详解python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'如何解决
python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'的解决方法:
1.原因是官网的是python2语法写的,看官手动把官网的HTMLTestRunner.py改成python3的语法:
参考:http://bbs.chinaunix.net/thread-4154743-1-1.html
下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html
修改后下载地址:HTMLTestRunner_jb51.rar (懒人直接下载吧)
2.修改汇总:
第94行,将import StringIO修改成import io
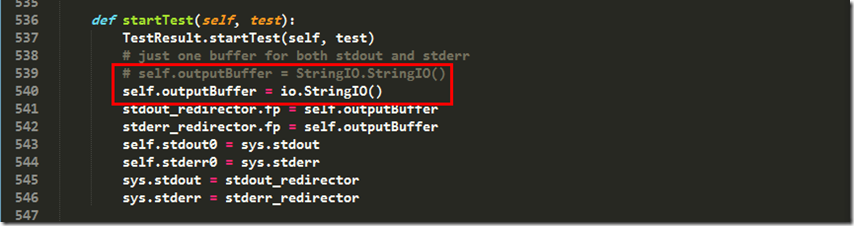
第539行,将self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
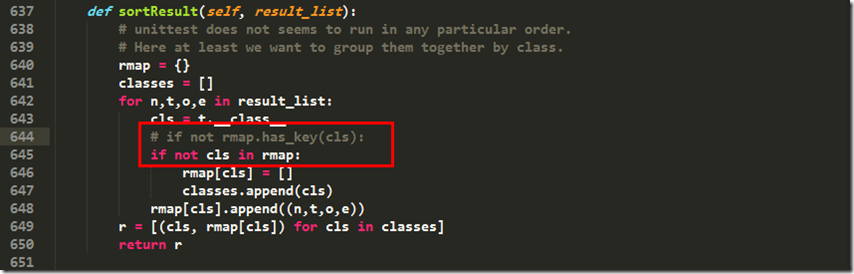
第642行,将if not rmap.has_key(cls):修改成if not cls in rmap:
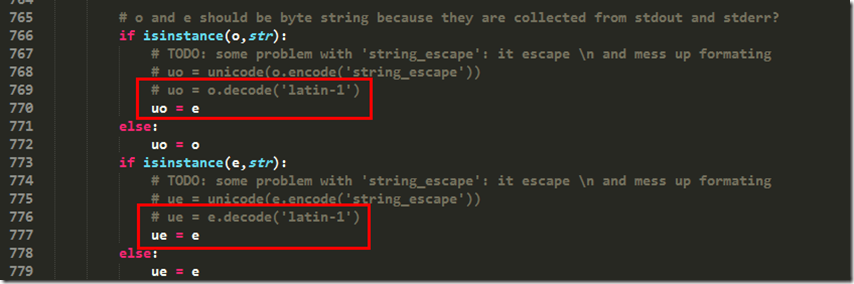
第766行,将uo = o.decode('latin-1')修改成uo = e
第775行,将ue = e.decode('latin-1')修改成ue = e
第631行,将print >> sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime)修改成print(sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime))
在Python3.4下使用HTMLTestRunner,开始时,引入HTMLTestRunner模块报错。

在HTMLTestRunner的94行中,是使用的StringIO,但是Python3中,已经没有StringIO了。取而代之的是io.StringIO。所以将此行修改成import io

在HTMLTestRunner的539行中,self.outputBuffer = StringIO.StringIO()修改成self.outputBuffer = io.StringIO()
修改以后,成功引入模块了

