MySQL联合查询实现方法详解
联合查询简单说 就是将两次查询合并在一起
例如 我们这里有一个用户表

我们先编写一段SQL
select name from staff where age > 21;
查询年龄大于21的 输出结果如下

然后我们再写一段sql
select name from staff where status =1;
查询 status 状态字段等于1 的 输出效果如下

然后我们可以二合一一下
select name from staff where age > 21 union all select name from staff where status =1;
输出结果如下

这是 我们两段sql就二合一了
但我发现 因为张三两个条件都达到了 所以他被查询出了两次
如果想去重 我们只需要将 all去掉
参考代码如下
select name from staff where age > 21 union select name from staff where status =1;
查询结果如下
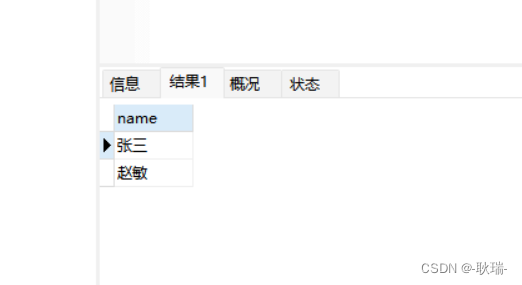
这样就完成去重了
但现在 我们上下 字段列表查的都是 name
如果我们将代码改成这样
select * from staff where age > 21 union select name from staff where status =1;
一个就查name 一个查全部 *
但这样就报错了

我们将两个都改成 *
select * from staff where age > 21 union select * from staff where status =1;

这样就可以查到了
说明 联合查询 多次查询的字段列表必须是一样的
到此这篇关于MySQL联合查询实现方法详解的文章就介绍到这了,更多相关MySQL联合查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL数据库之联合查询 union
目录 1.应用场景 2.基本语法 3.order by的使用 前言: 将多个查询结果的结果集合并到一起(纵向合并),字段数不变,多个查询结果的记录数合并 1.应用场景 同一张表中不同结果合并到一起展示:男生升高升序,女生升高降序 数据量较大的表,进行分表操作,将每张表的数据合并起来显示 2.基本语法 select 语句 union [union 选项] select 语句; union 选项 和select 选项基本一致 distinct 去重,默认 all 保存所有结果 mysql> sele
-

