MySQL中索引的优化的示例详解
目录
- 使用索引优化
- 数据准备
- 避免索引失效应用-全值匹配
- 避免索引失效应用-最左前缀法则
- 避免索引失效应用-其他匹配原则
使用索引优化
索引是数据库优化最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数的MySQL的性能优化问题。
数据准备
use world;
create table tb_seller(
sellerid varchar(100),
name varchar(100),
nickname varchar(50),
password varchar(60),
status varchar(1),
address varchar(100),
createtime datetime,
primary key(sellerid)
);
insert into tb_seller values('alibaba','阿里巴巴','阿里小店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('baidu','百度科技有限公司','百度小店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('huawei','华为科技有限公司','华为小店','e10adc3949ba59abbe057f20f883e','0','北京市','2088-01-01 12:00:00'),
('itcast','传智播客教育科技有限公司','传智播客','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('itheima','黑马程序员','黑马程序员','e10adc3949ba59abbe057f20f883e','0','北京市','2088-01-01 12:00:00'),
('luoji','罗技科技有限公司','罗技小店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('oppo','oppo科技有限公司','oppo官方旗舰店','e10adc3949ba59abbe057f20f883e','0','北京市','2088-01-01 12:00:00'),
('ourpalm','掌趣科技股份有限公司','掌趣小店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('qiandu','千度科技','千度小店','e10adc3949ba59abbe057f20f883e','2','北京市','2088-01-01 12:00:00'),
