详解Java实现缓存(LRU,FIFO)
现在软件或者网页的并发量越来越大了,大量请求直接操作数据库会对数据库造成很大的压力,处理大量连接和请求就会需要很长时间,但是实际中百分之80的数据是很少更改的,这样就可以引入缓存来进行读取,减少数据库的压力。
常用的缓存有Redis和memcached,但是有时候一些小场景就可以直接使用Java实现缓存,就可以满足这部分服务的需求。
缓存主要有LRU和FIFO,LRU是Least Recently Used的缩写,即最近最久未使用,FIFO就是先进先出,下面就使用Java来实现这两种缓存。
LRU
LRU缓存的思想
- 固定缓存大小,需要给缓存分配一个固定的大小。
- 每次读取缓存都会改变缓存的使用时间,将缓存的存在时间重新刷新。
- 需要在缓存满了后,将最近最久未使用的缓存删除,再添加最新的缓存。
按照如上思想,可以使用LinkedHashMap来实现LRU缓存。
这是LinkedHashMap的一个构造函数,传入的第三个参数accessOrder为true的时候,就按访问顺序对LinkedHashMap排序,为false的时候就按插入顺序,默认是为false的。
当把accessOrder设置为true后,就可以将最近访问的元素置于最前面,这样就可以满足上述的第二点。
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
这是LinkedHashMap中另外一个方法,当返回true的时候,就会remove其中最久的元素,可以通过重写这个方法来控制缓存元素的删除,当缓存满了后,就可以通过返回true删除最久未被使用的元素,达到LRU的要求。这样就可以满足上述第三点要求。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
由于LinkedHashMap是为自动扩容的,当table数组中元素大于Capacity * loadFactor的时候,就会自动进行两倍扩容。但是为了使缓存大小固定,就需要在初始化的时候传入容量大小和负载因子。
为了使得到达设置缓存大小不会进行自动扩容,需要将初始化的大小进行计算再传入,可以将初始化大小设置为(缓存大小 / loadFactor) + 1,这样就可以在元素数目达到缓存大小时,也不会进行扩容了。这样就解决了上述第一点问题。
通过上面分析,实现下面的代码
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class LRU1<K, V> {
private final int MAX_CACHE_SIZE;
private final float DEFAULT_LOAD_FACTORY = 0.75f;
LinkedHashMap<K, V> map;
public LRU1(int cacheSize) {
MAX_CACHE_SIZE = cacheSize;
int capacity = (int)Math.ceil(MAX_CACHE_SIZE / DEFAULT_LOAD_FACTORY) + 1;
/*
* 第三个参数设置为true,代表linkedlist按访问顺序排序,可作为LRU缓存
* 第三个参数设置为false,代表按插入顺序排序,可作为FIFO缓存
*/
map = new LinkedHashMap<K, V>(capacity, DEFAULT_LOAD_FACTORY, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > MAX_CACHE_SIZE;
}
};
}
public synchronized void put(K key, V value) {
map.put(key, value);
}
public synchronized V get(K key) {
return map.get(key);
}
public synchronized void remove(K key) {
map.remove(key);
}
public synchronized Set<Map.Entry<K, V>> getAll() {
return map.entrySet();
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
for (Map.Entry<K, V> entry : map.entrySet()) {
stringBuilder.append(String.format("%s: %s ", entry.getKey(), entry.getValue()));
}
return stringBuilder.toString();
}
public static void main(String[] args) {
LRU1<Integer, Integer> lru1 = new LRU1<>(5);
lru1.put(1, 1);
lru1.put(2, 2);
lru1.put(3, 3);
System.out.println(lru1);
lru1.get(1);
System.out.println(lru1);
lru1.put(4, 4);
lru1.put(5, 5);
lru1.put(6, 6);
System.out.println(lru1);
}
}
运行结果:
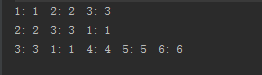
从运行结果中可以看出,实现了LRU缓存的思想。
接着使用HashMap和链表来实现LRU缓存。
主要的思想和上述基本一致,每次添加元素或者读取元素就将元素放置在链表的头,当缓存满了之后,就可以将尾结点元素删除,这样就实现了LRU缓存。
