python中正则表达式的使用详解
从学习Python至今,发现很多时候是将Python作为一种工具。特别在文本处理方面,使用起来更是游刃有余。
说到文本处理,那么正则表达式必然是一个绝好的工具,它能将一些繁杂的字符搜索或者替换以非常简洁的方式完成。
我们在处理文本的时候,或是查询抓取,或是替换.
一.查找
如果你想自己实现这样的功能模块,输入某一个ip地址,得到这个ip地址所在地区的详细信息.
然后你发现http://ip138.com 可以查出很详细的数据
但是人家没有提供api供外部调用,但是我们可以通过代码模拟查询然后对结果进行抓取.
通过查看这个相应页面的源码,我们可以发现,结果是放在三个<li></li>中的
<table width="80%" border="0" align="center" cellpadding="0" cellspacing="0">
<tr>
<td align="center"><h3>ip138.com IP查询(搜索IP地址的地理位置)</h3></td>
</tr>
<tr>
<td align="center"><h1>您查询的IP:121.0.29.231</h1></td>
</tr>
<tr>
<td align="center"><ul class="ul1"><li>本站主数据:浙江省杭州市 阿里巴巴</li><li>参考数据一:浙江省杭州市 阿里巴巴</li><li>参考数据二:浙江省杭州市 阿里巴巴</li></ul></td>
</tr>
<tr>
<td align="center">如果您发现查询结果不详细或不正确,请使用<a href="ip_add.asp?ip=121.0.29.231"><font color="#006600"><b>IP数据库自助添加</b></font></a>功能进行修正<br/><br/>
<iframe src="/jss/bd_460x60.htm" frameborder="no" width="460" height="60" border="0" marginwidth="0" marginheight="0" scrolling="no"></iframe><br/><br/></td>
</tr>
<form method="get" action="ips8.asp" name="ipform" onsubmit="return checkIP();">
<tr>
<td align="center">IP地址或者域名:<input type="text" name="ip" size="16"> <input type="submit" value="查询"><input type="hidden" name="action" value="2"></td>
</tr><br>
<br>
</form>
</table>
如果你了解正则表达式你可能会写出
正则表达式
(?<=<li>).*?(?=</li>)
这里使用了前瞻:lookahead 后顾: lookbehind,这样的好处就是匹配的结果中就不会包含html的li标签了.
如果你对自己写的正则表达式不是很自信的话,可以在一些在线或者本地的正则测试工具进行一些测试,以确保正确.
接下来的工作就是如果用Python实现这样的功能,首先我们得将正则表达式表示出来:
r"(?<=<li>).*?(?=</li>)"
Python中字符串前面加上前导r这个字符,代表这个字符串是R aw String(原始字符串),也就是说Python字符串本身不会对字符串中的字符进行转义.这是因为正则表达式也有转义字符之说,如果双重转义的话,易读性很差.
这样的串在Python中我们把它叫做"regular expression pattern"
如果我们对pattern进行编译的话
prog = re.compile(r"(?<=<li>).*?(?=</li>)")
我们便可以得到一个正则表达式对象regular expression object,通过这个对象我们可以进行相关操作.
比如
result=prog.match(string)
##这个等同于
result=re.match(r"(?<=<li>).*?(?=</li>)",string)
##但是如果这个正则需要在程序匹配多次,那么通过正则表达式对象的方式效率会更高
接下来就是查找了,假设我们的html结果已经以html的格式存放在text中,那么通过
result_list = re.findall(r"(?<=<li>).*?(?=</li>)",text)
便可以取得所需的结果列表.
二.替换
使用正则表达式进行替换非常的灵活.
比如之前我在阅读Trac这个系统中wiki模块的源代码的时候,就发现其wiki语法的实现就是通过正则替换进行的.
在使用替换的时候会涉及到正则表达式中的Group分组的概念.
假设wiki语法中使用!表示转义字符即感叹号后面的功能性字符会原样输出,粗体的语法为
写道
'''这里显示为粗体'''
那么有正则表达式为
r"(?P<bold>!?''')"
