利用python实现对web服务器的目录探测的方法
一、python
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
python 是一门简单易学的语言,并且功能强大也很灵活,在渗透测试中的应用广泛,让我们一起打造属于自己的渗透测试工具
二、web服务器的目录探测脚本打造
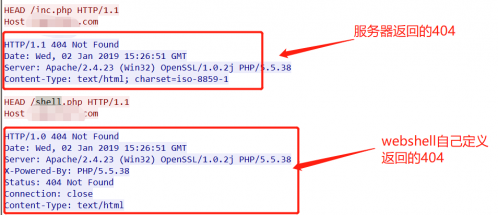
1、在渗透时如果能发现web服务器中的webshell,渗透是不是就可以变的简单一点尼
通常情况下御剑深受大家的喜爱,但是今天在测试的时候webshell不知道为什么御剑扫描不到
仔细查看是webshell有防爬功能,是检测User-Agent头,如果没有就回返回一个自己定义的404页面
1、先来看看工具效果

2、利用python读取扫描的目录字典
def get_url(path):
with open(path, "r", encoding='ISO-8859-1') as f:
for url in f.readlines():
url_list.append(url.strip())
return url_list
3、利用 python 的 requests 库对web目标服务器进行目录探测
def Go_scan(url):
while not queue.empty():
url_path = queue.get(timeout=1)
new_url = url + url_path
res = requests.get(new_url, headers=headers, timeout=5)
#print(res.status_code)
status_code = "[" + str(res.status_code) + "]"
if str(res.status_code) != "404":
print(get_time(), status_code, new_url)
4、利用 python 的 threading 库对探测进行线程的设置
def thread(Number,url):
threadlist = []
for pwd in url_list:
queue.put(pwd)
for x in range(Number):
t = threading.Thread(target=Go_scan, args=(url,))
threadlist.append(t)
for t in threadlist:
t.start()
5、利用 python 的 argparse 库进行对自己的工具进行封装
def main():
if len(sys.argv) == 1:
print_banner()
exit(1)
parser = argparse.ArgumentParser(
formatter_class=argparse.RawTextHelpFormatter,
epilog='''\
use examples:
python dir_scan.py -u [url]http://www.test.com[/url] -d /root/dir.txt
python dir_scan.py -u [url]http://www.test.com[/url] -t 30 -d /root/dir.txt
''')
parser.add_argument("-u","--url", help="scan target address", dest='url')
parser.add_argument("-t","--thread", help="Number of threads", default="20", type=int, dest='thread')
parser.add_argument("-d","--Dictionaries", help="Dictionary of Blasting Loading",
dest="Dictionaries")
总结
各位大哥有意见或者建议尽管提,文章哪里不对的话会改的,小弟定会虚心学习最后附上全部源码供大佬指教
#!/usr/bin/python
# -*- coding: utf-8 -*-
import requests
import threading
import argparse,sys
import time,os
from queue import Queue
url_list = []
queue = Queue()
headers = {
'Connection':'keep-alive',
'Accept':'*/*',
'Accept-Language': 'zh-CN',
'User-Agent':'Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0'
}
def print_banner():
banner = r"""
.___.__ __________________ _____ _______
__| _/|__|_______ / _____/\_ ___ \ / _ \ \ \
/ __ | | |\_ __ \ \_____ \ / \ \/ / /_\ \ / | \
/ /_/ | | | | | \/ / \\ \____/ | \/ | \
\____ | |__| |__| /_______ / \______ /\____|__ /\____|__ /
\/ \/ \/ \/ \/
[*] Very fast directory scanning tool.