这种方法中是通过自己编写代码移动结点和删除结点,为了防止缓存大小超过限制,每次进行put的时候都会进行检查,若缓存满了则删除尾部元素。
import java.util.HashMap;
/**
* 使用cache和链表实现缓存
*/
public class LRU2<K, V> {
private final int MAX_CACHE_SIZE;
private Entry<K, V> head;
private Entry<K, V> tail;
private HashMap<K, Entry<K, V>> cache;
public LRU2(int cacheSize) {
MAX_CACHE_SIZE = cacheSize;
cache = new HashMap<>();
}
public void put(K key, V value) {
Entry<K, V> entry = getEntry(key);
if (entry == null) {
if (cache.size() >= MAX_CACHE_SIZE) {
cache.remove(tail.key);
removeTail();
}
}
entry = new Entry<>();
entry.key = key;
entry.value = value;
moveToHead(entry);
cache.put(key, entry);
}
public V get(K key) {
Entry<K, V> entry = getEntry(key);
if (entry == null) {
return null;
}
moveToHead(entry);
return entry.value;
}
public void remove(K key) {
Entry<K, V> entry = getEntry(key);
if (entry != null) {
if (entry == head) {
Entry<K, V> next = head.next;
head.next = null;
head = next;
head.pre = null;
} else if (entry == tail) {
Entry<K, V> prev = tail.pre;
tail.pre = null;
tail = prev;
tail.next = null;
} else {
entry.pre.next = entry.next;
entry.next.pre = entry.pre;
}
cache.remove(key);
}
}
private void removeTail() {
if (tail != null) {
Entry<K, V> prev = tail.pre;
if (prev == null) {
head = null;
tail = null;
} else {
tail.pre = null;
tail = prev;
tail.next = null;
}
}
}
private void moveToHead(Entry<K, V> entry) {
if (entry == head) {
return;
}
if (entry.pre != null) {
entry.pre.next = entry.next;
}
if (entry.next != null) {
entry.next.pre = entry.pre;
}
if (entry == tail) {
Entry<K, V> prev = entry.pre;
if (prev != null) {
tail.pre = null;
tail = prev;
tail.next = null;
}
}
if (head == null || tail == null) {
head = tail = entry;
return;
}
entry.next = head;
head.pre = entry;
entry.pre = null;
head = entry;
}
private Entry<K, V> getEntry(K key) {
return cache.get(key);
}
private static class Entry<K, V> {
Entry<K, V> pre;
Entry<K, V> next;
K key;
V value;
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
Entry<K, V> entry = head;
while (entry != null) {
stringBuilder.append(String.format("%s:%s ", entry.key, entry.value));
entry = entry.next;
}
return stringBuilder.toString();
}
public static void main(String[] args) {
LRU2<Integer, Integer> lru2 = new LRU2<>(5);
lru2.put(1, 1);
System.out.println(lru2);
lru2.put(2, 2);
System.out.println(lru2);
lru2.put(3, 3);
System.out.println(lru2);
lru2.get(1);
System.out.println(lru2);
lru2.put(4, 4);
lru2.put(5, 5);
lru2.put(6, 6);
System.out.println(lru2);
}
}
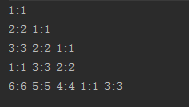
