Windows服务器MySQL中文乱码的解决方法
我们自己鼓捣mysql时,总免不了会遇到这个问题:插入中文字符出现乱码,虽然这是运维先给配好的环境,但是在自己机子上玩的时候咧,总得知道个一二吧,不然以后如何优雅的吹牛B。
如果你也遇到了这个问题,咱先不谈原因,在PC自带的cmd中(或者是mysql安装版安装后的Command Line客户端,又或者是工作用的SecureCRT)试试效果。进入mysql环境,从头开始操作。假设你的客户端编码是gbk或者utf8(这么说太不严谨了,怎么能假设呢,但是一般来说假如安装后没动过,cmd是gbk编码,mysql安装后的Command Line客户端没装不记得,CRT看看Session Options里面的编码设置,一般也会设置成utf8),执行一些语句:
1. 设置编码客户端、连接、返回结果的字符集,先设置成latin1

2. 然后执行下面的看下各个字符是不是这样的
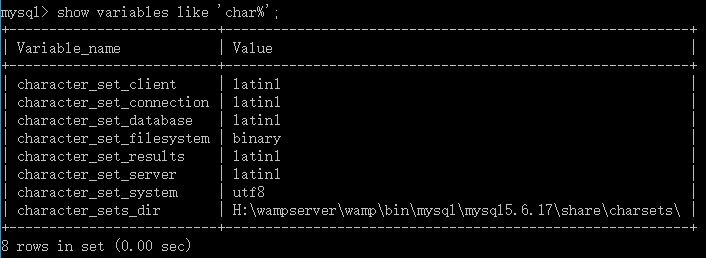
如果你的character_set_client、character_set_connection、character_set_results不是latin1,可以这样执行,把他们单个分别设置成latin1,比如设character_set_client,其他两个一样,确保这三个均是latin1(第一步的sql语句实际做的就是这件事),

3. 单独创建一个数据库db_latin1,当然是很简单的了,测试嘛,创建时就设置数据库的编码的为latin1

4. 在它下面创建一张表tab_latin1,字符集也设置成latin1,这里不设置字符也行,数据库级已经设置了,这里只创建一个name字段

5. 插入一些中文字符到表中,先说明,本机的cmd编码是gbk,查看方法是右键属性->选项,看下当前代码页即可知道

6. 查看下结果
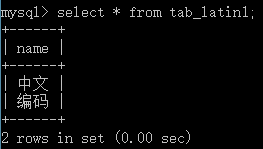
看吧,正常显示中文了~~~
OK,都到这儿了你就不想知道“为什么我那样设置就是不行”么,当然得往下看看是不。上图:
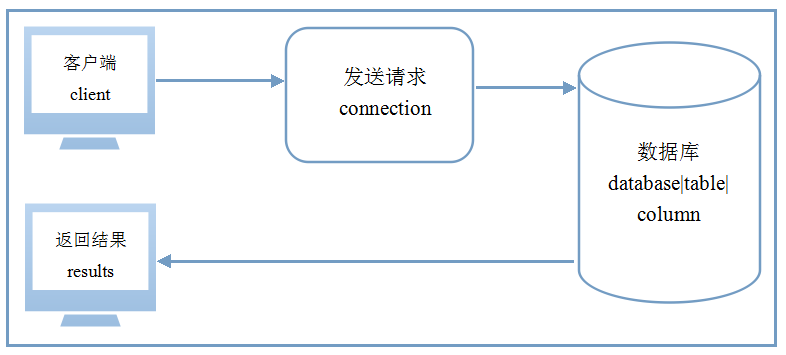
我们知道mysql是客户端-服务器软件,每次操作都是客户端向服务端发送请求,然后可能会返回一些结果,这之间插入的字符经过了一系列转换。首先供我们编辑的客户端本身就有一种编码,比如PC端的命令行默认是gbk,PC自带notepad新建文本文件默认是ANSI,常用的文本编辑器如notepad++,我们可能会设置默认编码为utf8,就是说在编辑器上编辑,你所看到的本身就是一种编码了。
1. 在客户端编辑后,首先转化为client对应的字符集,即上面打印出的character_set_client变量指示的字符集;
2. 向数据库服务发送请求,发送过程中,转化为connection对应连接字符集,即character_set_connection变量对应字符集;
3. 存储到数据库中,转化为数据库存储的字符集,可能是server级别(character_set_server)、database级别(character_set_database)或者表级别和列级别(这里还要细说下);
4. 数据库收到请求,执行查询得到结果,再次转化为results对应字符集,即character_set_results变量所指,该结果返回到客户端上;
5. 结果来了,是按照results字符集编码的,那我们让这个结果显示的客户端工具它支持什么样的编码也很重要,这决定了它如何去解码结果。假如这个结果是utf8编码,返回给某客户端了,但这个客户端只有ANSI编码,那当然不能显示正常,比如它返回到SecureCRT,结果显示不正常,但是CRT支持多种编码,我们手动将它调成utf8编码,那它就又显示正常了,所以严格来说这一步算不上,只是跟客户端条件有关,毕竟当我们知道后将客户端调整成正常的编码或者本来就支持转换results的编码后,这一步就不存在了。