执行脚本代码:
# -*- coding: utf-8 -*-
#引入webdriver和unittest所需要的包
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest, time, re
#引入HTMLTestRunner包
import HTMLTestRunner
class Baidu(unittest.TestCase):
#初始化设置
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://www.baidu.com/"
self.verificationErrors = []
self.accept_next_alert = True
#百度搜索用例
def test_baidu(self):
driver = self.driver
driver.get(self.base_url)
driver.find_element_by_id("kw").click()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("Selenium Webdriver")
driver.find_element_by_id("su").click()
time.sleep(2)
driver.close()
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
if __name__ == "__main__":
#定义一个测试容器
test = unittest.TestSuite()
#将测试用例,加入到测试容器中
test.addTest(Baidu("test_baidu"))
#定义个报告存放的路径,支持相对路径
file_path = "F:\\RobotTest\\result.html"
file_result= open(file_path, 'wb')
#定义测试报告
runner = HTMLTestRunner.HTMLTestRunner(stream = file_result, title = u"百度搜索测试报告", description = u"用例执行情况")
#运行测试用例
runner.run(test)
file_result.close()
运行测试脚本后,发现报错:
File "C:\Python34\lib\HTMLTestRunner.py", line 642, in sortResult
if not rmap.has_key(cls):
所以前往642行修改代码:
运行后继续报错:
AttributeError: 'str' object has no attribute 'decode'
前往766, 772行继续修改(注意:766行是uo而772行是ue,当时眼瞎,没有注意到这些,以为是一样的,导致报了一些莫名其妙的错误,折腾的半天):
修改后运行,发现又报错:
File "C:\Python34\lib\HTMLTestRunner.py", line 631, in run
print >> sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime)
TypeError: unsupported operand type(s) for >>: 'builtin_function_or_method' and '_io.TextIOWrapper'
前往631查看,发现整个程序中,唯一一个print:
print >> sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime
这个是2.x的写法,咱们修改成3.x的print,修改如下:
print(sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python使用 HTMLTestRunner.py生成测试报告
本文介绍了python使用 HTMLTestRunner.py生成测试报告 ,分享给大家,具体如下: HTMLTestRunner.py python 2版本 下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html 使用时,先建立一个"PyDev Package",将下载下来的HTMLTestRunner.py文件拷贝在该目录下. 例子:testcase5_dynamic.py import unittest from dev.
-
详解python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'如何解决
python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'的解决方法: 1.原因是官网的是python2语法写的,看官手动把官网的HTMLTestRunner.py改成python3的语法: 参考:http://bbs.chinaunix.net/thread-4154743-1-1.html 下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html 修改后下载地址:
-
详解python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'如何解决
python3中用HTMLTestRunner.py报ImportError: No module named 'StringIO'的解决方法: 1.原因是官网的是python2语法写的,看官手动把官网的HTMLTestRunner.py改成python3的语法: 参考:http://bbs.chinaunix.net/thread-4154743-1-1.html 下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html 修改后下载地址:
-
详解Python3.6的py文件打包生成exe
原文提到的要点: 1. Python版本32位 (文件名为 python-3.6.1.exe) 2. 安装所有用到的模块(原文博主用的是openpyxl,我用到的有urllib中的request\config\data) 3. 下载替换pyinstaller(下载pyinstaller-develop.zip,复制其中的Pyinstaller文件夹) 4. 在控制台生成exe 操作过程记录如下: C:\Python\Scripts>pip install request C:\Python\Sc
-
详解Python3 中hasattr()、getattr()、setattr()、delattr()函数及示例代码数
hasattr()函数 hasattr()函数用于判断是否包含对应的属性 语法: hasattr(object,name) 参数: object--对象 name--字符串,属性名 返回值: 如果对象有该属性返回True,否则返回False 示例: class People: country='China' def __init__(self,name): self.name=name def people_info(self): print('%s is xxx' %(self.name))
-
详解Python3.8+PyQt5+pyqt5-tools+Pycharm配置详细教程
个人使用环境 WIN10x64系统,Python3.8,PyCharm2020.01.03 安装过程 一.安装Python3.8 (自己参考其他教程) 二.安装PyQt5 然后在cmd下输入指令 pip install PyQt5 也可以输入这个指令 pip install PyQt5 -i https://pypi.douban.com/simple (后面是豆瓣的镜像地址,是为了加快下载速度) 提示你更新pip,就按照提示更新(这步骤是可选的,看个人需求) 在cmd下输入 python -m
-
详解python3类型注释annotations实用案例
1.类型注解简介 Python是一种动态类型化的语言,不会强制使用类型提示,但为了更明确形参类型,自python3.5开始,PEP484为python引入了类型注解(type hints) 示例如下: 2.常见的数据类型 int,long,float: 整型,长整形,浮点型 bool,str: 布尔型,字符串类型 List, Tuple, Dict, Set: 列表,元组,字典, 集合 Iterable,Iterator: 可迭代类型,迭代器类型 Generator:生成器类型 Sequence
-
示例详解Python3 or Python2 两者之间的差异
每门编程语言在发布更新之后,主要版本之间都会发生很大的变化. 在本文中,Vinodh Kumar 通过示例解释了 Python 2 和 Python 3 之间的一些重大差异,以帮助说明语言的变化. 本教程主要介绍内容: 表达式 Print 选项 Unequal 操作 Range 自动迁移 性能问题 主要的内部事务更改 1.表达式 在 Python 2 中为获得计算表达式,你会键入: 但在 Python 3 中,你会键入: 因此,无论我们输入什么,值都会分配给 2 和 3 中的变量 x.当在 Py
-
详解Python3 pandas.merge用法
摘要 数据分析与建模的时候大部分时间在数据准备上,包括对数据的加载.清理.转换以及重塑.pandas提供了一组高级的.灵活的.高效的核心函数,能够轻松的将数据规整化.这节主要对pandas合并数据集的merge函数进行详解.(用过SQL或其他关系型数据库的可能会对这个方法比较熟悉.)码字不易,喜欢请点赞!!! 1.merge函数的参数一览表 2.创建两个DataFrame 3.pd.merge()方法设置连接字段. 默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于o
-
对sklearn的使用之数据集的拆分与训练详解(python3.6)
研修课上讲了两个例子,融合一下. 主要演示大致的过程: 导入->拆分->训练->模型报告 以及几个重要问题: ①标签二值化 ②网格搜索法调参 ③k折交叉验证 ④增加噪声特征(之前涉及) from sklearn import datasets #从cross_validation导入会出现warning,说已弃用 from sklearn.model_selection import train-test_split from sklearn.grid_search import Gri
-
详解Python3中的 input() 函数
一.知识介绍: 1.input() 函数,接收任意输入,将所有输入默认为字符串处理,并返回字符串类型: 2.可以用作文本输入,如用户名,密码框的值输入: 3.语法:input("提示信息:") . 二.运用演示: 1.接收任意输入,并返回字符串类型: >>>height = input("输入身高:") #运行 输入身高: 170 #输入整数170 >>> type(a)