Android协程作用域与序列发生器限制介绍梳理
目录
- 一.受限协程作用域
- 1.sequence方法
- 2.SequenceScope类
- 二.序列发生器
- 1.Sequence接口
- 2.Sequence方法
- 3.iterator方法
- 4.SequenceBuilderIterator类
- 1.SequenceBuilderIterator类的全局变量
- 2.yield方法与yieldAll方法
- 3.hasNext方法
- 4.next方法
- 5.总结
一.受限协程作用域
在协程的基础与使用中提到,可以通过sequence方法构建一个序列发生器。但当在sequence方法中调用除了yield方法与yieldAll方法以外的其他挂起方法时,就会报错。比如在sequence方法中调用delay方法,就会产生下面的报错提示:

翻译过来大致是“受限的挂起方法只能调用自身受限的协程作用域内的成员变量或挂起方法。这是什么意思呢?
1.sequence方法
sequence方法就是构建序列发生器用到的方法,内部通过Sequence方法实现,代码如下:
@SinceKotlin("1.3")
public fun <T> sequence(@BuilderInference block: suspend SequenceScope<T>.() -> Unit): Sequence<T> = Sequence { iterator(block) }
其中参数block是一个在SequenceScope环境下的lambda表达式。
2.SequenceScope类
// 注意
@RestrictsSuspension
@SinceKotlin("1.3")
public abstract class SequenceScope<in T> internal constructor() {
// 向迭代器中提供一个数值
public abstract suspend fun yield(value: T)
// 向迭代器中提供一组数值
public abstract suspend fun yieldAll(iterator: Iterator<T>)
// 向迭代器中提供Collection类型的一组数值
public suspend fun yieldAll(elements: Iterable<T>) {
if (elements is Collection && elements.isEmpty()) return
return yieldAll(elements.iterator())
}
// 向迭代器中提供Sequence类型的一组数值
public suspend fun yieldAll(sequence: Sequence<T>) = yieldAll(sequence.iterator())
}
SequenceScope类是一个独立的抽象类,没有继承任何的类。它提供了四个方法,只要都是用来向外提供数值或对象。而该类成为受限协程作用域的关键在于该类被RestrictsSuspension注解修饰,代码如下:
@SinceKotlin("1.3")
@Target(AnnotationTarget.CLASS)
@Retention(AnnotationRetention.BINARY)
public annotation class RestrictsSuspension
RestrictsSuspension注解用于修饰一个类或接口,表示该类是受限的。在被该注解修饰的类的扩展挂起方法中,只能调用该注解修饰的类中定义的挂起方法,不能调用其他类的挂起方法。
具体的,在sequence方法中,block就是SequenceScope类的扩展方法,因此在block中,只能使用SequenceScope类中提供的挂起方法——yield方法和yieldAll方法。同时,SequenceScope类的构造器被internal修饰,无法在外部被继承,因此也就无法定义其他的挂起方法。
为什么受限协程作用域不允许调用其他的挂起方法呢?