在上面的第3步中,从连接字符集编码转化为数据库存储使用的编码时,要分几种情况,一般我们在装mysql时,特别是32位安装版本时,中间有一个选择编码的步骤,大多会选择utf8编码,这时系统就可能会把一系列的字符集变量均设置成了utf8,比如character_set_server、character_set_connection、character_set_database等等。也就是说这个character_set_server变量在你启动mysql服务的事先就被设置好了,我们可以称它为服务器级编码,那我们在建表前,先得创建数据库,在创建数据库时,我们知道可以显式指定编码的,比如最开头时我创建时显式指定采用latin1字符集,也可以不指定,如果不指定的话,它将采用服务器级的字符集,即character_set_server,同理在创建表时,也可不指定编码,不指定的话,采用数据库级编码,级character_set_database,更加同理在创建表中列字段时也可指定编码,不指定编码的话将采用表级别字符集,因此有这么一个继承关系在这:
character_set_server => character_set_database => character set in table(无此变量) => character set column(无此变量)
mysql创建表可以细化到这四个层次,不是每一层都必须指定,默认使用上一级的字符集(字符校对规则也是这样的,collation,稍后说明)。
那么有没有可能character_set_server没有指定呢,如果任何地方都没指定,特别是非安装版中,如果忘了,mysql在编译时默认采用latin1,为了应对这种情况,特别是非安装版本中在配置mysql时,经常需要手动配置mysql配置文件mysql.ini,其中就有大概这么一项:
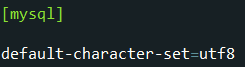
在配置文件中默认采用的字符集,因此如果指定了character_set_server默认就会采用它,这样其他层次都不指定的话依次继承。
其他的,character_set_filesystem:把操作系统上的字符转换成此字符集,即把character_set_client转换成character_set_filesystem,默认为binary则不转换,character_set_system:此变量总是utf8,为存储系统元字符的字符集,如表名、列名、用户名等,character_set_dir:很明显是指示一个目录的变量,打开这个目录,里边存放的是mysql的各种用于编码字符集的xml格式文件。以上三个值在解决乱码问题时基本可忽视。
好,转换流程和各变量的含义清楚了,就要搞清楚哪些字符集编码之间可以转换,能转换可能也是在一定编码范围内的字符能转换,不至于出现乱码甚至损坏。损坏了就再也无法正确显示了,哪怕设置是正确的,还原是还原不回来的。当然关于字符之间的转化情况很多,字符集有那么多种,随便两个之间都可以转换一下试试,不能一一列举,可以参考这篇文章:http://www.imcjd.com/?p=1324,它针对经常用到的字符转换作了一些转换比较和测试。
其中,可以了解到,完全匹配的转换是肯定没有问题的,比如,gbk->gbk,utf8->utf8,latin1->latin1;转换为单字节编码的latin1也没问题,比如gbk->latin1、utf8->latin1;单字节编码(latin1)转为其他在某些编码某些范围内可能会出现转换不全,比如latin1->gbk(很特殊的中文),或者编码长度改变,比如latin1->utf8,变为2、3等字节数。
下面引用另一篇文章(http://hi.baidu.com/cuttinger/item/f4e79726a60ab450c28d59da)中的一段。
【Latin1是一种很常见的字符集,这种字符集是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。很明显,Latin1覆盖了所有的单字节,因此,可以将任意字符串保存在latin1字符集中,而不用担心有内容不符合latin1的编码规范而被抛弃。——gbk和utf8是多字节编码,没有这种特性。
mysql使用者经常利用Latin1的这种全覆盖特性,将其它类型的字符串,gbk,utf8,big5等,保存在latin1列中。保存的过程中没有数据丢失,只要原样取出来,便又是合法的gbk/utf8/big字符串。如果将gbk字符串保存在utf8列中,则gbk字符串中那些不符合utf8编码格式的内容,会被抛弃,保存的内容无法原样取出,数据实际上遭到了破坏。