这里的?P<bold>是Python正则语法中的一部分,表示其后的group的名字为"bold"
下面是替换时的情景,其中sub函数的第一个参数是pattern,第二个参数可以是字符串也可以是函数,如果是字符串的话,那么就是将目标匹配的结果替换成指定的结果,而如果是函数,那么函数会接受一个match object的参数,并返回替换后的字符串,第三个参数便是源字符串.
result = re.sub(r"(?P<bold>!?''')", replace, line)
每当匹配到一个三单引号,replace函数便运行一次,可能这时候需要一个全局变量记录当前的三单引号是开还是闭,以便添加相应的标记.
在实际的trac wiki的实现的时候,便是这样通过一些标记变量,来记录某些语法标记的开闭,以决定replace函数的运行结果.
--------------------
示例
一. 判断字符串是否是全部小写
代码
# -*- coding: cp936 -*-
import re
s1 = 'adkkdk'
s2 = 'abc123efg'
an = re.search('^[a-z]+$', s1)
if an:
print 's1:', an.group(), '全为小写'
else:
print s1, "不全是小写!"
an = re.match('[a-z]+$', s2)
if an:
print 's2:', an.group(), '全为小写'
else:
print s2, "不全是小写!"
结果

究其因
1. 正则表达式不是python的一部分,利用时需要引用re模块
2. 匹配的形式为: re.search(正则表达式, 带匹配字串)或re.match(正则表达式, 带匹配字串)。两者区别在于后者默认以开始符(^)开始。因此,
re.search('^[a-z]+$', s1) 等价于 re.match('[a-z]+$', s2)
3. 如果匹配失败,则an = re.search('^[a-z]+$', s1)返回None
group用于把匹配结果分组
例如
import re
a = "123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
1)正则表达式中的三组括号把匹配结果分成三组
group() 同group(0)就是匹配正则表达式整体结果
group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
2)没有匹配成功的,re.search()返回None
3)当然郑则表达式中没有括号,group(1)肯定不对了。
二. 首字母缩写词扩充
具体示例
FEMA Federal Emergency Management Agency
IRA Irish Republican Army
DUP Democratic Unionist Party
FDA Food and Drug Administration
OLC Office of Legal Counsel
分析
缩写词 FEMA
分解为 F*** E*** M*** A***
规律 大写字母 + 小写(大于等于1个)+ 空格
参考代码
import re
def expand_abbr(sen, abbr):
lenabbr = len(abbr)
ma = ''
for i in range(0, lenabbr):
ma += abbr[i] + "[a-z]+" + ' '
print 'ma:', ma
ma = ma.strip(' ')
p = re.search(ma, sen)
if p:
return p.group()
else:
return ''
print expand_abbr("Welcome to Algriculture Bank China", 'ABC')
结果

问题
上面代码对于例子中的前3个是正确的,但是后面的两个就错了,因为大写字母开头的词语之间还夹杂着小写字母词
规律
大写字母 + 小写(大于等于1个)+ 空格 + [小写+空格](0次或1次)
参考代码
import re
def expand_abbr(sen, abbr):
lenabbr = len(abbr)
ma = ''
for i in range(0, lenabbr-1):
ma += abbr[i] + "[a-z]+" + ' ' + '([a-z]+ )?'
ma += abbr[lenabbr-1] + "[a-z]+"
print 'ma:', ma
ma = ma.strip(' ')
p = re.search(ma, sen)
if p:
return p.group()
else:
return ''
print expand_abbr("Welcome to Algriculture Bank of China", 'ABC')
技巧
中间的 小写字母集合+一个空格,看成一个整体,就加个括号。要么同时有,要么同时没有,这样需要用到?,匹配前方的整体。
三. 去掉数字中的逗号
具体示例
在处理自然语言时123,000,000如果以标点符号分割,就会出现问题,好好的一个数字就被逗号肢解了,因此可以先下手把数字处理干净(逗号去掉)。
分析
数字中经常是3个数字一组,之后跟一个逗号,因此规律为:***,***,***
正则式
[a-z]+,[a-z]?