因为当一个方法挂起协程时,会获取协程的续体,同时协程需要等待方法执行完毕后的回调,这意味着会暴露协程的续体。可能会造成挂起协程执行的不确定性。
二.序列发生器
1.Sequence接口
首先来分析一下Sequence接口,代码如下:
public interface Sequence<out T> {
public operator fun iterator(): Iterator<T>
}
2.Sequence方法
在协程中,有一个与Sequence接口同名的方法,该方法用于返回一个实现了Sequence接口的对象,代码如下:
@kotlin.internal.InlineOnly
public inline fun <T> Sequence(crossinline iterator: () -> Iterator<T>): Sequence<T> = object : Sequence<T> {
override fun iterator(): Iterator<T> = iterator()
}
Sequence方法返回了一个匿名对象,并通过参数中的lambda表达式iterator实现了接口中的iterator方法。
从sequence方法的代码可以知道,用于构建序列发生器的sequence方法内部调用了Sequence方法,同时还调用了iterator方法,将返回的Iterator对象,作为Sequence方法的参数。
3.iterator方法
@SinceKotlin("1.3")
public fun <T> iterator(@BuilderInference block: suspend SequenceScope<T>.() -> Unit): Iterator<T> {
val iterator = SequenceBuilderIterator<T>()
iterator.nextStep = block.createCoroutineUnintercepted(receiver = iterator, completion = iterator)
return iterator
}
iterator方法内部创建了一个SequenceBuilderIterator对象,并且通过createCoroutineUnintercepted方法创建了一个协程,保存到了SequenceBuilderIterator对象的nextStep变量中。可以发现,序列发生器的核心实现都在SequenceBuilderIterator类中。
4.SequenceBuilderIterator类
SequenceBuilderIterator类是用于对序列发生器进行迭代,在该类的内部对状态进行了划分,代码如下:
private typealias State = Int // 没有要发射的数据 private const val State_NotReady: State = 0 private const val State_ManyNotReady: State = 1 // 有要发射的数据 private const val State_ManyReady: State = 2 private const val State_Ready: State = 3 // 数据全部发射完毕 private const val State_Done: State = 4 // 发射过程中出错 private const val State_Failed: State = 5
状态转移图如下:
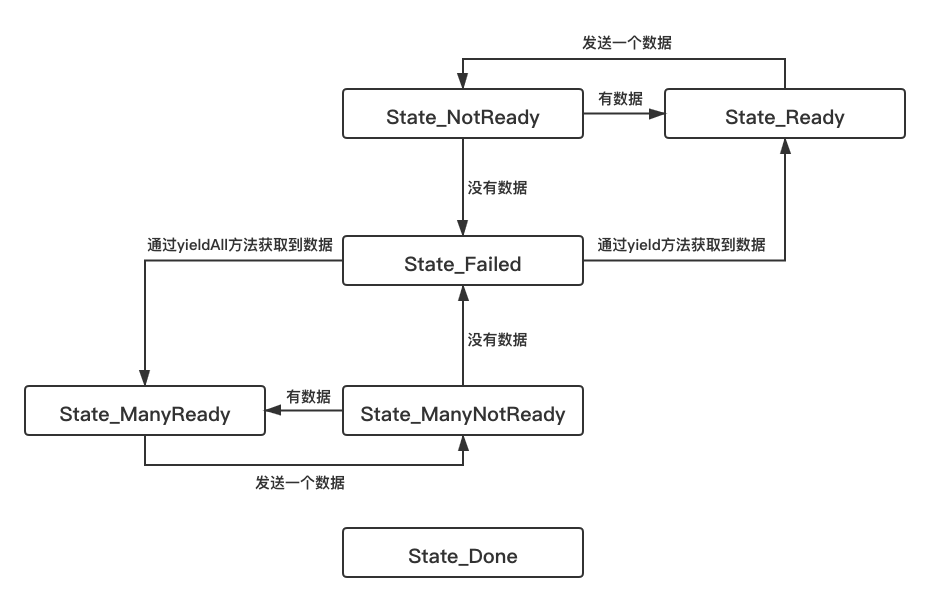
迭代器的初始状态为State_NotReady,由于首次发射没有数据,因此会进入State_Failed状态。
State_Failed状态会从序列发生器中获取数据,如果是通过yield方法获取的数据,则会进入State_Ready状态,如果是通过yieldAll方法获取的数据,则会进入State_ManyReady状态。
当从序列发生器中获取数据时,如果是在State_ManyReady和State_Ready状态,则直接发射一个数据,对应的进入到State_ManyNotReady和State_NotReady状态。如果是在State_ManyNotReady和State_NotReady状态,则会判断是否有数据,如果有数据则对应进入到State_ManyReady和State_Ready状态。如果没有则进入到State_Failed状态,获取数据。
当序列发生器发射完毕时,会进入State_Done状态。
接下来对SequenceBuilderIterator类进行分析。
1.SequenceBuilderIterator类的全局变量
SequenceBuilderIterator类继承自SequenceScope类,实现了Iterator接口和Continuation接口。代码如下:
private class SequenceBuilderIterator<T> : SequenceScope<T>(), Iterator<T>, Continuation<Unit> {
// 迭代器的状态
private var state = State_NotReady
// 迭代器下一个要发送的值
private var nextValue: T? = null
// 用于保存yieldAll方法传入的迭代器
private var nextIterator: Iterator<T>? = null
// 用于获取下一个数据的续体
var nextStep: Continuation<Unit>? = null
...