运行结果:
FIFO
FIFO就是先进先出,可以使用LinkedHashMap进行实现。
当第三个参数传入为false或者是默认的时候,就可以实现按插入顺序排序,就可以实现FIFO缓存了。
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
实现代码跟上述使用LinkedHashMap实现LRU的代码基本一致,主要就是构造函数的传值有些不同。
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class LRU1<K, V> {
private final int MAX_CACHE_SIZE;
private final float DEFAULT_LOAD_FACTORY = 0.75f;
LinkedHashMap<K, V> map;
public LRU1(int cacheSize) {
MAX_CACHE_SIZE = cacheSize;
int capacity = (int)Math.ceil(MAX_CACHE_SIZE / DEFAULT_LOAD_FACTORY) + 1;
/*
* 第三个参数设置为true,代表linkedlist按访问顺序排序,可作为LRU缓存
* 第三个参数设置为false,代表按插入顺序排序,可作为FIFO缓存
*/
map = new LinkedHashMap<K, V>(capacity, DEFAULT_LOAD_FACTORY, false) {
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > MAX_CACHE_SIZE;
}
};
}
public synchronized void put(K key, V value) {
map.put(key, value);
}
public synchronized V get(K key) {
return map.get(key);
}
public synchronized void remove(K key) {
map.remove(key);
}
public synchronized Set<Map.Entry<K, V>> getAll() {
return map.entrySet();
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
for (Map.Entry<K, V> entry : map.entrySet()) {
stringBuilder.append(String.format("%s: %s ", entry.getKey(), entry.getValue()));
}
return stringBuilder.toString();
}
public static void main(String[] args) {
LRU1<Integer, Integer> lru1 = new LRU1<>(5);
lru1.put(1, 1);
lru1.put(2, 2);
lru1.put(3, 3);
System.out.println(lru1);
lru1.get(1);
System.out.println(lru1);
lru1.put(4, 4);
lru1.put(5, 5);
lru1.put(6, 6);
System.out.println(lru1);
}
}
运行结果:

以上就是使用Java实现这两种缓存的方式,从中可以看出,LinkedHashMap实现缓存较为容易,因为底层函数对此已经有了支持,自己编写链表实现LRU缓存也是借鉴了LinkedHashMap中实现的思想。在Java中不只是这两种数据结构可以实现缓存,比如ConcurrentHashMap、WeakHashMap在某些场景下也是可以作为缓存的,到底用哪一种数据结构主要是看场景再进行选择,但是很多思想都是可以通用的。
相关推荐
-
java开发之MD5加密算法的实现
先看看代码再说: 复制代码 代码如下: package com.b510.note; import java.math.BigInteger; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; /** * MD5加密 * * @author Hongten * */ public class MD5 { public static void main(String[]
-
java字符串相似度算法
本文实例讲述了java字符串相似度算法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: public class Levenshtein { private int compare(String str, String target) { int d[][]; // 矩阵 int n = str.length(); int m = target.length(); int i; // 遍历str的
-

图解程序员必须掌握的Java常用8大排序算法
这篇文章主要介绍了Java如何实现八个常用的排序算法:插入排序.冒泡排序.选择排序.希尔排序 .快速排序.归并排序.堆排序和LST基数排序,分享给大家一起学习. 分类 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排序(直接选择排序.堆排序) 4)归并排序 5)分配排序(基数排序) 所需辅助空间最多:归并排序 所需辅助空间最少:堆排序 平均速度最快:快速排序 不稳定:快速排序,希尔排序,堆排序. 先来看看8种排序之间的关系: 1.直接插入排序 (1)基本思想
