall(ele2[0], item, re.I | re.S | re.M)[0]
link = re.findall(ele2[1], item, re.I | re.S | re.M)[0]
print("标题: {} --> URL: {} ".format(title,link))
blog_url.append(link)
return blog_url
# 下载所有图片
# blog: www.lyshark.com
def DownloadURLPicture(url):
params = {"encode": "utf-8"}
response = requests.get(url=url, params=params, headers=header)
# print("网页编码方式: {} -> {}".format(response.encoding,response.apparent_encoding))
context = response.text.encode(response.encoding).decode(response.apparent_encoding, "ignore")
try:
bs = BeautifulSoup(context, "html.parser")
ret = bs.select('div[id="cnblogs_post_body"] p img')
for item in ret:
try:
img_src_path = item.get("src")
img_src_name = img_src_path.split("/")[-1]
print("[+] 下载图片: {} ".format(img_src_name))
img_download = requests.get(url=img_src_path, headers=header, stream=True)
with open("./image/" + img_src_name, "wb") as fp:
for chunk in img_download.iter_content(chunk_size=1024):
fp.write(chunk)
except Exception:
print("下载图片失败: {}".format(img_src_name))
pass
except Exception:
pass
if __name__ == "__main__":
url = GetURL("backup.xml")
for u in url:
DownloadURLPicture(u)
备份后的效果如下:
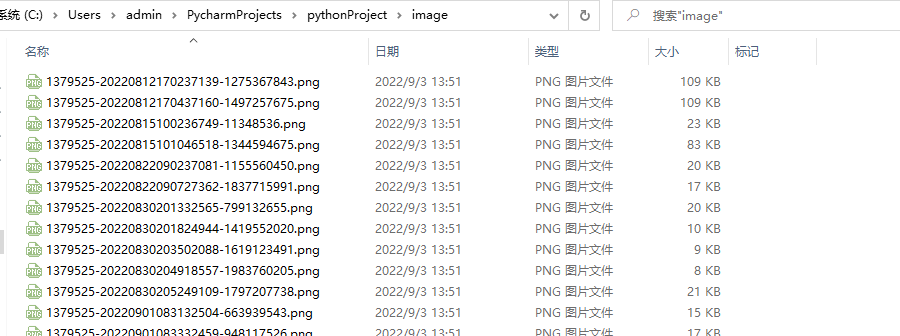
替换文章内的图片链接地址,可以使用编辑器,启用正则批量替换。
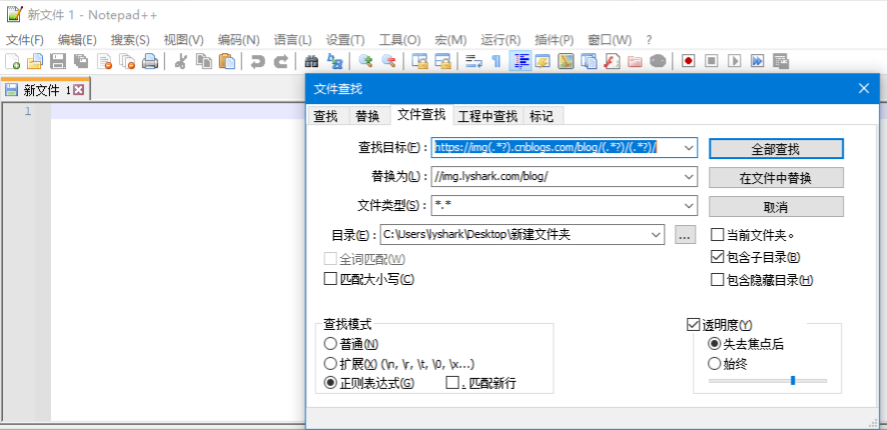
当把博客备份下来以后你就可以把这些文章拷贝到hexo博客_post目录下面,然后hexo命令快速渲染生成博客园的镜像站点,这样也算是增加双保险了。
到此这篇关于Python实现博客快速备份的脚本分享的文章就介绍到这了,更多相关Python备份博客内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python基础之文件的备份以及定位
目录 小型文件备份 备份大型文件 总结 小型文件备份 # 文件的备份 def copyFile(): # 接收用户输入的文件名 old_file=input('请输入要备份的文件名:') file_list=old_file.split('.') # 构造新的文件名.加上备份的后缀 new_file=file_list[0]+'_备份.'+file_list[1] old_f=open(old_file,'r') #打开需要备份的文件 new_f=open(new_file,'w') #以写的模
-
python创建文件备份的脚本
