机器学习python实战之决策树
决策树原理:从数据集中找出决定性的特征对数据集进行迭代划分,直到某个分支下的数据都属于同一类型,或者已经遍历了所有划分数据集的特征,停止决策树算法。
每次划分数据集的特征都有很多,那么我们怎么来选择到底根据哪一个特征划分数据集呢?这里我们需要引入信息增益和信息熵的概念。
一、信息增益
划分数据集的原则是:将无序的数据变的有序。在划分数据集之前之后信息发生的变化称为信息增益。知道如何计算信息增益,我们就可以计算根据每个特征划分数据集获得的信息增益,选择信息增益最高的特征就是最好的选择。首先我们先来明确一下信息的定义:符号xi的信息定义为 l(xi)=-log2 p(xi),p(xi)为选择该类的概率。那么信息源的熵H=-∑p(xi)·log2 p(xi)。根据这个公式我们下面编写代码计算香农熵
def calcShannonEnt(dataSet):
NumEntries = len(dataSet)
labelsCount = {}
for i in dataSet:
currentlabel = i[-1]
if currentlabel not in labelsCount.keys():
labelsCount[currentlabel]=0
labelsCount[currentlabel]+=1
ShannonEnt = 0.0
for key in labelsCount:
prob = labelsCount[key]/NumEntries
ShannonEnt -= prob*log(prob,2)
return ShannonEnt
上面的自定义函数我们需要在之前导入log方法,from math import log。 我们可以先用一个简单的例子来测试一下
def createdataSet(): #dataSet = [['1','1','yes'],['1','0','no'],['0','1','no'],['0','0','no']] dataSet = [[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,0,'no']] labels = ['no surfacing','flippers'] return dataSet,labels

这里的熵为0.811,当我们增加数据的类别时,熵会增加。这里更改后的数据集的类别有三种‘yes'、‘no'、‘maybe',也就是说数据越混乱,熵就越大。
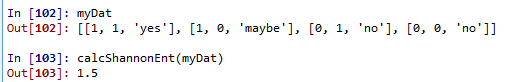
分类算法出了需要计算信息熵,还需要划分数据集。决策树算法中我们对根据每个特征划分的数据集计算一次熵,然后判断按照哪个特征划分是最好的划分方式。
def splitDataSet(dataSet,axis,value): retDataSet = [] for featVec in dataSet: if featVec[axis] == value: reducedfeatVec = featVec[:axis] reducedfeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedfeatVec) return retDataSet
axis表示划分数据集的特征,value表示特征的返回值。这里需要注意extend方法和append方法的区别。举例来说明这个区别
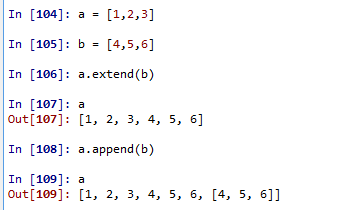
下面我们测试一下划分数据集函数的结果:

axis=0,value=1,按myDat数据集的第0个特征向量是否等于1进行划分。
接下来我们将遍历整个数据集,对每个划分的数据集计算香农熵,找到最好的特征划分方式
def choosebestfeatureToSplit(dataSet): Numfeatures = len(dataSet)-1 BaseShannonEnt = calcShannonEnt(dataSet) bestInfoGain=0.0 bestfeature = -1 for i in range(Numfeatures): featlist = [example[i] for example in dataSet] featSet = set(featlist) newEntropy = 0.0 for value in featSet: subDataSet = splitDataSet(dataSet,i,value) prob = len(subDataSet)/len(dataSet) newEntropy += prob*calcShannonEnt(subDataSet) infoGain = BaseShannonEnt-newEntropy if infoGain>bestInfoGain: bestInfoGain=infoGain bestfeature = i return bestfeature
信息增益是熵的减少或数据无序度的减少。最后比较所有特征中的信息增益,返回最好特征划分的索引。函数测试结果为

接下来开始递归构建决策树,我们需要在构建前计算列的数目,查看算法是否使用了所有的属性。这个函数跟跟第二章的calssify0采用同样的方法
def majorityCnt(classlist):
ClassCount = {}
for vote in classlist:
