Python加载文件内容的两种实现方式
目录
- 一、利用open()函数进行加载
- 二、利用Pandas库中的read_csv()方法进行加载
- 三、示例
说到机器学习,大家首先想到的可能就是Python和算法了,其实光有Python和算法是不够的,数据才是进行机器学习的前提。
大多数的数据都会存储在文件中,要想通过Python调用算法对数据进行相关学习,首先就要将数据读入程序中,本文介绍两种加载数据的方式,在之后的算法介绍中,将频繁使用这两种方式将数据加载到程序。
下面我们将以Logistic Regression模型加载数据为例,分别对两种不同的加载数据的方式进行介绍。
一、利用open()函数进行加载
def load_file(file_name):
'''
利用open()函数加载文件
:param file_name: 文件名
:return: 特征矩阵、标签矩阵
'''
f = open(file_name) # 打开训练数据集所在的文档
feature = [] # 存放特征的列表
label = [] #存放标签的列表
for row in f.readlines():
f_tmp = [] # 存放特征的中间列表
l_tmp = [] # 存放标签的中间列表
number = row.strip().split("\t") # 按照\t分割每行的元素,得到每行特征和标签
f_tmp.append(1) # 设置偏置项
for i in range(len(number) - 1):
f_tmp.append(float(number[i]))
l_tmp.append(float(number[-1]))
feature.append(f_tmp)
label.append(l_tmp)
f.close() # 关闭文件,很重要的操作
return np.mat(feature), np.mat(label)
二、利用Pandas库中的read_csv()方法进行加载
def load_file_pd(path, file_name):
'''
利用pandas库加载文件
:param path: 文件路径
:param file_name: 文件名称
:return: 特征矩阵、标签矩阵
'''
feature = pd.read_csv(path + file_name, delimiter="\t", header=None, usecols=[0, 1])
feature.columns = ["a", "b"]
feature = feature.reindex(columns=list('cab'), fill_value=1)
label = pd.read_csv(path + file_name, delimiter="\t", header=None, usecols=[2])
return feature.values, label.values
三、示例
我们可以使用上述的两种方法加载部分数据进行测试,数据内容如下:
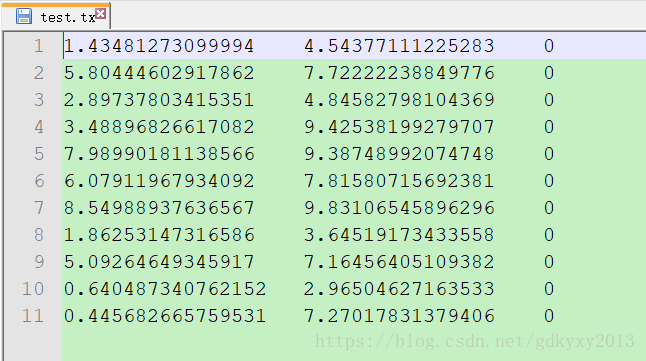
数据分为三列,前两列是特征,最后一列是标签。
加载数据代码如下:
'''
两种方式加载文件
'''
import pandas as pd
import numpy as np
def load_file(file_name):
'''
利用open()函数加载文件
:param file_name: 文件名
:return: 特征矩阵、标签矩阵
'''
f = open(file_name) # 打开训练数据集所在的文档
feature = [] # 存放特征的列表
label = [] #存放标签的列表
for row in f.readlines():
f_tmp = [] # 存放特征的中间列表
l_tmp = [] # 存放标签的中间列表
number = row.strip().split("\t") # 按照\t分割每行的元素,得到每行特征和标签
f_tmp.append(1) # 设置偏置项
for i in range(len(number) - 1):
f_tmp.append(float(number[i]))
l_tmp.append(float(number[-1]))
feature.append(f_tmp)
label.append(l_tmp)
f.close() # 关闭文件,很重要的操作
return np.mat(feature), np.mat(label)
def load_file_pd(path, file_name):
'''
利用pandas库加载文件
:param path: 文件路径
:param file_name: 文件名称
:return: 特征矩阵、标签矩阵
'''
feature = pd.read_csv(path + file_name, delimiter="\t", header=None, usecols=[0, 1])
feature.columns = ["a", "b"]
feature = feature.reindex(columns=list('cab'), fill_value=1)
label = pd.read_csv(path + file_name, delimiter="\t", header=None, usecols=[2])
return feature.values, label.values
if __name__ == "__main__":
path = "C://Users//Machenike//Desktop//xzw//"