MySQL 数据库聚合查询和联合查询操作
目录 1. 插入被查询的结果 2. 聚合查询 2.1 介绍 2.2 聚合函数 2.3 group by 子句 2.4 having 3. 联合查询 3.1 介绍 3.2 内连接 3.3 外连接 3.4 自连接 3.5 子查询 3.6 合并查询 1. 插入被查询的结果 语法: insert into 要插入的表 [(列1, ..., 列n)] select {* | (列1, ..., 列n)}from 要查询的表 上述语句可以将要查询的表的某些列插入到新的表中对应的某些列 示例1: 将 stud
-
对MySQL几种联合查询的通俗解释
表a aid adate 1 a1 2 a2 3 a3 表b bid bdate 1 b1 2 b2 4 b4 两个表a.b相连接,要取出id相同的字段. select * from a inner join b on a.aid = b.bid 这是仅取出匹配的数据. 此时的取出的是: 1 a1 b1 2 a2 b2 那么left join 指: select * from a left join b on a.aid = b.bid 首先取出a表中所有数据,然后再加上与a.b匹配的的数据.
-
详细聊聊关于Mysql联合查询的那些事儿
目录 联合查询之union 1. 查询中国各省的ID以及省份名称 2. 湖南省所有地级市ID.名字 3. 用union将他们合并 联合查询之union all 联合查询之inner join 1. 查询湖北省有多少地级市 2. 统计各省地级市的数量,输出省名.地级市数量 3. 查询拥有20个以上区县的城市,输出城市名,区县数量 联合查询之三表联合 1. 区县最多的3个城市是哪个省的哪个市,查询结果包括省名,市名,区县数量 联合查询之left join&right join 查询所有省份和它的城市
-
MySQL聚合查询与联合查询操作实例
目录 一.聚合查询 1.聚合函数(count,sum,avg...) 2.GROUPBY子句 3.HAVING 二.联合查询((重点)多表) 1.内连接 2.外连接 3.自连接 4.子查询 5.合并查询 总结 一. 聚合查询 1.聚合函数(count,sum,avg...) 常见的统计总数.计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有: 注意最后面都是可以加上where,order by这些语句的,这些聚合函数会根据这些语句的结果集来进行查询 后面最好不要加上limit,因为MyS
-
详解MySQL 联合查询优化机制
MySQL 联合查询执行策略. 以一个 UNION 查询为例,MySQL 执行 UNION 查询时,会把他们当做一系列的单个查询语句,然后把对应的结果放入到临时表中,最终再读出来返回.在 MySQL中,每个独立的查询都是一个联合查询,从临时表读取返回结果也一样. 这种情形下,MySQL 的联合查询执行很简单--它将这里的联合查询当做是嵌套循环的联合查询.这意味着 MySQL 会运行一个循环去从数据表读取数据行,然而在运行一个嵌套循环从下一个表读取匹配的数据行.这个过程一直持续,直到找到联合查询中
-
MySQL联合查询实现方法详解
联合查询简单说 就是将两次查询合并在一起 例如 我们这里有一个用户表 我们先编写一段SQL select name from staff where age > 21; 查询年龄大于21的 输出结果如下 然后我们再写一段sql select name from staff where status =1; 查询 status 状态字段等于1 的 输出效果如下 然后我们可以二合一一下 select name from staff where age > 21 union all select n
-
Mysql之组合索引方法详解
对于任何DBMS,索引都是进行优化的最主要的因素.对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降. 如果对多列进行索引(组合索引),列的顺序非常重要,MySQL仅能对索引最左边的前缀进行有效的查找.例如: 假设存在组合索引(c1,c2),查询语句select * from t1 where c1=1 and c2=2能够使用该索引.查询语句select * from t1 where c1=1也能够使用该索引.但是,查询语句select * from t1
-
微信小程序多表联合查询的实现详解
目录 一对多表设计 SQL中的关联查询 低码中的表关联 自定义连接器中实现表关联查询 新建连接器 总结 一对一的设计一般不常见,只需要设计到主表中即可,避免增加复杂性.一对多的关系比较常见,一的一方通常作为主表,多的一方通常作为子表.而多对多一般会拆分成两个一对多的关系,这就必须要用中间表进行过渡. 我们本篇介绍的多表查询,侧重在一对多的关系,我们先看一下我们实际的表设计 一对多表设计 我们实现的是文章关注的业务,通常将文章作为主表,而关注信息作为子表.表和表之间要进行关联,常见的设计思路是子表
-
MySQL关联查询优化实现方法详解
目录 左外连接 内连接INNER JOIN 我们准备如下两个表,并插入数据. #分类 CREATE TABLE IF NOT EXISTS `type` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`id`) ); #图书 CREATE TABLE IF NOT EXISTS `book` ( `bookid` INT(10) UNSIGNED NO
-
查看mysql当前连接数的方法详解
1.查看当前所有连接的详细资料: ./mysqladmin -uadmin -p -h10.140.1.1 processlist2.只查看当前连接数(Threads就是连接数.): ./mysqladmin -uadmin -p -h10.140.1.1 status .查看当前所有连接的详细资料: mysqladmin -uroot -proot processlist D:\MySQL\bin>mysqladmin -uroot -proot processlist| Id | User
-
zabbix监控MySQL主从状态的方法详解
搭建MySQL主从后,很多时候不知道从的状态是否ok,有时候出现异常不能及时知道,这里通过shell脚本结合zabbix实现监控并告警 一般情况下,在MySQL的从上查看从的运行状态是通过Slave_IO_Running线程和Slave_SQL_Running线程是否ok,通过命令"show slave status\G;"即可查看.所以这里根据这两个值进行判断. agent端脚本编写及配置 说明:所有zabbix相关的脚本我都放在了/etc/zabbix/script/ 目录里面,下
-
MySQL子查询的使用详解下篇
目录 相关子查询 EXISTS与NOT EXISTS关键字 相关子查询 相关子查询执行流程 如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 .相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询. 说明:子查询中使用主查询中的列 题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id 方式一:相关子查
-
MySQL子查询的使用详解上篇
目录 前言 需求分析与问题解决 子查询的基本使用 子查询的分类 单行子查询 HAVING中的子查询 非法使用子查询 多行子查询 前言 子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQL 4.1开始引入. SQL 中子查询的使用大大增强了 SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据,或者 需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集 合)进行比较. 需求分析与问题解决 #方式一: SELECT salary
-
MySQL binlog 远程备份方法详解
以前备份binlog时,都是先在本地进行备份压缩,然后发送到远程服务器中.但是这其中还是有一定风险的,因为日志的备份都是周期性的,如果在某个周期中,服务器宕机了,硬盘损坏了,就可能导致这段时间的binlog就丢失了. 而且,以前用脚本对远程服务器进行备份的方式,有个缺点:无法对MySQL服务器当前正在写的二进制日志文件进行备份.所以,只能等到MySQL服务器全部写完才能进行备份.而写完一个binlog的时间并不固定,这就导致备份周期的不确定. 从MySQL5.6开始,mysqlbinlog支持将
-
MySQL主从数据库搭建方法详解
本文实例讲述了MySQL主从数据库搭建方法.分享给大家供大家参考,具体如下: 主从服务器是mysql实时数据同步备份的一个非常好的方案了,现在各大中小型网都都会使用mysql数据库主从服务器功能来对网站数据库进行异步备份了,下面我们来给大家介绍主从服务器配置步骤. Mysql的主从复制至少是需要两个Mysql的服务,当然Mysql的服务是可以分布在不同的服务器上,也可以在一台服务器上启动多个服务. (1)首先确保主从服务器上的Mysql版本相同 (2)在主服务器上,设置一个从数据库的账户,使用R