// 空的上下文
override val context: CoroutineContext
get() = EmptyCoroutineContext
}
为什么SequenceBuilderIterator类的上下文是空的呢?
因为SequenceBuilderIterator类继承了SequenceScope类,因此该类也是受限的,因此不允许在类的扩展方法中调用类内以外的挂起方法。自然也就不能进行调度、拦截等操作,所以上下文为空。在协程中,受限协程的上下文一般都是空上下文。
2.yield方法与yieldAll方法
yield方法与yieldAll方法是SequenceScope类中定义的两个方法,在SequenceBuilderIterator类中的实现如下:
// 发射一个数据
override suspend fun yield(value: T) {
// 保存数据到全局变量中
nextValue = value
// 修改状态
state = State_Ready
// 挂起协程,获取续体
return suspendCoroutineUninterceptedOrReturn { c ->
// 保存续体到全局变量中
nextStep = c
// 挂起
COROUTINE_SUSPENDED
}
}
// 发射多个数据
override suspend fun yieldAll(iterator: Iterator<T>) {
// 如果迭代器没有数据,则直接返回
if (!iterator.hasNext()) return
// 如果有数据,则保存到全局变量
nextIterator = iterator
// 修改状态
state = State_ManyReady
// 挂起协程,获取续体
return suspendCoroutineUninterceptedOrReturn { c ->
// 保存续体到全局变量中
nextStep = c
// 挂起
COROUTINE_SUSPENDED
}
}
通过上面的代码可以知道,yield方法和yieldAll方法主要做了三件事情,挂起协程、修改状态、保存要发送的数据和续体。而yieldAll发射多个数据原理在于保存了参数中Iterator接口指向的对象,通过迭代器获取数据。
3.hasNext方法
hasNext方法是Iterator接口中定义的方法,用于迭代时判断是否还有数据,代码如下:
override fun hasNext(): Boolean {
// 循环
while (true) {
// 判断状态
when (state) {
// 刚通过yield方法发射数据
State_NotReady -> {}
// 刚通过yieldAll方法发射数据
State_ManyNotReady ->
// 如果迭代器中还有数据
if (nextIterator!!.hasNext()) {
// 修改状态,返回true
state = State_ManyReady
return true
} else {
// 没有数据,则置空,丢弃迭代器
nextIterator = null
}
// 如果序列发生器已经发射完数据,返回false
State_Done -> return false
// 如果有数据,则直接返回true
State_Ready, State_ManyReady -> return true
// 其他状态,则抛出异常
else -> throw exceptionalState()
}
// 走到这里,说明需要去获取下一个数据
// 修改状态
state = State_Failed
// 获取全局保存的续体
val step = nextStep!!