参考代码3-1
import re
sen = "abc,123,456,789,mnp"
p = re.compile("\d+,\d+?")
for com in p.finditer(sen):
mm = com.group()
print "hi:", mm
print "sen_before:", sen
sen = sen.replace(mm, mm.replace(",", ""))
print "sen_back:", sen, '\n'
结果

技巧
使用函数finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
参考代码3-2
sen = "abc,123,456,789,mnp"
while 1:
mm = re.search("\d,\d", sen)
if mm:
mm = mm.group()
sen = sen.replace(mm, mm.replace(",", ""))
print sen
else:
break
结果

延伸
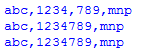
这样的程序针对具体问题,即数字3位一组,如果数字混杂与字母间,干掉数字间的逗号,即把“abc,123,4,789,mnp”转化为“abc,1234789,mnp”
思路
更具体的是找正则式“数字,数字”找到后用去掉逗号的替换
参考代码3-3
sen = "abc,123,4,789,mnp"
while 1:
mm = re.search("\d,\d", sen)
if mm:
mm = mm.group()
sen = sen.replace(mm, mm.replace(",", ""))
print sen
else:
break
print sen
结果
四. 中文处理之年份转换(例如:一九四九年--->1949年)
中文处理涉及到编码问题。例如下边的程序识别年份(****年)时
# -*- coding: cp936 -*-
import re
m0 = "在一九四九年新中国成立"
m1 = "比一九九零年低百分之五点二"
m2 = '人一九九六年击败俄军,取得实质独立'
def fuc(m):
a = re.findall("[零|一|二|三|四|五|六|七|八|九]+年", m)
if a:
for key in a:
print key
else:
print "NULL"
fuc(m0)
fuc(m1)
fuc(m2)
运行结果

可以看出第二个、第三个都出现了错误。
改进——准化成unicode识别
# -*- coding: cp936 -*-
import re
m0 = "在一九四九年新中国成立"
m1 = "比一九九零年低百分之五点二"
m2 = '人一九九六年击败俄军,取得实质独立'
def fuc(m):
m = m.decode('cp936')
a = re.findall(u"[\u96f6|\u4e00|\u4e8c|\u4e09|\u56db|\u4e94|\u516d|\u4e03|\u516b|\u4e5d]+\u5e74", m)
if a:
for key in a:
print key
else:
print "NULL"
fuc(m0)
fuc(m1)
fuc(m2)
结果

识别出来可以通过替换方式,把汉字替换成数字。
参考
numHash = {}
numHash['零'.decode('utf-8')] = '0'
numHash['一'.decode('utf-8')] = '1'
numHash['二'.decode('utf-8')] = '2'
numHash['三'.decode('utf-8')] = '3'
numHash['四'.decode('utf-8')] = '4'
numHash['五'.decode('utf-8')] = '5'
numHash['六'.decode('utf-8')] = '6'
numHash['七'.decode('utf-8')] = '7'
numHash['八'.decode('utf-8')] = '8'
numHash['九'.decode('utf-8')] = '9'
def change2num(words):
print "words:",words
newword = ''
for key in words:
print key
if key in numHash:
newword += numHash[key]
else:
newword += key
return newword
def Chi2Num(line):
a = re.findall(u"[\u96f6|\u4e00|\u4e8c|\u4e09|\u56db|\u4e94|\u516d|\u4e03|\u516b|\u4e5d]+\u5e74", line)