-
JAVA实现caesar凯撒加密算法
复制代码 代码如下: public class Caesar { public static final String SOURCE = "abcdefghijklmnopqrstuvwxyz"; public static final int LEN = SOURCE.length(); /** * @param args */ public static void main(String[] args) { String result = caesarEncryptio
-
Java实现LRU缓存的实例详解
Java实现LRU缓存的实例详解 1.Cache Cache对于代码系统的加速与优化具有极大的作用,对于码农来说是一个很熟悉的概念.可以说,你在内存中new 了一个一段空间(比方说数组,list)存放一些冗余的结果数据,并利用这些数据完成了以空间换时间的优化目的,你就已经使用了cache. 有服务级的缓存框架,如memcache,Redis等.其实,很多时候,我们在自己同一个服务内,或者单个进程内也需要缓存,例如,lucene就对搜索做了缓存,而无须依赖外界.那么,我们如何实现我们自己的缓存?还
-
关于JAVA经典算法40题(超实用版)
[程序1]题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第四个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少?1.程序分析: 兔子的规律为数列1,1,2,3,5,8,13,21....public class exp2{ public static void main(String args[]){ int i=0; for(i=1;i<=20;i++)System.out.println(f(i));}public static int f(in
-
分享Java常用几种加密算法(四种)
对称加密算法是应用较早的加密算法,技术成熟.在对称加密算法中,数据发信方将明文(原始数据)和加密密钥(mi yue)一起经过特殊加密算法处理后,使其变成复杂的加密密文发送出去.收信方收到密文后,若想解读原文,则需要使用加密用过的密钥及相同算法的逆算法对密文进行解密,才能使其恢复成可读明文.在对称加密算法中,使用的密钥只有一个,发收信双方都使用这个密钥对数据进行加密和解密,这就要求解密方事先必须知道加密密钥. 简单的java加密算法有: BASE 严格地说,属于编码格式,而非加密算法 MD(Mes
-
java LRU(Least Recently Used )详解及实例代码
java LRU(Least Recently Used )详解 LRU是Least Recently Used 的缩写,翻译过来就是"最近最少使用",LRU缓存就是使用这种原理实现,简单的说就是缓存一定量的数据,当超过设定的阈值时就把一些过期的数据删除掉,比如我们缓存10000条数据,当数据小于10000时可以随意添加,当超过10000时就需要把新的数据添加进来,同时要把过期数据删除,以确保我们最大缓存10000条,那怎么确定删除哪条过期数据呢,采用LRU算法实现的话就是将最老的数据
-
Java和Android的LRU缓存及实现原理
一.概述 Android提供了LRUCache类,可以方便的使用它来实现LRU算法的缓存.Java提供了LinkedHashMap,可以用该类很方便的实现LRU算法,Java的LRULinkedHashMap就是直接继承了LinkedHashMap,进行了极少的改动后就可以实现LRU算法. 二.Java的LRU算法 Java的LRU算法的基础是LinkedHashMap,LinkedHashMap继承了HashMap,并且在HashMap的基础上进行了一定的改动,以实现LRU算法. 1.Hash
-
java 合并排序算法、冒泡排序算法、选择排序算法、插入排序算法、快速排序算法的描述
算法是在有限步骤内求解某一问题所使用的一组定义明确的规则.通俗点说,就是计算机解题的过程.在这个过程中,无论是形成解题思路还是编写程序,都是在实施某种算法.前者是推理实现的算法,后者是操作实现的算法. 一个算法应该具有以下五个重要的特征: 1.有穷性: 一个算法必须保证执行有限步之后结束: 2.确切性: 算法的每一步骤必须有确切的定义: 3.输入:一个算法有0个或多个输入,以刻画运算对象的初始情况: 4.输出:一个算法有一个或多个输出,以反映对输入数据加工后的结果.没有输出的算法是毫无意义的:
-
java异或加密算法
简单异或密码(simple XOR cipher)是密码学中中一种简单的加密算法. 异或运算:m^n^n = m; 利用异或运算的特点,可以对数据进行简单的加密和解密. 复制代码 代码如下: /** * 简单异或加密解密算法 * @param str 要加密的字符串 * @return */private static String encode2(String str) { int code = 112; // 密钥 char[] charArray = str.toCharArray();
-
java LRU算法介绍与用法示例
本文实例讲述了java LRU算法介绍与用法.分享给大家供大家参考,具体如下: 1.前言 在用户使用联网的软件的时候,总会从网络上获取数据,当在一段时间内要多次使用同一个数据的时候,用户不可能每次用的时候都去联网进行请求,既浪费时间又浪费网络 这时就可以将用户请求过的数据进行保存,但不是任意数据都进行保存,这样会造成内存浪费的.LRU算法的思想就可以运用了. 2.LRU简介 LRU是Least Recently Used 近期最少使用算法,它就可以将长时间没有被利用的数据进行删除. LRU在人们