// 置空
nextStep = null
// 恢复序列发生器的执行,直到遇到yield方法或yieldAll方法挂起
step.resume(Unit)
}
}
// 异常状态的处理
private fun exceptionalState(): Throwable = when (state) {
State_Done -> NoSuchElementException()
State_Failed -> IllegalStateException("Iterator has failed.")
else -> IllegalStateException("Unexpected state of the iterator: $state")
}
4.next方法
next方法也是Iterator接口中定义的方法,用于在迭代器中存在数据时获取数据,代码如下:
override fun next(): T {
// 判断状态
when (state) {
// 如果当前处于已经发射完数据的状态,则判断是否有数据
State_NotReady, State_ManyNotReady -> return nextNotReady()
// 如果通过yieldAll方法获取到了数据
State_ManyReady -> {
// 修改状态
state = State_ManyNotReady
// 通过迭代器获取数据
return nextIterator!!.next()
}
// 如果通过yield方法获取到了数据
State_Ready -> {
// 修改状态
state = State_NotReady
// 获取保存的数据并进行类型转换
@Suppress("UNCHECKED_CAST")
val result = nextValue as T
// 全局变量置空
nextValue = null
// 返回数据
return result
}
// 其他情况,则抛出异常
else -> throw exceptionalState()
}
}
// 如果没有数据,则抛出异常,有数据,则返回数据
private fun nextNotReady(): T {
if (!hasNext()) throw NoSuchElementException() else return next()
}
5.总结
当使用序列发生器进行迭代时,首先会调用hasNext方法,hasNext方法会通过保存的续体,恢复序列发生器所在的协程继续执行,获取下一次待发射的数据。如果获取了到数据,则会返回true,这样之后通过next方法就可以获取到对应的数据。
当序列发生器所在的协程在执行中遇到yield方法时,会发生挂起,同时将下一次待发射的数据保存起来。如果遇到的是yieldAll方法,则保存的是迭代器,下一次发射数据时会从迭代器中获取。
到此这篇关于Android协程作用域与序列发生器限制介绍梳理的文章就介绍到这了,更多相关Android协程作用域内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

一文了解Android ViewModelScope 如何自动取消协程
先看一下 ViewModel 中的 ViewModelScope 是何方神圣 val ViewModel.viewModelScope: CoroutineScope get() { val scope: CoroutineScope? = this.getTag(JOB_KEY) if (scope != null) { return scope } return setTagIfAbsent(JOB_KEY, CloseableCoroutineScope(SupervisorJob() +
-
Android序列化XML数据
什么是XML?首先我们先了解一下什么是XML.XML,可扩展标记语言 (Extensible Markup Language) ,用于标记电子文件使其具有结构性的标记语言,可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言,这是百度百科的解释.而XML是一种在Internet中传输数据的常见格式,它与HTML一样,都是SGML(标准通用标记语言),无论你是需要通过Internet访问数据,或者发送数据给Web服务,都可能需要用到XML的知识.恰恰Android应用程序
-
Android应用获取设备序列号的方法
软硬件环境 Macbook Pro MGX 72 Android studio 2.1.2 Android 5.1.1 前言 上一篇介绍了如何获取ethernet的MAC地址,对于厂商来讲,除了MAC号,还有一项数据也很重要,那就是机器序列号,它是机器出厂时确定的,也是主要标识,每台机器都不一样. 要想获取到序列号,必须要先知道序列号从哪里来,写到了哪里.一般情况下,序列号都是厂商自己定义的一串字串,字串中的某几位会有不同含义,比如厂商的ID.出厂时间.机器类型等,另外,运营商定义的序列号几乎也