if vote not in ClassCount.keys():
ClassCount[vote]=0
ClassCount[vote]+=1
sortedClassCount = sorted(ClassCount.items(),key = operator.itemgetter(1),reverse = True)
return sortedClassCount[0][0]
def createTrees(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestfeature = choosebestfeatureToSplit(dataSet)
bestfeatureLabel = labels[bestfeature]
myTree = {bestfeatureLabel:{}}
del(labels[bestfeature])
featValue = [example[bestfeature] for example in dataSet]
uniqueValue = set(featValue)
for value in uniqueValue:
subLabels = labels[:]
myTree[bestfeatureLabel][value] = createTrees(splitDataSet(dataSet,bestfeature,value),subLabels)
return myTree
最终决策树得到的结果如下:

有了如上的结果,我们看起来并不直观,所以我们接下来用matplotlib注解绘制树形图。matplotlib提供了一个注解工具annotations,它可以在数据图形上添加文本注释。我们先来测试一下这个注解工具的使用。
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle = 'sawtooth',fc = '0.8')
leafNode = dict(boxstyle = 'sawtooth',fc = '0.8')
arrow_args = dict(arrowstyle = '<-')
def plotNode(nodeTxt,centerPt,parentPt,nodeType):
createPlot.ax1.annotate(nodeTxt,xy = parentPt,xycoords = 'axes fraction',\
xytext = centerPt,textcoords = 'axes fraction',\
va = 'center',ha = 'center',bbox = nodeType,\
arrowprops = arrow_args)
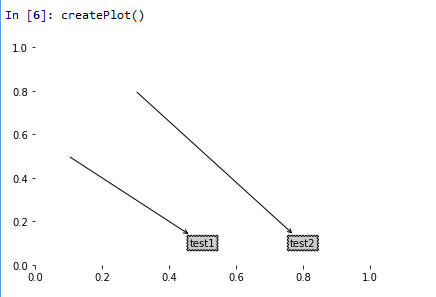
def createPlot():
fig = plt.figure(1,facecolor = 'white')
fig.clf()
createPlot.ax1 = plt.subplot(111,frameon = False)
plotNode('test1',(0.5,0.1),(0.1,0.5),decisionNode)
plotNode('test2',(0.8,0.1),(0.3,0.8),leafNode)
plt.show()
测试过这个小例子之后我们就要开始构建注解树了。虽然有xy坐标,但在如何放置树节点的时候我们会遇到一些麻烦。所以我们需要知道有多少个叶节点,树的深度有多少层。下面的两个函数就是为了得到叶节点数目和树的深度,两个函数有相同的结构,从第一个关键字开始遍历所有的子节点,使用type()函数判断子节点是否为字典类型,若为字典类型,则可以认为该子节点是一个判断节点,然后递归调用函数getNumleafs(),使得函数遍历整棵树,并返回叶子节点数。第2个函数getTreeDepth()计算遍历过程中遇到判断节点的个数。该函数的终止条件是叶子节点,一旦到达叶子节点,则从递归调用中返回,并将计算树深度的变量加一
def getNumleafs(myTree): numLeafs=0 key_sorted= sorted(myTree.keys()) firstStr = key_sorted[0] secondDict = myTree[firstStr] for key in secondDict.keys(): if type(secondDict[key]).__name__=='dict': numLeafs+=getNumleafs(secondDict[key]) else: numLeafs+=1 return numLeafs def getTreeDepth(myTree): maxdepth=0 key_sorted= sorted(myTree.keys()) firstStr = key_sorted[0] secondDict = myTree[firstStr] for key in secondDict.keys(): if type(secondDict[key]).__name__ == 'dict': thedepth=1+getTreeDepth(secondDict[key]) else: thedepth=1 if thedepth>maxdepth: maxdepth=thedepth return maxdepth
测试结果如下