制作文件备份 打开原文件 old_f_name = input("请输入备份的文件路径:") old_f = open(old_f_name, "r") 打开新文件 new_f_name = "[复件]" + old_f_name 123.txt -> 123[复件].txt 123 + "[复件]" + .txt index = old_f_name.rfind(".") # 获取.对应的后缀 if
-
python实现文件的备份流程详解
python实现输入要备份的文件名称:test.txt 12行代码实现文件备份功能 第一步:打开我们的pycharm软件,然后新建一个Python文件 第二步:新建好我们的Python文件后,我们在编辑界面输入以下代码: oldfilename=input("请输入要备份的文件名:") #输入需要备份的旧文件名 oldfile=open(oldfilename,'r') #打开旧文件 if oldfile: #如果文件存在,则执行下面的语句 fileflagnum=oldfilenam
-
Python实现新浪博客备份的方法
本文实例讲述了Python实现新浪博客备份的方法.分享给大家供大家参考,具体如下: Python2.7.2版本实现,推荐在IDE中运行. # -*- coding:UTF-8 -*- # ''' Created on 2011-12-18 @author: Ahan ''' import re import sys import os import time import socket import locale import datetime import codecs from urllib
-
用python实现文件备份
目录 1.需求 2.步骤 3.代码实现 (1)接收用户输入目标文件名 (2)规划备份文件名 (3)备份文件写入数据 (4)思考 (5)完整编码 4.再来一个小练习 总结 1.需求 用户输入当前目录下任意文件名,程序完成对该文件的备份功能. 备份文件名为xx[备份]后缀,例如:test[备份].txt. 2.步骤 接收用户输入的文件名.规划备份文件名.备份文件写入数据. 3.代码实现 (1)接收用户输入目标文件名 old_name = input('请输入您要备份的文件名:') (2)规划备份文件
-
Python实现博客快速备份的脚本分享
目录 转存文章到MD 转存图片到本地 鉴于有些小伙伴在寻找博客园迁移到个人博客的方案,本人针对博客园实现了一个自动备份脚本,可以快速将博客园中自己的文章备份成Markdown格式的独立文件,备份后的md文件可以直接放入到hexo博客中,快速生成自己的站点,而不需要自己逐篇文章迁移,提高了备份文章的效率. 首先第一步将博客园主题替换为codinglife默认主题,第二步登录到自己的博客园后台,然后选择博客备份,备份所有的随笔文章,如下所示: 备份出来以后将其命名为backup.xml,然后新建一个
-
Python个人博客程序开发实例框架设计
目录 1.数据库(models.py) 1.1 管理员 Admin 1.2 分类 Category 1.3 文章 Post 1.4 评论 Comment 1.5 社交链接 Link 2.生成虚拟数据(fakes.py) 3.模板 3.1 模板上下文 3.2 渲染导航链接 3.3 Flash消息分类 4.表单(forms.py) 4.1 登录表单 4.2 文章表单 4.3 分类表单 4.4 评论表单 5.视图函数(blueprints:admin.auth.blog) 6.电子邮件支持(email
-
Python个人博客程序开发实例信息显示
目录 1.分页显示文章列表 1.1 获取分页记录 1.2 渲染分页导航部件 2.显示文章正文 3.文章固定链接 4.显示分类文章列表 5.显示评论列表 6.发表评论与回复 7.支持回复评论 8.网站主题切换 Python个人博客程序开发实例框架设计中,我们已经完成了 数据库设计.数据准备.模板架构.表单设计.视图函数设计.电子邮件支持 等总体设计的内容,本篇博客将介绍博客前台的实现.博客前台需要开放给所有用户,这里包括 显示文章列表.博客信息.文章内容和评论 等功能. 1.分页显示文章列表 为了
-
Python个人博客程序开发实例后台编写