综上,如果我们看到一个字段的字符集是latin1的,那么,他保存的可能是任何编码的字符串;而一个字段的字符集是utf8或者gbk的,那么他保存的就应该是utf8或gbk的——除非数据库的使用者用错了。】
我没有深入学习过utf8、gbk编码的细节,极可能说的不准确,只知道简单的ASCII编码(-_-),但是可以了解个全局情况。从上面来看,latin1的单字节编码方式很有用,其他的编码可以转换为它再转回去而不至于丢失内容。所谓单字节编码就是挨着一个个来,我理解是,比如圣诞节到了,你要送妹子一箱苹果,为制造浪漫,商铺提供两种包装方式,一是按个数来,即单个苹果包装进一个盒子,来一个包装一个,这样,妹子在拆完所有的盒子后完完整整的可以还原为一个个完整的和一箱完好无损的苹果,二是按重量来,每个盒子限重2两、3两、6两,这样在包装时,若刚好重3两的当然可以完整的放进一个盒子,但是若不够或者多了,勉不了要切开苹果,或者再往盒子中添加其他的部分苹果,这样的话,妹子再无论怎样拆开盒子,都会得到一箱残缺不堪的苹果了,因为你在按照这种包装方式进行时,已经破坏了单个苹果的完整性,现在还原不回来了~我们的字符集编码转换就是在做这种重新包装的工作,latin1恰好就像单个苹果包装,而utf8就像第二种方式。
而刚才说的完全匹配的情况是,你去买一箱苹果,箱子里边的所有苹果重量已经恰好要么是2两,要么是3两或6两的,这样再按重量包装时当然就恰好分配了,得到的仍然是完整的苹果。
所以说白了,两种可行的方式是:
1. 所有变量均设置成latin1(set names latin1;),这样,即便我们所使用的编辑客户端编码多样(gbk或utf8),最终可以得到正确结果;
2. 所有的设置成gbk或者gb2312(国标编码,只用于简体中文),采用完全匹配;
3. 针对中间的转换过程,比如gbk输入,将character_set_client、character_set_connection视为latin1,character_set_database设为gb2312,建表时定字符集为gb2312,character_set_results也可以定为gb2312,当然这只是鸡肋,本质上还是用了latin1,gbk转latin1再转gb2312时只适用于简体。
最后,关于字符集校对规则,只了解一点。在我们设置mysql字符集时,mysql会自动给一个对应的校对规则,比如设置charset为utf8,默认的collation就是utf8_general_ci,gb2312字符集对应gb2312_chinese_ci,mysql命令查看所有校对规则是show collation,查看某一对应字符集的校对规就是show collation like 'utf8%'了。
字符集校对是一种对使用当前字符集时采用的排序、对比方式,即便同一种字符集,在不同的地区也是不同的对比方式,所以才有校对这么一说,比如utf8_general_ci,这个ci就是case insensitive,即大小写不敏感,采用它校对时,查询某字段值匹配时,大小写的记录都会出现,当然还有其他的规则,utf8打印出来一大坨,不细研究了~
相关推荐
-

实战mysql导出中文乱码及phpmyadmin导入中文乱码的解决方法
一直不用这个phpmyadmin,在本机也是用navicat,总感觉phpmyadmin速度较慢.这回不行了,没有独立主机,只好用人家给的phpmyadmin了. 第一步:本地数据导出sql文件.心想这对于navicat小事一桩.直接在数据库上右键"转储sql"(如图1),哗哗,十几秒的时间导出成功. (图1:navicat下对整个数据库转sql) 用记事本打开一看,傻眼了.中文全是乱码.咋回事呢?搜索了一下,改变什么连接属性啥的.不管用.试着在单张表上,转储sql,嘿,中文正常.但是
-
mysql 中文乱码 解决方法集锦
第一个方法: MySQL 4.1 中文乱码的问题 最近要将 MySQL 4.0 升级到 MySQL 4.1 ,发现了中文乱码的问题,希望以下见解对大家有用. 1. MySQL 4.1 在文字上有很大改进,它有了 Character Set 与 Collation 的慨念. 2. 在 MySQL 4.0 ,一般的程式都会将文字以拉丁文 ( latin) 来储存,就算我们输入中文字,结果仍是放在以拉丁文设置的文字栏里头,这对 MySQL 4.0 与以 MySQL 4.0 为基楚的程式来说,并不会有问
-
mysql query browser中文乱码的解决方法