('sina','新浪科技有限公司','新浪官方旗舰店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('xiaomi','小米科技','小米官方旗舰店','e10adc3949ba59abbe057f20f883e','1','西安市','2088-01-01 12:00:00'),
('yijia','宜家家居','宜家官方旗舰店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00');
-- 创建组合索引
create index index_seller_name_sta_addr on tb_seller(name,status,address);
避免索引失效应用-全值匹配
该情况下,索引生效,执行效率高。
-- 避免索引失效应用-全值匹配 -- 全值匹配,和字段匹配成功即可,和字段顺序无关 explain select * from tb_seller ts where name ='小米科技' and status ='1' and address ='北京市'; explain select * from tb_seller ts where status ='1' and name ='小米科技' and address ='北京市';
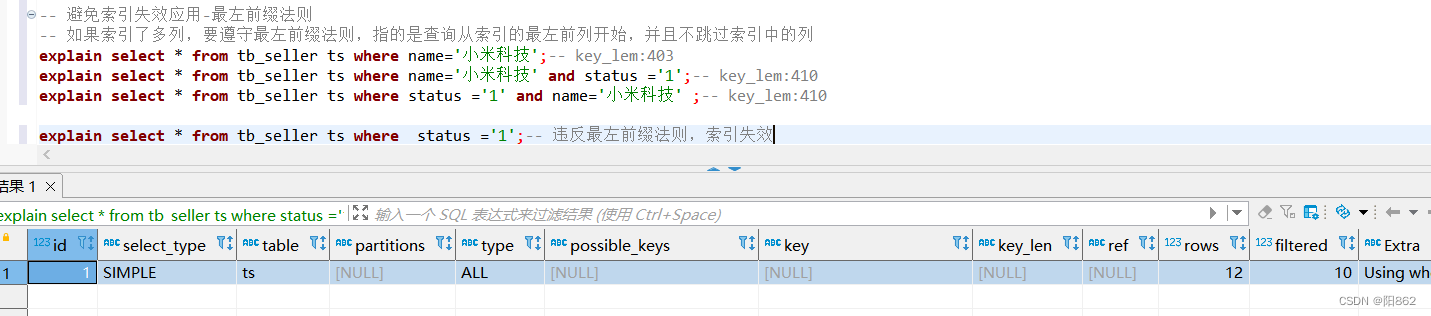
避免索引失效应用-最左前缀法则
该情况下,索引生效,执行效率高。
-- 避免索引失效应用-最左前缀法则 -- 如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始,并且不跳过索引中的列 explain select * from tb_seller ts where name='小米科技';-- key_lem:403 explain select * from tb_seller ts where name='小米科技' and status ='1';-- key_lem:410 explain select * from tb_seller ts where status ='1' and name='小米科技' ;-- key_lem:410,依然跟顺序无关 -- 违反最左前缀法则,索引失效 explain select * from tb_seller ts where status ='1';-- 违反最左前缀法则,索引失效 -- 如果符合最左前缀法则,但是出现跳跃某一列,只有最左列索引生效 explain select * from tb_seller where name='小米科技' and address='北京市';-- key_lem:403
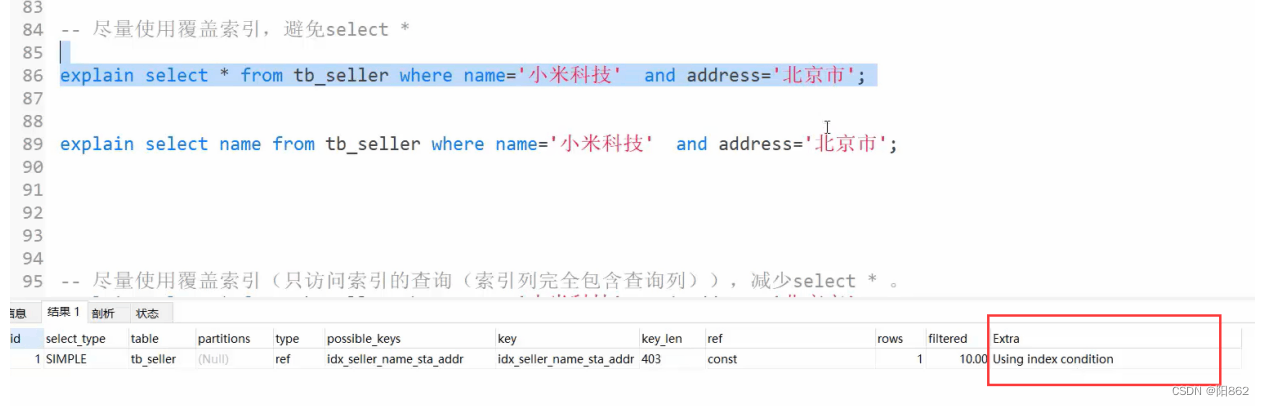
避免索引失效应用-其他匹配原则
该情况下,索引生效,执行效率高。
1、情况一