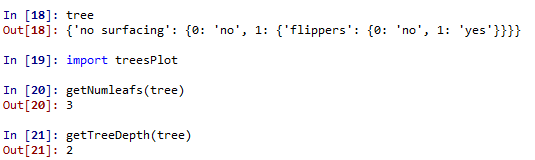
我们先给出最终的决策树图来验证上述结果的正确性
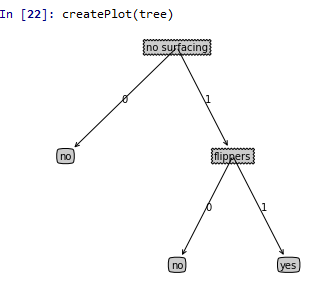
可以看出树的深度确实是有两层,叶节点的数目是3。接下来我们给出绘制决策树图的关键函数,结果就得到上图中决策树。
def plotMidText(cntrPt,parentPt,txtString): xMid = (parentPt[0]-cntrPt[0])/2.0+cntrPt[0] yMid = (parentPt[1]-cntrPt[1])/2.0+cntrPt[1] createPlot.ax1.text(xMid,yMid,txtString) def plotTree(myTree,parentPt,nodeTxt): numLeafs = getNumleafs(myTree) depth = getTreeDepth(myTree) key_sorted= sorted(myTree.keys()) firstStr = key_sorted[0] cntrPt = (plotTree.xOff+(1.0+float(numLeafs))/2.0/plotTree.totalW,plotTree.yOff) plotMidText(cntrPt,parentPt,nodeTxt) plotNode(firstStr,cntrPt,parentPt,decisionNode) secondDict = myTree[firstStr] plotTree.yOff -= 1.0/plotTree.totalD for key in secondDict.keys(): if type(secondDict[key]).__name__ == 'dict': plotTree(secondDict[key],cntrPt,str(key)) else: plotTree.xOff+=1.0/plotTree.totalW plotNode(secondDict[key],(plotTree.xOff,plotTree.yOff),cntrPt,leafNode) plotMidText((plotTree.xOff,plotTree.yOff),cntrPt,str(key)) plotTree.yOff+=1.0/plotTree.totalD def createPlot(inTree): fig = plt.figure(1,facecolor = 'white') fig.clf() axprops = dict(xticks = [],yticks = []) createPlot.ax1 = plt.subplot(111,frameon = False,**axprops) plotTree.totalW = float(getNumleafs(inTree)) plotTree.totalD = float(getTreeDepth(inTree)) plotTree.xOff = -0.5/ plotTree.totalW; plotTree.yOff = 1.0 plotTree(inTree,(0.5,1.0),'') plt.show()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
决策树的python实现方法
本文实例讲述了决策树的python实现方法.分享给大家供大家参考.具体实现方法如下: 决策树算法优缺点: 优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关的特征数据 缺点:可能会产生过度匹配的问题 适用数据类型:数值型和标称型 算法思想: 1.决策树构造的整体思想: 决策树说白了就好像是if-else结构一样,它的结果就是你要生成这个一个可以从根开始不断判断选择到叶子节点的树,但是呢这里的if-else必然不会是让我们认为去设置的,我们要做的是提供一种方法,计算机可以根
-
基于ID3决策树算法的实现(Python版)
实例如下: # -*- coding:utf-8 -*- from numpy import * import numpy as np import pandas as pd from math import log import operator #计算数据集的香农熵 def calcShannonEnt(dataSet): numEntries=len(dataSet) labelCounts={} #给所有可能分类创建字典 for featVec in dataSet: currentLa
-
机器学习python实战之决策树
决策树原理:从数据集中找出决定性的特征对数据集进行迭代划分,直到某个分支下的数据都属于同一类型,或者已经遍历了所有划分数据集的特征,停止决策树算法. 每次划分数据集的特征都有很多,那么我们怎么来选择到底根据哪一个特征划分数据集呢?这里我们需要引入信息增益和信息熵的概念. 一.信息增益 划分数据集的原则是:将无序的数据变的有序.在划分数据集之前之后信息发生的变化称为信息增益.知道如何计算信息增益,我们就可以计算根据每个特征划分数据集获得的信息增益,选择信息增益最高的特征就是最好的选择.首先我们先来
-
机器学习python实战之手写数字识别