我也一一试过,结果是:中文乱码问题没解决,mysql服务却不能启动了, 汗颜了,还是自己动手解决吧,我这里也截图了,方便参观.我用的是appserv服务包,相信很大一部分同学都在使用这个或是在使用wamp包,很简单,在安装mysql目录下,找到my.ini配置文件: 重启MYSQL服务和apache服务就可以了.
-
MySql中表单输入数据出现中文乱码的解决方法
MySQL会出现中文乱码的原因在于 1.server本身设定问题,一般来说是latin1 2.建库建表时没有制定编码格式. MySql中表单输入数据出现中文乱码的解决方法: 1.建库的时候 CREATE DATABASE test CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'; 2.建表的时候 CREATE TABLE content ( text VARCHAR(100) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
-
PHP读MYSQL中文乱码的解决方法
打算切换某个网站的主机,没想到遇到Php和Mysql中文乱码的问题. 以前的国外主机用的Mysql是4.x系列的,感觉还比较好,都无论GBK和UTF-8都没有乱码,没想到新的主机的Mysql是5.0版本的,导入数据后,用Php读出来全是问号,乱码一片,记得我以前也曾经有过一次切换出现乱码的经验,原因肯定是Mysql版本之间的差异问题. 只好查资料,发现了一个解决方法,就是在mysql_connect后面加一句SET NAMES UTF8,即可使得UTF8的数据库消除乱码,对于GBK的数据库则使用
-
windows环境下Mysql中文乱码问题解决方法
最近开发项目中又重新拿起了Mysql,在搭建环境的时候遇到了中文乱码问题.下面我把我的解决方式跟大家分享一下 1.通过show VARIABLES like 'character_%'; 显示出来所有的设置项目.把其中的非UTF8的编码都设置成utf8 设置方式如 : set character_set_server=utf8; 2.去mysql 安装目录下找到my.ini文件.设置里面的latin1为utf8 3.另外如果在Java端通信数据的时候发生了乱码的话就response.setCha
-
Mysql中文乱码问题的最佳解决方法
一般来说,造成MySQL出现中文乱码的因素主要有下列几点: 1.server本身字符集设定的问题,例如还停留在latin1 2.table的语系设定问题(包含character与collation) 3.客户端程序(例如php)的连线语系设定问题 对此,强烈建议使用utf8编码!因为utf8可以兼容世界上所有字符! 一.避免创建数据库及表出现中文乱码和查看编码方法 1.创建数据库的时候: CREATE DATABASE `test` CHARACTER SET 'utf8' COLLATE 'u
-
MySQL从命令行导入SQL脚本时出现中文乱码的解决方法
本文实例讲述了MySQL从命令行导入SQL脚本时出现中文乱码的解决方法.分享给大家供大家参考,具体如下: 在图形界面管理工具 MySql Query Browser中打开脚本(脚本包括建库.建表.添加数据),并执行,不会有任何问题:但是使用mysql命令行工具执行建库脚本时,添加数据中如果包含中文,存入的数据就是乱码或是???... 解决方法1:在MySql安装目录下找到my.ini,将[mysql]下的default-character-set=latin1改为default-characte
-
mysql导入导出数据中文乱码解决方法小结
linux系统中 linux默认的是utf8编码,而windows是gbk编码,所以会出现上面的乱码问题. 解决mysql导入导出数据乱码问题 首先要做的是要确定你导出数据的编码格式,使用mysqldump的时候需要加上--default-character-set=utf8, 例如下面的代码: 复制代码 代码如下: mysqldump -uroot -p --default-character-set=utf8 dbname tablename > bak.sql 那么导入数据的时候也要使用-
-
Windows服务器MySQL中文乱码的解决方法