-- 避免索引失效应用-其他匹配原则 -- 范围查询右边的列,不能使用索引 explain select * from tb_seller where name= '小米科技' and status >'1' and address='北京市';-- key_lem:410,没有使用status这个索引 -- 不要在索引列上进行运算操作,索引将失效。 explain select * from tb_seller where substring(name,3,2) ='科技';-- 没有使用索引 -- 字符串不加单引号,造成索引失效。 explain select * from tb_seller where name='小米科技' and status = 1 ;-- key_lem:403,没有使用status这个索引
2、 情况二
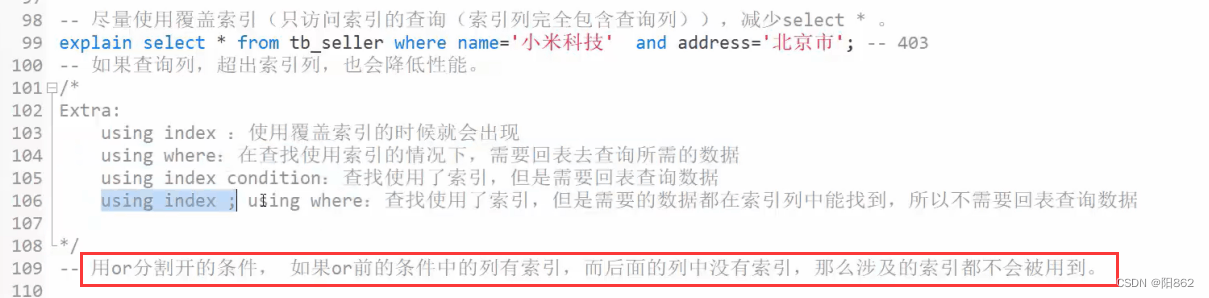
explain中的extra列
| extra | 含义 |
| using filesort | 说明mysq|会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,称为“文件排序" ,效率低。 |
| using temporary | 需要建立临时表(temporary table)来暂存中间结果,常见于order by和group by;效率低 |
| using index | SQL所需要返回的所有列数据均在一棵索引树上,避免访问表的数据行,效率不错 |
| using where | 在查找使用索引的情况下,需要回表去查询所需的数据 |
| using index condition | 查找使用了索引,但是需要回表查询数据 |
| using index;using where | 查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据 |



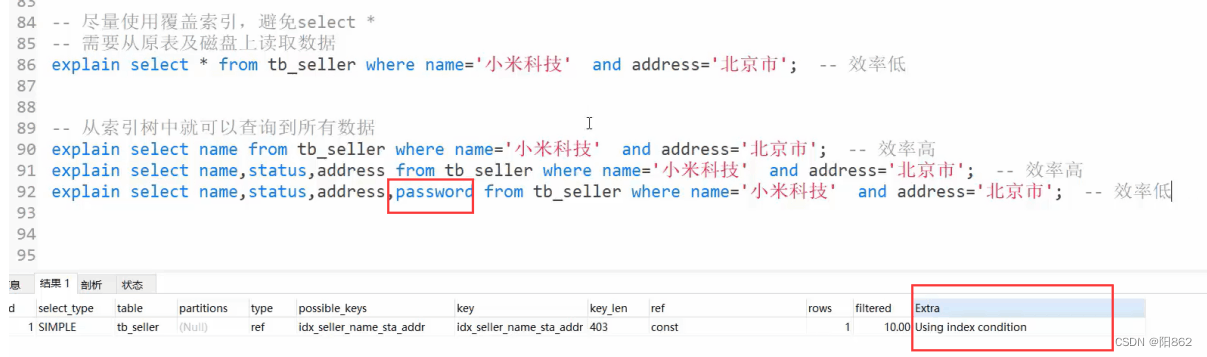
但是再加有个password
3、情况三
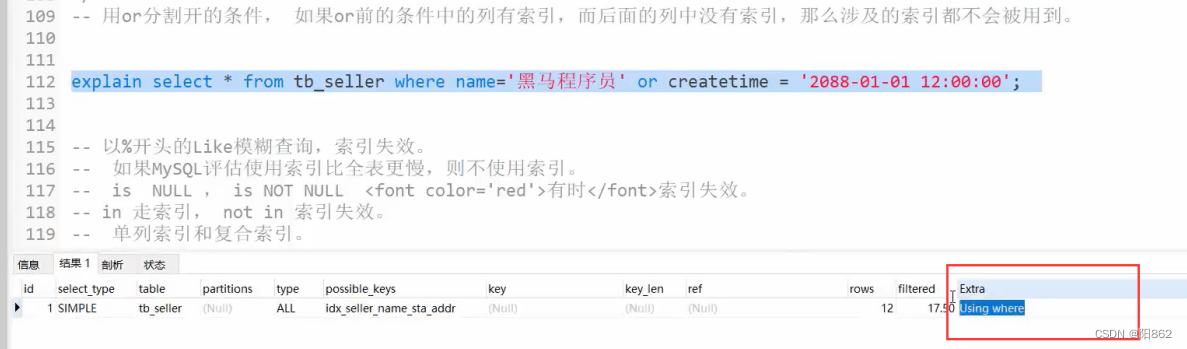
4、情况四
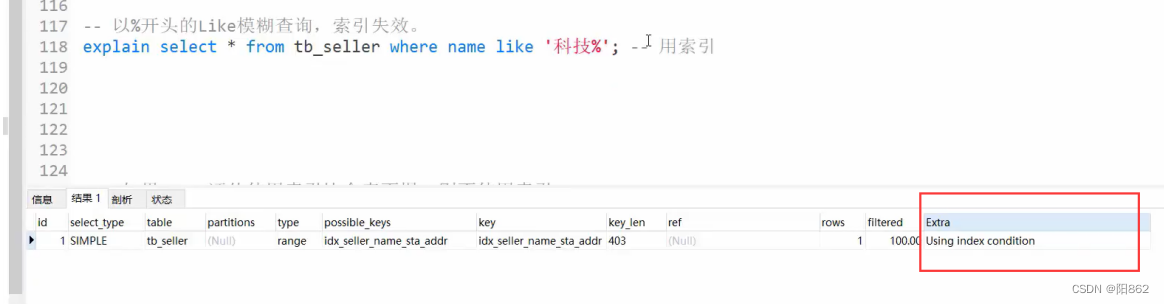

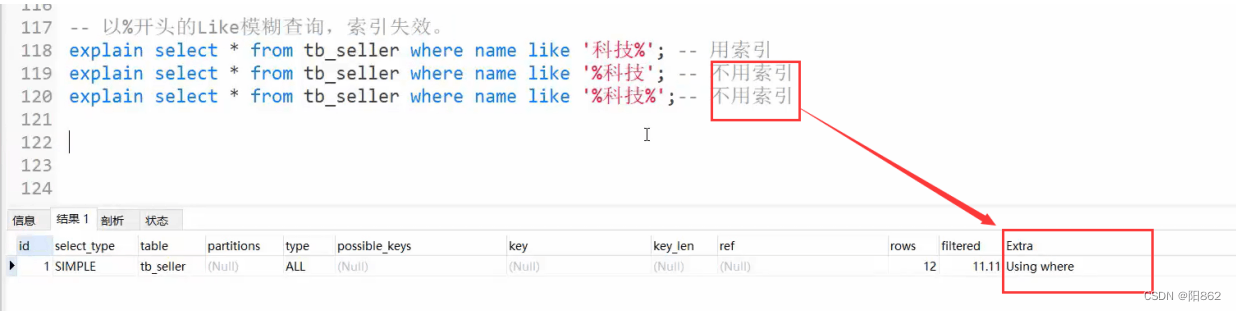

5、 如果MySQL评估使用索引比全表更慢,则不使用索引。is NULL , is NOT NULL有时有效,有时索引失效。in走索引,not in索引失效。单列索引和复合索引,尽量使用符合索引
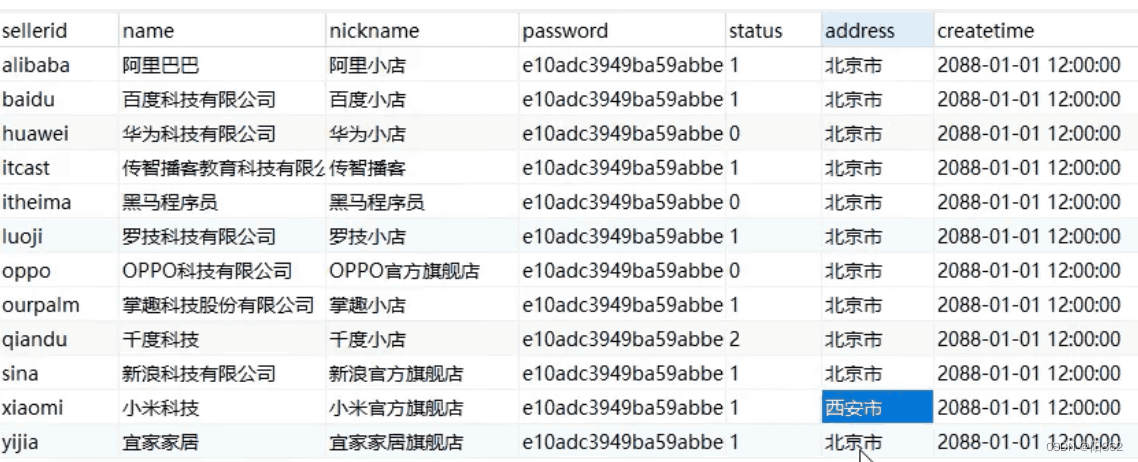



验证

创建了单一的三个索引,最后面where全使用了但explain显示只用了index_name
到此这篇关于MySQL中索引的优化的示例详解的文章就介绍到这了,更多相关MySQL索引优化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL约束与索引概念详解