目录 1.文章管理 1.1 文章管理主页 1.2 创建文章 1.3 编辑与删除 2.评论管理 2.1 关闭评论 2.2 评论审核 2.3 筛选评论 3.分类管理 本篇博客将是Python个人博客程序开发实例的最后一篇.本篇文章将会详细介绍博客后台的编写. 为了支持管理员管理文章.分类.评论和链接,我们需要提供后台管理功能.通常来说,程序的这一部分被称为管理后台.控制面板或仪表盘等.这里通常会提供网站的资源信息和运行状态,管理员可以统一查看和管理所有资源.管理员面板通常会使用独立样式的界面,所以你
-
使用Python实现博客上进行自动翻页
先上一张代码及代码运行后的输出结果的图! 下面上代码: # coding=utf-8 import os import time from selenium import webdriver #打开火狐浏览器 需要V47版本以上的 driver = webdriver.Firefox()#打开火狐浏览器 url = "http://codelife.ecit-it.com"#这里打开我的博客网站 driver.get(url)#设置火狐浏览器打开的网址 time.sleep(2) #使
-
python采集博客中上传的QQ截图文件
哎,以前写博文的时候没注意,有些图片用QQ来截取,获得的图片文件名都是类似于QQ截图20120926174732-300×15.png的形式,昨天用ftp备份网站文件的时候发现,中文名在flashfxp里面显示的是乱码的,看起来好难受,所以写了一个python小脚本,爬取整个网站,然后获取每个文章页面的图片名,并判断如果是类似于QQ截图20120926174732-300×15.png的形式就输出并将该图片地址和对应的文章地址保存在文件中,然后通过该文件来逐个修改. 好了,下面是程序代码: im
-
Python实现简单的文件传输与MySQL备份的脚本分享
用python实现简单Server/Client文件传输: 服务器端: #!/usr/bin/python import SocketServer, time class MyServer(SocketServer.BaseRequestHandler): userInfo = { 'leonis' : 'leonis', 'hudeyong' : 'hudeyong', 'mudan' : 'mudan' } def handle(self): print 'Connected from',
-
python实现博客文章爬虫示例
复制代码 代码如下: #!/usr/bin/python#-*-coding:utf-8-*-# JCrawler# Author: Jam <810441377@qq.com> import timeimport urllib2from bs4 import BeautifulSoup # 目标站点TargetHost = "http://adirectory.blog.com"# User AgentUserAgent = 'Mozilla/5.0 (X11; Lin
-
Python实现过滤单个Android程序日志脚本分享
在Android软件开发中,增加日志的作用很重要,便于我们了解程序的执行情况和数据.Eclipse开发工具会提供了可视化的工具,但是还是感觉终端效率会高一些,于是自己写了一个python的脚本来通过包名来过滤某一程序的日志. 原理 通过包名得到对应的进程ID(可能多个),然后使用adb logcat 过滤进程ID即可得到对应程序的日志. 源码 复制代码 代码如下: #!/usr/bin/env python #coding:utf-8 #This script is aimed to grep
-
Windows下简单的Mysql备份BAT脚本分享
前言 本文介绍的是一个简单的在 Windows 下备份 Mysql 的 BAT 脚本,脚本使用 mysqldump 命令来备份一个指定的 Mysql 数据库到一个文件,文件格式为 %dbname%-yyyyMMddHHmmss.sql,只保留最近60天的备份.如果想定时执行,在 Windows 中添加任务计划即可,具体的可以参考这篇文章. 示例代码如下 @echo off set hour=%time:~0,2% if "%time:~0,1%"==" " set