我们自己鼓捣mysql时,总免不了会遇到这个问题:插入中文字符出现乱码,虽然这是运维先给配好的环境,但是在自己机子上玩的时候咧,总得知道个一二吧,不然以后如何优雅的吹牛B. 如果你也遇到了这个问题,咱先不谈原因,在PC自带的cmd中(或者是mysql安装版安装后的Command Line客户端,又或者是工作用的SecureCRT)试试效果.进入mysql环境,从头开始操作.假设你的客户端编码是gbk或者utf8(这么说太不严谨了,怎么能假设呢,但是一般来说假如安装后没动过,cmd是gbk编码,m
-
Windows下在CMD下执行Go出现中文乱码的解决方法
在cmd下运行go程序或者是GOLAND的Terminal下运行go程序会出现中文乱码的情况. go run ttypemain.go ���� Ping [127.0.0.1] ���� 32 �ֽڵ�����: ���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128 ���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128 ���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128 ����
-
Windows下CMD执行Go出现中文乱码的解决方法
在cmd下运行go程序或者是GOLAND的Terminal下运行go程序会出现中文乱码的情况. go run ttypemain.go ���� Ping [127.0.0.1] ���� 32 �ֽڵ�����:���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128���� 127.0.0.1 �Ļظ�: �ֽ�=32 ʱ��<1ms TTL=128���� 127.
-
CMD下执行Go出现中文乱码的解决方法
目录 1.报错信息如下 2.原因分析 3.解决方法 4.封装处理乱码方法 5.解决乱码完整代码 1.报错信息如下 2.原因分析 因为Go的编码是UTF-8,而CMD的活动页是cp936(GBK),因此产生乱码.在中文Windows系统中,如果一个文本文件是UTF-8编码的,那么在CMD.exe命令行窗口(所谓的DOS窗口)中不能正确显示文件中的内容.在默认情况下,命令行窗口中使用的代码页是中文或者美国的,即编码是中文字符集或者英文字符集. 3.解决方法 golang处理中文时默认是utf8,当遇
-
iOS读取txt文件出现中文乱码的解决方法
一.情景描述: 后台给一个txt文件,编码是utf-8,在Mac电脑Xcode开发环境下读取txt文件内容,汉字会出现乱码,英文没有乱码这种情况. 二.尝试解决方法: 修改编码格式,尝试了NSUTF16StringEncoding,NSUTF8StringEncoding,NSASCIIStringEncoding编码等,出现的问题有时是中文乱码,有时是utf-8不能打开文件问题,最终问题都没能解决. 三.猜测原因: txt文件是从window电脑上创建,有可能和环境有关,第二,编码问题. 四.
-
Java读取properties配置文件时,出现中文乱码的解决方法
如下所示: public static String getConfig(String key) { Properties pros = new Properties(); String value = ""; try { pros.load(new InputStreamReader(Object.class.getResourceAsStream("/properties.properties"), "UTF-8")); value = pr
-
php生成二维码时出现中文乱码的解决方法
本文实例讲述了php生成二维码时出现中文乱码的解决方法.分享给大家供大家参考.具体分析如下: 最近做了个扫描二维码得到vcard的项目,遇到一个问题,有一部分生成完的二维码,用android系统手机扫描后得到的vcard中的中文姓名是乱码,经过比对发现,这部分vcard中ORG这个类型没有内容,随即判断没内容就加上一个固定的字符串,这样乱码的问题得以解决. php生成二维码的几种方式 1.google开放api,代码如下: 复制代码 代码如下: $urlToEncode="http://www.