目录 一.关系型数据库设计规则 二.数据完整性和约束与索引的概念 三.约束的应用 一.关系型数据库设计规则 遵循ER模型和三范式 E entity 代表实体的意思 对应到数据库当中的一张表 R relationship 代表关系的意思 三范式: 1.列不能拆分 2.唯一标识 3.关系引用主键 具体体现 将数据放到表中,表再放到库中. 一个数据库中可以有多个表,每个表都有一个名字,用来标识自己.表名具有唯一性. 表具有一些特性,这些特性定义了数据在表中如何存储,类似java和python 中 “类
-
深入解析MySQL索引的原理与优化策略
目录 索引的概念 索引的原理 索引的类型 索引的使用 索引的使用方式 注意事项 索引优化技巧 索引的概念 MySQL索引是一种用于加速数据库查询的数据结构,它类似于书籍的目录,能够快速指导我们找到需要的信息.MySQL索引可以根据一定的算法和数据结构进行排序和存储,从而实现高效的数据查找和访问.在数据库中,索引可以加速数据的查询和更新操作,提高系统性能. MySQL支持多种索引类型,常见的包括B-tree索引.哈希索引和全文索引等.其中,B-tree索引是最常用的一种,它是一种平衡树结构,可以将
-
MySQL进阶之索引
目录 索引概述 介绍 特点 索引结构 索引进化的过程 B-Tree 索引概述 介绍 索引(index)是帮助MySQL高效获取数据的数据结构(有序).在数据之外,数据库系统还维护着满足 特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构 上实现高级查找算法,这种数据结构就是索引. 索引就是一种数据结构,这种结构类似,链表,树等等.但是比它们要复杂的多. 为什么要用索引呢? 假如我们有如下数据 如果我们要查询年龄=45的全部信息. select * from
-
MySQL索引总结(Index Type)
目录 MySQL Index 1.创建和删除索引 2. 索引类型 MySQL Index 索引是一种数据结构,可以是B-tree.R-tree.或者hash结构.其中,B-tree适用于查找某范围内的数据,可以快速地从当前数据找到吓一跳数据:R-tree常用于查询比较接近的数据:hash结构适用于随机访问场景,查找每条数据时间几乎一致. 优化查询的有效方法是为经常查询的字段建立索引,如无索引查询数据时,会遍历整张表:若建立索引后查找起来会更快速.当进行update.delete.insert操作
-

MySQL中执行计划explain命令示例详解
前言 explain命令是查看查询优化器如何决定执行查询的主要方法. 这个功能有局限性,并不总会说出真相,但它的输出是可以获取的最好信息,值得花时间去了解,因为可以学习到查询是如何执行的. 调用EXPLAIN 在select之前添加explain,mysql会在查询上设置一个标记,当执行查询计划时,这个标记会使其返回关于执行计划中每一步的信息,而不是执行它. 它会返回一行或多行信息,显示出执行计划中的每一部分和执行次序. 这是一个简单的explain效果: 在查询中每个表在输出只有一行,如果查询