feature, label = load_file(path + "test.txt")
feature_pd, label_pd = load_file_pd(path, "test.txt")
print(feature)
print(feature_pd)
print(label)
print(label_pd)
测试结果:
[[ 1. 1.43481273 4.54377111]
[ 1. 5.80444603 7.72222239]
[ 1. 2.89737803 4.84582798]
[ 1. 3.48896827 9.42538199]
[ 1. 7.98990181 9.38748992]
[ 1. 6.07911968 7.81580716]
[ 1. 8.54988938 9.83106546]
[ 1. 1.86253147 3.64519173]
[ 1. 5.09264649 7.16456405]
[ 1. 0.64048734 2.96504627]
[ 1. 0.44568267 7.27017831]]
[[ 1. 1.43481273 4.54377111]
[ 1. 5.80444603 7.72222239]
[ 1. 2.89737803 4.84582798]
[ 1. 3.48896827 9.42538199]
[ 1. 7.98990181 9.38748992]
[ 1. 6.07911968 7.81580716]
[ 1. 8.54988938 9.83106546]
[ 1. 1.86253147 3.64519173]
[ 1. 5.09264649 7.16456405]
[ 1. 0.64048734 2.96504627]
[ 1. 0.44568267 7.27017831]]
[[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]
[ 0.]]
[[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]]
从测试结果来看可知两种加载数据的方法得到的数据结果是一样的,故两种方法均适用于加载数据。
注意:
此处是以Logistic Regression模型加载数据为例,数据与数据本身或许会有差异,但加载数据的方式都是大同小异的,要灵活变通。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python读取文件内容的三种常用方式及效率比较
本文实例讲述了Python读取文件内容的三种常用方式.分享给大家供大家参考,具体如下: 本次实验的文件是一个60M的文件,共计392660行内容. 程序一: def one(): start = time.clock() fo = open(file,'r') fc = fo.readlines() num = 0 for l in fc: tup = l.rstrip('\n').rstrip().split('\t') num = num+1 fo.close() end = time.cl
-
Python实现从文件中加载数据的方法详解
前几篇都是手动录入或随机函数产生的数据.实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化. 比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数据来源.下面,将展示几种方法. 我们将使用内置的 csv 模块加载CSV文件 CSV文件是一种特殊的文本文件,文件中的数据以逗号作为分隔符,很适合进行数据的解析.先用excle建立如下表格和数据,另存为csv格式文件,放到代码目录下. 包含在Python标准库中自带CSV 模块,我们只需要impor
-
python动态加载包的方法小结
本文实例总结了python动态加载包的方法.分享给大家供大家参考,具体如下: 动态加载模块有三种方法 1. 使用系统函数__import_() stringmodule = __import__('string') 2. 使用imp 模块 import imp stringmodule = imp.load_module('string',*imp.find_module('string')) imp.load_source("TYACMgrHandler_"+app.upper(),
-
Python实现加载及解析properties配置文件的方法
本文实例讲述了Python实现加载及解析properties配置文件的方法.分享给大家供大家参考,具体如下: 这里参考前面一篇:http://www.jb51.net/article/137393.htm 我们都是在java里面遇到要解析properties文件,在python中基本没有遇到这中情况,今天用python跑深度学习的时候,发现有些参数可以放在一个global.properties全局文件中,这样使用的时候更加方便.原理都是加载文件,然后用line方法进行解析判断"=",自
-
Python加载文件内容的两种实现方式
目录 一.利用open()函数进行加载 二.利用Pandas库中的read_csv()方法进行加载 三.示例 说到机器学习,大家首先想到的可能就是Python和算法了,其实光有Python和算法是不够的,数据才是进行机器学习的前提. 大多数的数据都会存储在文件中,要想通过Python调用算法对数据进行相关学习,首先就要将数据读入程序中,本文介绍两种加载数据的方式,在之后的算法介绍中,将频繁使用这两种方式将数据加载到程序. 下面我们将以Logistic Regression模型加载数据为例,分别对