-
Android 序列化的存储和读取总结及简单使用
Android 序列化 1.序列化的目的 (1).永久的保存对象数据(将对象数据保存在文件当中,或者是磁盘中 (2).通过序列化操作将对象数据在网络上进行传输(由于网络传输是以字节流的方式对数据进行传输的.因此序列化的目的是将对象数据转换成字节流的形式) (3).将对象数据在进程之间进行传递(Activity之间传递对象数据时,需要在当前的Activity中对对象数据进行序列化操作.在另一个Activity中需要进行反序列化操作讲数据取出) (4).Java平台允许我们在内存中创建
-
Android中的Coroutine协程原理解析
前言 协程是一个并发方案.也是一种思想. 传统意义上的协程是单线程的,面对io密集型任务他的内存消耗更少,进而效率高.但是面对计算密集型的任务不如多线程并行运算效率高. 不同的语言对于协程都有不同的实现,甚至同一种语言对于不同平台的操作系统都有对应的实现. 我们kotlin语言的协程是 coroutines for jvm的实现方式.底层原理也是利用java 线程. 基础知识 生态架构 相关依赖库 dependencies { // Kotlin implementation "org.jetb
-
Android中的序列化浅析
序列化原因 序列化的原因基本可以归纳为以下三种情况: 1.永久性保存对象,保存对象的字节序列到本地文件中: 2.对象在网络中传递: 3.对象在IPC间传递. 序列化方法 在Android系统中关于序列化的方法一般有两种,分别是实现Serializable接口和Parcelable接口,其中Serializable接口是来自Java中的序列化接口,而Parcelable是Android自带的序列化接口. 上述的两种序列化接口都有各自不同的优缺点,我们在实际使用时需根据不同情况而定. 1.Seria
-
很详细的android序列化过程Parcelable
直接上代码:注释都写的很清楚了. public class Entry implements Parcelable{ public int userID; public String username; public boolean isMale; public Book book;//序列化对象可以嵌套序列化对象,前提是2个类的对象都被序列号过 //几乎所有情况下都返回0,可以不管 @Override public int describeContents() { return 0; } //
-
Android kotlin+协程+Room数据库的简单使用
Room Room是Google为了简化旧版的SQLite操作专门提供的 1.拥有了SQLite的所有操作功能 2.使用简单(类似于Retrofit),通过注解的方式实现相关功能.编译时自动生成实现类impl 3.LiveData,LifeCycle,Paging天然融合支持 导入 ... plugins { id 'com.android.application' id 'kotlin-android' id 'kotlin-android-extensions' id 'kotlin-kap
-
Android协程作用域与序列发生器限制介绍梳理
目录 一.受限协程作用域 1.sequence方法 2.SequenceScope类 二.序列发生器 1.Sequence接口 2.Sequence方法 3.iterator方法 4.SequenceBuilderIterator类 1.SequenceBuilderIterator类的全局变量 2.yield方法与yieldAll方法 3.hasNext方法 4.next方法 5.总结 一.受限协程作用域 在协程的基础与使用中提到,可以通过sequence方法构建一个序列发生器.但当在sequ
-
Kotlin创建一个好用的协程作用域
目录 前言 正文 前言 kotlin中使用协程,是一定要跟协程作用域一起配合使用的,否则可能协程的生命周期无法被准确控制,造成内存泄漏或其他问题. 我们一般在安卓项目中使用协程作用域,可能会在BaseActtivity中new 一个MainScope(),并在onDestory时cancel掉,或者只在ViewModel中使用viewModelScope,然后会在ViewModel的onClose中自动cancel掉. 但我们可能不只需要这些效果,比如在协程作用域中拿到Context或Activ
-
协程作用域概念迭代RxTask 实现自主控制