if a:
print "------"
print line
for words in a:
newwords = change2num(words)
print words
print newwords
line = line.replace(words, newwords)
return line
相关推荐
-
python使用正则表达式分析网页中的图片并进行替换的方法
本文实例讲述了python使用正则表达式分析网页中的图片并进行替换的方法.分享给大家供大家参考.具体分析如下: 这段代码分析网页中的所有图片表单<img>,分析后为其前后添加相应的修饰标签,并添加到图片的超级链接. 复制代码 代码如下: result = value.replace("[ page ]","").replace(' ',u' ') p=re.compile(r'''(<img\b[^<>]*?\bsrc[\s\t\r\
-
Python正则表达式的七个使用范例详解
作为一个概念而言,正则表达式对于Python来说并不是独有的.但是,Python中的正则表达式在实际使用过程中还是有一些细小的差别. 本文是一系列关于Python正则表达式文章的其中一部分.在这个系列的第一篇文章中,我们将重点讨论如何使用Python中的正则表达式并突出Python中一些独有的特性. 我们将介绍Python中对字符串进行搜索和查找的一些方法.然后我们讲讨论如何使用分组来处理我们查找到的匹配对象的子项. 我们有兴趣使用的Python中正则表达式的模块通常叫做're'. >>>
-
python使用正则表达式提取网页URL的方法
本文实例讲述了python使用正则表达式提取网页URL的方法.分享给大家供大家参考.具体实现方法如下: import re import urllib url="http://www.jb51.net" s=urllib.urlopen(url).read() ss=s.replace(" ","") urls=re.findall(r"<a.*?href=.*?<\/a>",ss,re.I) for i i
-
Python使用正则匹配实现抓图代码分享
内涵:正则匹配,正则替换,页面抓取,图片保存 . 实用的第一次 Python 代码 参考 #!/usr/bin/env python import urllib import re x=0 def getHtml(url): page = urllib.urlopen(url) html = page.read() return html def getImg(html): global x reg = 'alt=".+?" src="(.+?\.jpg)"' im
-
python正则表达式的使用
python的正则是通过re模块的支持 匹配的3个函数 match :只从字符串的开始与正则表达式匹配,匹配成功返回matchobject,否则返回none: re.match(pattern, string, flags=0) ##flags标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等. search :将字符串的所有字串尝试与正则表达式匹配,如果所有的字串都没有匹配成功,返回none,否则返回matchobject:(re.search相当于perl中的默认行为)
-
python使用正则搜索字符串或文件中的浮点数代码实例
用python和numpy处理数据次数比较多,写了几个小函数,可以方便地读写数据: # -*- coding: utf-8 -*- #---------------------------------------------------------------------- # FileName:gettxtdata.py #功能:读取字符串和文件中的数值数据(浮点数) #主要提供类似matlab中的dlmread和dlmwrite函数 #同时提供loadtxtdata和savetxtdata函
-

Python使用中文正则表达式匹配指定中文字符串的方法示例
本文实例讲述了Python使用中文正则表达式匹配指定中文字符串的方法.分享给大家供大家参考,具体如下: 业务场景: 从中文字句中匹配出指定的中文子字符串 .这样的情况我在工作中遇到非常多, 特梳理总结如下. 难点: 处理GBK和utf8之类的字符编码, 同时正则匹配Pattern中包含汉字,要汉字正常发挥作用,必须非常谨慎.推荐最好统一为utf8编码,如果不是这种最优情况,也有酌情处理. 往往一个具有普适性的正则表达式会简化程序和代码的处理,使过程简洁和事半功倍,这往往是高手和菜鸟最显著的差别.