-
python 获取剪切板内容的两种方法
第一种 # -*- coding: utf-8 -*- # @Time : 2020/3/16 21:26 # @File : get_text_from_cupboard_13.py # @Author: Hero Liu # python读取剪切板内容 import win32clipboard as w import win32con def get_text(): w.OpenClipboard() d = w.GetClipboardData(win32con.CF_TEXT) w.C
-
webpack 动态批量加载文件的实现方法
背景 最近笔者在工作中遇到了一个小需求: 要实现一个组件来播放帧图片 这个需求本身不复杂,但是需要在组件中一次性引入十张图片,就像下面这样: // 就是这么任性,下标从0开始~ import frame0 from './assets/frame_0.png' import frame1 from './assets/frame_1.png' import frame2 from './assets/frame_2.png' // ..省略n张 import frame7 from './ass
-
JS 动态加载js文件和css文件 同步/异步的两种简单方式
/*动态添加js或css,URL:文件路径,FileType:文件类型(js/css)*/ function AddJsFiles(URL,FileType){ var oHead = document.getElementsByTagName('HEAD').item(0); var addheadfile; if(FileType=="js"){ addheadfile= document.createElement("script"); addheadfile
-
Vue import from省略后缀/加载文件夹的方法/实例详解
目录 简介 省略后缀 说明 官网网址 详解 文件名相同的处理流程 加载文件夹 简介 说明 详解 实例 1. 路由配置中导入layout文件夹 2.layout/index.vue引入目录 3.components/index.js引入各个组件 简介 本文介绍Vue在import时省略后缀以及import文件夹的方法. 省略后缀 说明 可以配置省略后缀,比如:test.js,只用test即可. 官网网址 解析(Resolve) | webpack 中文文档 详解 配置文件:webpack.base
-
未能加载文件或程序集“AspNetPager”或它的某一个依赖项。拒绝访问
未能加载文件或程序集"AspNetPager"或它的某一个依赖项.系统找不到指定的路径. 说明: 执行当前 Web 请求期间,出现未经处理的异常.请检查堆栈跟踪信息,以了解有关该错误以及代码中导致错误的出处的详细信息. 异常详细信息: System.IO.FileNotFoundException: 未能加载文件或程序集"AspNetPager"或它的某一个依赖项.系统找不到指定的路径. 源错误: 执行当前 Web 请求期间生成了未经处理的异常.可以使用下面的异常堆
-
Zend Framework使用Zend_Loader组件动态加载文件和类用法详解
本文实例讲述了Zend Framework使用Zend_Loader组件动态加载文件和类的方法.分享给大家供大家参考,具体如下: 加载文件 Zend_Loader组件可以实现对文件的加载功能,还可以判断文件是否可读. 这两个功能分别由Zend_loader::loadFile()方法与Zend_loader::isReadable()方法来实现. 动态加载是可以将变量所指代的文件进行加载的过程.当需要加载的文件为用户输入或是某个方法的参数时,通过传统的加载方法会很难对文件进行加载. 通过动态加载
-
Python字符串格式化的方法(两种)
本文介绍了Python字符串格式化,主要有两种方法,分享给大家,具体如下 用于字符串的拼接,性能更优. 字符串格式化有两种方式:百分号方式.format方式. 百分号方式比较老,而format方式是比较先进的,企图替代古老的方式,目前两者共存. 1.百分号方式 格式:%[(name)][flags][width].[precision]typecode (name) 可选,用于选择指定的key flags 可选,可供选择的值有: + 右对齐:正数的加正号,负数的加负号 - 左
-
Jupyter加载文件的实现方法
初学初用,随手记录以当作笔记使用,会慢慢再进行补充添加,错误之处烦请指正. (1)运行本地文件,在代码不加载的情况下可以直接显示结果 % run F:\pythonCode\range.py(路径不加引号) (2)将本地文件加载到jupyter %load F:\pythonCode\range.py(路径是文件在本地的保存位置) 加载完成后"%load F:\pythonCode\range.py"会变成注释,而文件内容会显示在cell中. 若是从网络中导入python代码,可以使用
-
使用Python将图片转正方形的两种方法实例代码详解
一.将原图粘贴到一张正方形的背景上 def trans_square(image): r"""Open the image using PIL.""" image = image.convert('RGB') w, h = image.size background = Image.new('RGB', size=(max(w, h), max(w, h)), color=(127, 127, 127)) # 创建背景图,颜色值为127 leng