-
MySQL中的行级锁定示例详解
前言 锁是在执行多线程时用于强行限定资源访问的同步机制,数据库锁根据锁的粒度可分为行级锁,表级锁和页级锁 行级锁 行级锁是mysql中粒度最细的一种锁机制,表示只对当前所操作的行进行加锁,行级锁发生冲突的概率很低,其粒度最小,但是加锁的代价最大.行级锁分为共享锁和排他锁. 特点: 开销大,加锁慢,会出现死锁:锁定粒度最小,发生锁冲突的概率最大,并发性也高: 实现原理: InnoDB行锁是通过给索引项加锁来实现的,这一点mysql和oracle不同,后者是通过在数据库中对相应的数据行加锁来实现的,
-
Mysql中索引和约束的示例语句
外键 查询一个表的主键是哪些表的外键 SELECT TABLE_NAME, COLUMN_NAME, CONSTRAINT_NAME, REFERENCED_TABLE_NAME, REFERENCED_COLUMN_NAME FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE TABLE_SCHEMA = 'mydbname' AND REFERENCED_TABLE_NAME = '表名'; 导出所有外键语句 SELECT CONCAT('ALTER
-
MySQL教程数据定义语言DDL示例详解
目录 1.SQL语言的基本功能介绍 2.数据定义语言的用途 3.数据库的创建和销毁 4.数据库表的操作(所有演示都以student表为例) 1)创建表 2)修改表 3)销毁表 如果你是刚刚学习MySQL的小白,在你看这篇文章之前,请先看看下面这些文章.有些知识你可能掌握起来有点困难,但请相信我,按照我提供的这个学习流程,反复去看,肯定可以看明白的,这样就不至于到了最后某些知识不懂却不知道从哪里下手去查. <MySQL详细安装教程> <MySQL完整卸载教程> <这点基础都不懂
-
Go语言中的字符串处理方法示例详解
1 概述 字符串,string,一串固定长度的字符连接起来的字符集合.Go语言的字符串是使用UTF-8编码的.UTF-8是Unicode的实现方式之一. Go语言原生支持字符串.使用双引号("")或反引号(``)定义. 双引号:"", 用于单行字符串. 反引号:``,用于定义多行字符串,内部会原样解析. 示例: // 单行 "心有猛虎,细嗅蔷薇" // 多行 ` 大风歌 大风起兮云飞扬. 威加海内兮归故乡. 安得猛士兮守四方! ` 字符串支持转义
-
Mysql联表update数据的示例详解