-
python中正则表达式的使用详解
从学习Python至今,发现很多时候是将Python作为一种工具.特别在文本处理方面,使用起来更是游刃有余. 说到文本处理,那么正则表达式必然是一个绝好的工具,它能将一些繁杂的字符搜索或者替换以非常简洁的方式完成. 我们在处理文本的时候,或是查询抓取,或是替换. 一.查找 如果你想自己实现这样的功能模块,输入某一个ip地址,得到这个ip地址所在地区的详细信息. 然后你发现http://ip138.com 可以查出很详细的数据 但是人家没有提供api供外部调用,但是我们可以通过代码模拟查询然后对结
-
Python中re.findall()用法详解
在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配.本文重点给大家介绍python中正则表达式 re.findall 用法 re.findall():函数返回包含所有匹配项的列表.返回string中所有与pattern相匹配的全部字串,返回形式为数组. 示例代码1:[打印所有的匹配项] import re s = "Long live the people's Republic of China" ret = re.findall('h', s) print(r
-
python中 logging的使用详解
日志是用来记录程序在运行过程中发生的状况,在程序开发过程中添加日志模块能够帮助我们了解程序运行过程中发生了哪些事件,这些事件也有轻重之分. 根据事件的轻重可分为以下几个级别: DEBUG: 详细信息,通常仅在诊断问题时才受到关注.整数level=10 INFO: 确认程序按预期工作.整数level=20 WARNING:出现了异常,但是不影响正常工作.整数level=30 ERROR:由于某些原因,程序 不能执行某些功能.整数level=40 CRITICAL:严重的错误,导致程序不能运行.整数
-
Python中格式化format()方法详解
Python中格式化format()方法详解 Python中格式化输出字符串使用format()函数, 字符串即类, 可以使用方法; Python是完全面向对象的语言, 任何东西都是对象; 字符串的参数使用{NUM}进行表示,0, 表示第一个参数,1, 表示第二个参数, 以后顺次递加; 使用":", 指定代表元素需要的操作, 如":.3"小数点三位, ":8"占8个字符空间等; 还可以添加特定的字母, 如: 'b' - 二进制. 将数字以2为基
-
Python中的asyncio代码详解
asyncio介绍 熟悉c#的同学可能知道,在c#中可以很方便的使用 async 和 await 来实现异步编程,那么在python中应该怎么做呢,其实python也支持异步编程,一般使用 asyncio 这个库,下面介绍下什么是 asyncio : asyncio 是用来编写 并发 代码的库,使用 async/await 语法. asyncio 被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等. asyncio 往往是构建 IO 密集型和
-
python 中xpath爬虫实例详解
案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面. 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1.首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构.每一组"li"对应一组套图.属性href后面即为套图的内页地址(即广告盘链接页).所以,我们先得获取列表页内所有的内页地址(即广告盘链接页) 代码如下: import requests 倒入requests库 from lxml
-
对Python中的@classmethod用法详解
在Python面向对象编程中的类构建中,有时候会遇到@classmethod的用法. 总感觉有这种特殊性说明的用法都是高级用法,在我这个层级的水平中一般是用不到的. 不过还是好奇去查了一下. 大致可以理解为:使用了@classmethod修饰的方法是类专属的,而且是可以通过类名进行调用的.为了能够展示其与一般方法的差异,写一段简单的代码如下: class DemoClass: @classmethod def classPrint(self): print("class method"
-
python中yield的用法详解——最简单,最清晰的解释
首先我要吐槽一下,看程序的过程中遇见了yield这个关键字,然后百度的时候,发现没有一个能简单的让我懂的,讲起来真TM的都是头头是道,什么参数,什么传递的,还口口声声说自己的教程是最简单的,最浅显易懂的,我就想问没有有考虑过读者的感受. 接下来是正题: 首先,如果你还没有对yield有个初步分认识,那么你先把yield看做"return",这个是直观的,它首先是个return,普通的return是什么意思,就是在程序中返回某个值,返回之后程序就不再往下运行了.看做return之后再把它
-
Python中itertools的用法详解
iterator 循环器(iterator)是对象的容器,包含有多个对象.通过调用循环器的next()方法 (next()方法,在Python 3.x中),循环器将依次返回一个对象.直到所有的对象遍历穷尽,循环器将举出StopIteration错误. 在for i in iterator结构中,循环器每次返回的对象将赋予给i,直到循环结束.使用iter()内置函数,我们可以将诸如表.字典等容器变为循环器.比如 for i in iter([2, 4, 5, 6]): print i 标准库中的i
-
python中的 zip函数详解及用法举例
python中zip()函数用法举例 定义:zip([iterable, ...]) zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些tuples组成的list(列表).若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同.利用*号操作符,可以将list unzip(解压),看下面的例子就明白了: 示例1 x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] x