python爬虫获取京东手机图片的图文教程
如题,首先当然是要打开京东的手机页面

因为要获取不同页面的所有手机图片,所以我们要跳转到不同页面观察页面地址的规律,这里观察第二页页面

由观察可以得到,第二页的链接地址很有可能是
https://list.jd.com/list.html?cat=9987,653,655&page=2
那么对应第n页的地址就是
https://list.jd.com/list.html?cat=9987,653,655&page=n
我们就可以利用这个规律在编程的时候打开自己想要获取的页面了
接着我们查看页面的源代码,观察图片链接的规律


我们使用在源代码的页面使用ctrl+f查找,然后在查找框里面输入页面第一台手机的名字 “vivo X9s 全网通 4GB+64GB 玫瑰金 移动” 快速定位到图片链接附近的代码,便于后面编程对图片范围进行筛选

可以看到,上图的画红线的三个部分,<div id="plist" 在这一页中是唯一出现的一个元素,而且离图片链接比较近,所以可以作为筛选页面的开头位置
<img width=“220”……这个是手机图片的信息,我们要获取的是后面
//img14.360buyimg.com/n7/jfs/t6088/107/5539077608/409616/7f98b2bb/596c2edaN9792cd20.jpg
这个链接,但是观察发现后面也有一个图片链接
img data-sku="5291744" width="25" height="25" class="loading-style2" src="https://img14.360buyimg.com/n9/jfs/t6088/107/5539077608/409616/7f98b2bb/596c2edaN9792cd20.jpg"
这个很明显不是我们要找的手机图片链接
所以我们要使用正则表达式将真正的图片链接筛选出来,观察发现这两个图片链接的区别在于手机图片链接里面含有n7元素,而另外一个图片链接含有n9元素,这样子我们的正则表达式就可以表示为pat2 = '//.+?/n7/.+?\.jpg'
接着我们要找到这个页面最后一张手机图片的位置,方便找出可以作为筛选页面的结束位置,方法和上面类似,在源代码搜索框输入 小米(MI) 红米Note4X 手机 香槟金 全网通 3GB+32GB 定位到页面最后一张图片位置
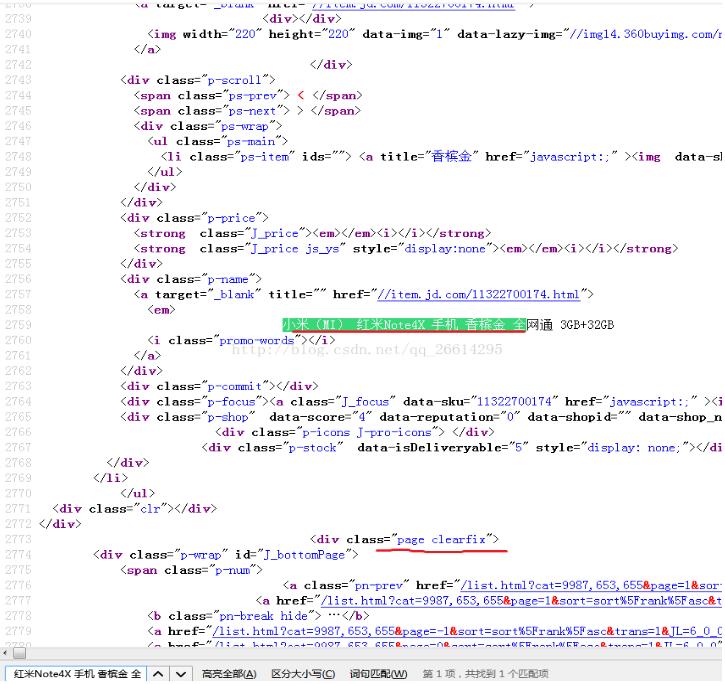
可以看到,下面<div class="page clearfix">在该页面中是唯一的,而且比较接近最后一张手机图片附近的链接,所以可以作为筛选结尾位置的元素,其实筛选的元素只要满足唯一并且接近我们要获取的目标,那么也可以作为我们要选取的元素
经过上面准备之后,我们得出了大概的思路
1首先进行第一次筛选,使用正则表达式pat1 = '<div id="plist".+<div class="page clearfix">'将图片链接的范围大概筛选出来
2然后进行第二次筛选,使用正则表达式pat2 = '//.+?/n7/.+?\.jpg'将手机图片链接筛选出来
3使用urllib.urlretrieve保存链接图片到本地
下面给出python代码
# -*- coding: UTF-8 -*- import re import urllib2 import urllib def craw(url, page): html1 = urllib2.urlopen(url).read() html1 = str(html1) pat1 = '<div id="plist".+<div class="page clearfix">' result1 = re.compile(pat1, re.DOTALL).findall(html1) #获取第一次筛选结果 result1 = result1[0] #*匹配0个或者多个前面表达式 #.匹配任意字符,加上re.dotall包括换行符 #+匹配1个或者多个前面表达式 #?非贪婪匹配,就是只匹配一组 #筛选出图片链接列表 pat2 = '//.+?/n7/.+?\.jpg' imagelist = re.compile(pat2).findall(result1) #x作为图片文件的顺序 x=1 for imageurl in imagelist: imagename = "C:/Users/Administrator/Desktop/jdphone_img/" + str(page) + str(x) + ".jpg" imageurl = "http:" + imageurl try: #保存图片 urllib.urlretrieve(imageurl, filename=imagename) except urllib2.URLError as e: #hasattr判断对象里面是否有name属性 if hasattr(e, "code"): x+=1 if hasattr(e, "reason"): x+=1 x+=1 for i in range(1, 3): url = "https://list.jd.com/list.html?cat=9987,653,655&page=" + str(i) craw(url, i)
注意:我这里只保存了第一二页的手机图片,在进行第二次筛选的时候正则表达式之所以会加了一个"?"进行非贪婪匹配,也就是一次只筛选出一张手机图片链接,如果不加这个非贪婪匹配那么我们会把第一个含有“//”到最后一个结尾含有.jpg之间的所有内容都会筛选出来,显示是不符合的,在这里建议可以把正则表达式的?去掉,然后看一下输出结果,去体会一下非贪婪匹配是怎么样的。
相关推荐
-
简单的抓取淘宝图片的Python爬虫
写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品. 从网页http://mm.taobao.com/json/request_top_list.htm?type=0&page=中提取taobao模特的照片. 复制代码 代码如下: # -*- coding: cp936 -*- import urllib2 import urllib mmurl="http://mm.taobao.com/json/request_top_list.htm?type
-
python抓取网页图片示例(python爬虫)
复制代码 代码如下: #-*- encoding: utf-8 -*-'''Created on 2014-4-24 @author: Leon Wong''' import urllib2import urllibimport reimport timeimport osimport uuid #获取二级页面urldef findUrl2(html): re1 = r'http://tuchong.com/\d+/\d+/|http://\w+(?<!photos).tuchong.co
-
Python爬虫实现网页信息抓取功能示例【URL与正则模块】
本文实例讲述了Python爬虫实现网页信息抓取功能.分享给大家供大家参考,具体如下: 首先实现关于网页解析.读取等操作我们要用到以下几个模块 import urllib import urllib2 import re 我们可以尝试一下用readline方法读某个网站,比如说百度 def test(): f=urllib.urlopen('http://www.baidu.com') while True: firstLine=f.readline() print firstLine 下面我们说
-
编写Python爬虫抓取暴走漫画上gif图片的实例分享
本文要介绍的爬虫是抓取暴走漫画上的GIF趣图,方便离线观看.爬虫用的是python3.3开发的,主要用到了urllib.request和BeautifulSoup模块. urllib模块提供了从万维网中获取数据的高层接口,当我们用urlopen()打开一个URL时,就相当于我们用Python内建的open()打开一个文件.但不同的是,前者接收一个URL作为参数,并且没有办法对打开的文件流进行seek操作(从底层的角度看,因为实际上操作的是socket,所以理所当然地没办法进行seek操作),而后
-

Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面.Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便- Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.整体架构如下图所示: 绿线是数据流向,首先从初始URL 开始,Scheduler 会将其
-
python爬虫实战之爬取京东商城实例教程
前言 本文主要介绍的是利用python爬取京东商城的方法,文中介绍的非常详细,下面话不多说了,来看看详细的介绍吧. 主要工具 scrapy BeautifulSoup requests 分析步骤 1.打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点 2.我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信
-
python制作爬虫爬取京东商品评论教程
本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化.下面是要抓取的商品信息,一款女士文胸.这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论. 京东商品评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论的信息.因此我们需要先找到存放商品评论信息的文件.这里我们使用Chrome浏览器里的开发者工具进行查找. 具体方法是在商品详情页点击鼠标右键,选择检查,在弹出的开发者工具界
-
python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo
-
Python爬虫实现爬取京东手机页面的图片(实例代码)
实例如下所示: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os from urllib.request import urlretrieve class Picture(): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleW
-
Python 3实战爬虫之爬取京东图书的图片详解
前言 最近工作中遇到一个需求,需要将京东上图书的图片下载下来,假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网络爬虫实现,这类爬虫称为图片爬虫,接下来,我们将实现该爬虫. 实现分析 首先,打开要爬取的第一个网页,这个网页将作为要爬取的起始页面.我们打开京东,选择图书分类,由于图书所有种类的图书有很多,我们选择爬取所有编程语言的图书图片吧,网址为:https://list.jd.com/list.html?cat=1713
-
Python爬虫实现抓取京东店铺信息及下载图片功能示例
本文实例讲述了Python爬虫实现抓取京东店铺信息及下载图片功能.分享给大家供大家参考,具体如下: 这个是抓取信息的 from bs4 import BeautifulSoup import requests url = 'https://list.tmall.com/search_product.htm?q=%CB%AE%BA%F8+%C9%D5%CB%AE&type=p&vmarket=&spm=875.7931836%2FA.a2227oh.d100&from=mal