[*] try to use -h or --help show help message
"""
print(banner)
def get_time():
return '[' + time.strftime("%H:%M:%S", time.localtime()) + '] '
def get_url(path):
with open(path, "r", encoding='ISO-8859-1') as f:
for url in f.readlines():
url_list.append(url.strip())
return url_list
def Go_scan(url):
while not queue.empty():
url_path = queue.get(timeout=1)
new_url = url + url_path
res = requests.get(new_url, headers=headers, timeout=5)
#print(res.status_code)
status_code = "[" + str(res.status_code) + "]"
if str(res.status_code) != "404":
print(get_time(), status_code, new_url)
def thread(Number,url):
threadlist = []
for pwd in url_list:
queue.put(pwd)
for x in range(Number):
t = threading.Thread(target=Go_scan, args=(url,))
threadlist.append(t)
for t in threadlist:
t.start()
def main():
if len(sys.argv) == 1:
print_banner()
exit(1)
parser = argparse.ArgumentParser(
formatter_class=argparse.RawTextHelpFormatter,
epilog='''\
use examples:
python dir_scan.py -u [url]http://www.test.com[/url] -d /root/dir.txt
python dir_scan.py -u [url]http://www.test.com[/url] -t 30 -d /root/dir.txt
''')
parser.add_argument("-u","--url", help="scan target address", dest='url')
parser.add_argument("-t","--thread", help="Number of threads", default="20", type=int, dest='thread')
parser.add_argument("-d","--Dictionaries", help="Dictionary of Blasting Loading",
dest="Dictionaries")
args = parser.parse_args()
Number =args.thread
url = args.url
url_path = args.Dictionaries
print_banner()
get_url(url_path)
print(get_time(), "[INFO] Start scanning----\n")
time.sleep(2)
thread(Number,url)
if __name__ == '__main__':
main()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python Web程序搭建简单的Web服务器
上一篇讲了<Python入门>Windows 7下Python Web开发环境搭建笔记,接下来讲一下Python语言Web服务的具体实现:第一个Python Web程序--简单的Web服务器. 与其它Web后端语言不同,Python语言需要自己编写Web服务器. 如果你使用一些现有的框架的话,可以省略这一步: 如果你使用Python CGI编程的话,也可以省略这一步: 用Python建立最简单的web服务器 利用Python自带的包可以建立简单的web服务器.在DOS里cd到准备做服务器根目录
-
python实现静态web服务器
HTTP协议简介 HTTP请求 1:浏览器首先向服务器发送HTTP请求,请求包括: 方法:GET还是POST,GET仅请求资源,POST会附带用户数据: 路径:/full/url/path: 域名:由Host头指定:Host: www.sina.com以及其他相关的Header: 如果是POST,那么请求还包括一个Body,包含用户数据 2:服务器向浏览器返回HTTP响应,响应包括: 响应代码:200表示成功,3xx表示重定向,4xx表示客户端发送的请求有错误,5xx表示服务器端处理时发生了错误
-

Python 搭建Web站点之Web服务器网关接口
在 Python 搭建Web站点之Web服务器与Web框架 中我们弄清楚了Web 服务器.Web 应用程序.Web框架的概念.对于 Python 来说,越来越多的 Web 框架面世,在给我们更多选择机会的同时,也限制了我们对于 Web Server 的选择.同样是有着很多 Web 框架的Java,因为有着 servlet API 的存在,任何Java Web框架写的应用程序都可以运行在任意一个 Web Server 上. Python 社区当然也需要这样一套 API,来适配Web服务器和应用程序
-
python快速建立超简单的web服务器的实现方法