看了上一篇内容之后,相信对K近邻算法有了一个清晰的认识,今天的内容--手写数字识别是对上一篇内容的延续,这里也是为了自己能更熟练的掌握k-NN算法. 我们有大约2000个训练样本和1000个左右测试样本,训练样本所在的文件夹是trainingDigits,测试样本所在的文件夹是testDigits.文本文件中是0~9的数字,但是是用二值图表示出来的,如图.我们要做的就是使用训练样本训练模型,并用测试样本来检测模型的性能. 首先,我们需要将文本文件中的内容转化为向量,因为图片大小是32*32,所以
-
python机器学习Sklearn实战adaboost算法示例详解
目录 pandas批量处理体测成绩 adaboost adaboost原理案例举例 弱分类器合并成强分类器 pandas批量处理体测成绩 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt data = pd.read_excel("/Users/zhucan/Desktop/18级高一体测成绩汇总.xls") cond =
-
Python实战之MNIST手写数字识别详解
目录 数据集介绍 1.数据预处理 2.网络搭建 3.网络配置 关于优化器 关于损失函数 关于指标 4.网络训练与测试 5.绘制loss和accuracy随着epochs的变化图 6.完整代码 数据集介绍 MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片,且内置于keras.本文采用Tensorflow下Keras(Keras中文文档)神经网络API进行网络搭建. 开始之前,先回忆下机器学习
-
Python实战小程序利用matplotlib模块画图代码分享
Python中的数据可视化 matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地进行制图.而且也可以方便地将它作为绘图控件. 实战小程序:画出y=x^3的散点图 样例代码如下: #coding=utf-8 import pylab as y #引入pylab模块 x = y.np.linspace(-10, 10, 100) #设置x横坐标范围和点数 y.plot(x, x*x*x,'or') #生成图像 ax = y.gca() a
-
python实战之实现excel读取、统计、写入的示例讲解
背景 图像领域内的一个国内会议快要召开了,要发各种邀请邮件,之后要录入.统计邮件回复(参会还是不参会等).如此重要的任务,老师就托付给我了.ps: 统计回复邮件的时候,能知道谁参会或谁不参会. 而我主要的任务,除了录入邮件回复,就是统计理事和普通会员的参会情况了(参会的.不参会的.没回复的).录入邮件回复信息没办法只能人工操作,但如果统计也要人工的话,那工作量就太大了(比如在上百人的列表中搜索另外上百人在不在此列表中!!),于是就想到了用python来帮忙,花两天时间不断修改,写了6个版本...
-
python实战串口助手_解决8串口多个发送的问题
今晚终于解决了串口发送的问题,更改代码如下: def write(self, data): if self.alive: if self.serSer.isOpen(): self.serSer.write(data) def m_send1butOnButtonClick( self, event ): if self.ser.alive: send_data = '' send_data += str(self.m_textCtrl5.GetValue()) self.ser.write(s
-
Python实战整活之聊天机器人
一.前言 刚刚学了一些python文件读写的内容,先跑过来整活了.顺便复习一下之前学的东西. import time doc_local='D:\learning_folder\interaction.txt' def iRead(): fr = open(doc_local, 'r') message=fr.read() return message def iWrite(message): fw = open(doc_local, 'w') fw.write(message) fw.clos
-
Python实战之实现简单的名片管理系统
一.前言 实现名片管理系统,首先要创建两个python file ,分别是cards_main.py和cards_tool.py,前一个是主代码块的实现,后一个是提供主代码块所调用的函数 二.主代码块的实现 import cards_tool as ct #导入cards_tool文件,简称ct,以便调用其中的函数 while True: ct.show_menu() num=int(input("请选择操作功能:")) print(f"您选择的操作是[{num}]"
-
Python实战之实现康威生命游戏
前言 康威生命游戏设计并不难,我的思路就是借助pygame进行外观的展示,最近一段时间的游戏项目都是使用pygame进行的,做起来比较顺利.内部代码的实现也比较简单根据他的规则我们需要的是多次的计算和判断,再刷新数组. 一.康威生命游戏规则 当周围仅有1个或没有存活细胞时, 原来的存活细胞进入死亡状态.(模拟生命数量稀少)当周围有2个或3个存活细胞时, 网格保持原样.当周围有4个及以上存活细胞时,原来的存活细胞亦进入死亡状态.(模拟生命数量过多)当周围有3个存活细胞时,空白网格变成存活细胞.(模