1.MySQL UPDATE JOIN语法 在MySQL中,可以在 UPDATE语句 中使用JOIN子句执行跨表更新.MySQL UPDATE JOIN的语法如下: UPDATE T1, T2, [INNER JOIN | LEFT JOIN] T1 ON T1.C1 = T2. C1 SET T1.C2 = T2.C2, T2.C3 = expr WHERE condition 更详细地看看MySQL UPDATE JOIN语法: 首先,在UPDATE子句之后,指定主表(T1)和希望主表连接表
-
MySQL中replace into与replace区别详解
目录 0.故事的背景 1.replace into 的使用方法 2.有唯一索引时—replace into & 与replace 效果 3.没有唯一索引时—replace into 与 replace 1).replace函数的具体情况 2).replace into 函数的具体情况 4.replace的用法 本篇为抛砖引玉篇,之前没关注过replace into 与replace 的区别.经过多个场景测试,居然没找到在插入数据的时候两者有什么本质的区别?如果了解详情的伙伴们,请告知留言告知一二
-
react中使用antd及immutable示例详解
目录 一.react中使用antd组件库 二.Immutable 2.1 深拷贝和浅拷贝的关系 2.2 immutable优化性能方式 2.3 immutable的Map使用 2.4 immutable的List使用 2.5 实际场景formJS 三.redux中使用immutable 一.react中使用antd组件库 运行命令create-react-app antd-react创建新项目: 运行命令npm i antd安装: 使用: import React from 'react' im
-
Go语音开发中常见Error类型处理示例详解
目录 前言 透明错误处理策略 带来的问题 哨兵(Sentinel)错误处理策略 带来的问题 1.对errors.Error()的依赖 2.定义的错误类型会被公开 Error types 带来的问题 不透明错误处理策略(Opaque errors) 带来的问题 总结 前言 上文我们了解了 Error 在Go 中的设计理念.单从理念上来看, Error 的设计似乎有利于逻辑处理.但实际上,在开发过程中,我们还会遇到各种各样的困难.为了优化开发的流程,开发者们发明了很多处理 Error 的做法.今天我
-
Golang中的错误处理的示例详解
目录 1.panic 2.包装错误 3.错误类型判断 4.错误值判断 1.panic 当我们执行panic的时候会结束下面的流程: package main import "fmt" func main() { fmt.Println("hello") panic("stop") fmt.Println("world") } 输出: go run 9.go hellopanic: stop 但是panic也是可以捕获的,我们可