目录 结合协程作用域概念迭代 RxTask 实现作用域功能 作用域的设想及机制 ITaskScope 的实现 基于 Android 平台拓展支持 总结 结合协程作用域概念迭代 RxTask 实现作用域功能 在过去的一段时间里有幸接触过某个项目,整体技术方案落后且线程滥用导致出现大量的内存泄漏或者资源反复耗费.原因在于这个项目中对 RxJava 创建操作不规范,反复创建线程且不及时消耗导致,刚好朋友在使用我的 RxTask 开源项目中也给我反馈一件事,能否提供一个类似像协程作用域概念,当被告知需要
-
Unity中协程IEnumerator的使用方法介绍详解
在Unity中,一般的方法都是顺序执行的,一般的方法也都是在一帧中执行完毕的,当我们所写的方法需要耗费一定时间时,便会出现帧率下降,画面卡顿的现象.当我们调用一个方法想要让一个物体缓慢消失时,除了在Update中执行相关操作外,Unity还提供了更加便利的方法,这便是协程. 在通常情况下,如果我们想要让一个物体逐渐消失,我们希望方法可以一次调用便可在程序后续执行中实现我们想要的效果. 我们希望代码可以写成如下所示: void Fade() { for (float f = 1f; f >= 0;
-
golang协程与线程区别简要介绍
目录 一.进程与线程 二.并发与并行 三.go协程与线程 1.调度方式 2.调度策略 3.上下文切换速度 4.栈的大小 四.GMP模型 一.进程与线程 进程是操作系统资源分配的基本单位,是程序运行的实例.例如打开一个浏览器就开启了一个进程. 线程是操作系统调度到CPU中执行的基本单位.例如在浏览器里新建一个窗口就需要一个线程来进行处理. 在一般情况下,线程是进程的组成部分,一个进程可以包含多个线程.例如浏览器可以新建多个窗口. 进程中的多个线程并发执行并共享进程的内存等资源.例如多个窗口之间可以
-
Kotlin协程概念原理与使用万字梳理
目录 一.协程概述 1.概念 2.特点 3.原理 二.协程基础 1.协程的上下文 2.协程的作用域 3.协程调度器 4.协程的启动模式 5.协程的生命周期 三.协程使用 1.协程的启动 2.协程间通信 3.多路复用 4.序列生成器 5.协程异步流 6.全局上下文 一.协程概述 1.概念 协程是Coroutine的中文简称,co表示协同.协作,routine表示程序.协程可以理解为多个互相协作的程序.协程是轻量级的线程,它的轻量体现在启动和切换,协程的启动不需要申请额外的堆栈空间:协程的切换发生在
-
kotlin之协程的理解与使用详解
前言 为什么在kotlin要使用协程呢,这好比去了重庆不吃火锅一样的道理.协程的概念并不陌生,在python也有提及.任何事务的作用大多是对于所依赖的环境相应而生的,协程对于kotlin这门语言也不例外.协程的优点,总的来说有如下几点:轻量级,占用更少的系统资源: 更高的执行效率: 挂起函数较于实现Runnable或Callable接口更加方便可控: kotlin.coroutine 核心库的支持,让编写异步代码更加简单.当然在一些不适应它的用法下以上优势也会成为劣势. 1.协程
-
kotlin 协程上下文异常处理详解
目录 引言 一.协程上下文 1.CoroutineContext 2.CorountineScope 3.子协程继承父协程 二.协程的异常传递 1.协程的异常传播 2.不同上下文(没有继承关系)之间协程异常会怎么样? 3.向用户暴露异常 三.协程的异常处理 使用SupervisorJob 异常捕获器CoroutineExceptionHandler Android中全局异常的处理 引言 从前面我们可以大致了解了协程的玩法,如果一个协程中使用子协程,那么该协程会等待子协程执行结束后才真正退出,而达
-
详解c++20协程如何使用
什么是协程 新接触的人看了网上很多人的见解都是一头雾水,本人的理解,协程就是可中断的函数,这个函数在执行到某一时刻可以暂停,保存当前的上下文(比如当前作用域的变量,函数参数等等),在后来某一时刻可以手动恢复这个中断的函数,把保存的上下文恢复并从中断的地方继续执行.简而言之,协程就是可中断的函数,协程如何实现:保存上下文和恢复上下文. 你可能会说协程不会这么简单的吧,我这里来举例一下啊,如python的协程 def test(): print('begin') yield print('hello
-
Kotlin协程操作之创建启动挂起恢复详解
目录 一.协程的创建 1.start方法 2.CoroutineStart类 3.startCoroutineCancellable方法 4.createCoroutineUnintercepted方法 5.createCoroutineFromSuspendFunction方法 二.协程的启动 1.ContinuationImpl类 2.resumeCancellableWith方法 3.BaseContinuationImpl类 4.invokeSuspend方法 三.协程的挂起与恢复 下面