作为临时测试用python命令来搭建web测试是最好不过的选择了: CD切换到当前目录只需要一句python命令就迅速搭建好了简单的web服务器,python linux自带又无需额外配置安装感觉还是很好用的: python开启web服务器命令 python -m SimpleHTTPServer 8080 端口号可以任意指定一个没有被占用的端口,但必须能通过防火墙: 执行完上面命令后,直接输入IP地址加端口号就行了 http://:端口号/路径 如:http://192.168.0.12/8
-
Python基于twisted实现简单的web服务器
本文实例讲述了Python基于twisted实现简单的web服务器,分享给大家供大家参考.具体方法如下: 1. 新建htm文件夹,在这个文件夹中放入显示的网页文件 2. 在htm文件夹的同级目录下,建立web.py,web.py的内容为: from twisted.web.resource import Resource from twisted.web import server from twisted.web import static from twisted.internet impo
-
Python Web服务器Tornado使用小结
首先想说的是它的安全性,这方面确实能让我感受到它的良苦用心.这主要可以分为两点: 一.防范跨站伪造请求(Cross-site request forgery,简称 CSRF 或 XSRF) CSRF 的意思简单来说就是,攻击者伪造真实用户来发送请求. 举例来说,假设某个银行网站有这样的 URL:http://bank.example.com/withdraw?amount=1000000&for=Eve当这个银行网站的用户访问该 URL 时,就会给 Eve 这名用户一百万元.用户当然不会轻易地点
-
python批量同步web服务器代码核心程序
#!/usr/bin/env python #coding:utf8 import os,sys import md5,tab from mysql_co.my_db import set_mysql from ssh_co.ssh_connect import sshd from ssh_co.cfg.config import ssh_message,item_path from file import findfile def my_mysql(): db_file={} my_conne
-
Python实现的检测web服务器健康状况的小程序
对web服务器做健康检查,一般我们都是用curl库(不管是php,perl的还是shell的),大致的方法一致: 复制代码 代码如下: curl -I -s www.qq.com |head -1|awk '{ health = $2=="200"?"server is ok":"server is bad"}END{print health}' server is ok 说白了这些方式都是封装了curl库的,另外还有一些关于http的模块,例
-
Python命令启动Web服务器实例详解
Python命令启动Web服务器实例详解 利用Python自带的包可以建立简单的web服务器.在DOS里cd到准备做服务器根目录的路径下,输入命令: python -m Web服务器模块 [端口号,默认8000] 例如: python -m SimpleHTTPServer 8080 然后就可以在浏览器中输入 http://localhost:端口号/路径 来访问服务器资源. 例如: http://localhost:8080/index.htm(当然index.htm文件得自己创建) 其他机器
-
Python 搭建Web站点之Web服务器与Web框架
之前用 Django 做过一个小的站点,感觉Django太过笨重,于是就准备换一个比较轻量级的 Web 框架来玩玩.Web.py 作者已经挂掉,项目好久没有更新,所以不准备用它.而 Flask 也是一个成熟的轻量级 Web 框架,在 github 上有众多的 Star 和 Fork,文档和扩展也很丰富,值得学习. 学习一个框架最好的方式就是用框架做一个项目,在实战中理解掌握框架.这里我用 Flask 框架,使用 Mysql 数据库做了一个 论坛系统 .麻雀虽小,五脏俱全,论坛效果图如下: 论坛系
-
python探索之BaseHTTPServer-实现Web服务器介绍
在Python探索之SocketServer详解中我们介绍了Python标准库中的SocketServer模块,了解了要实现网络通信服务,就要构建一个服务器类和请求处理类.同时,该模块还为我们创建了不同的服务器类和请求处理类. 1.服务器类 BaseServer TCPServer(BaseServer) UDPServer(TCPServer) UnixStreamServer UnixDatagramServer 2.请求处理类 BaseRequestHandler StreamReques
-
Python编程实现的简单Web服务器示例
本文实例讲述了Python编程实现的简单Web服务器.分享给大家供大家参考,具体如下: 最近有个需求,就是要创建一个简到要多简单就有多简单的web服务器,目的就是需要一个后台进程用来接收请求然后处理并返回结果,因此就想到了使用Python来实现. 首先创建一个myapp.py文件,其中定义了一个方法,所有的请求都会经过此方法,可以在此方法里处理传递的url和参数,并返回结果. def myapp(environ, start_response): status = '200 OK' header
-
Python实现简易版的Web服务器(推荐)
下面给大家介绍python实现简易版的web服务器,具体内容详情大家通过本文学习吧! 1.请自行了解HTTP协议 http://www.jb51.net/article/133883.htm(点击跳转) 2.创建Socket服务,监听指定IP和端口 3.以阻塞方式等待客户端连接 4.读取客户端请求数据并进行解析 5.准备服务器运行上下文 6.处理客户端请求数据 7.根据用户请求路径读取文件 8.返回响应结果给客户端 9.程序入口 10.目录结构 11.运行 python wsgiserver.p