python数据处理实战(必看篇)
一、运行环境
1、python版本 2.7.13 博客代码均是这个版本
2、系统环境:win7 64位系统
二、需求 对杂乱文本数据进行处理
部分数据截图如下,第一个字段是原字段,后面3个是清洗出的字段,从数据库中聚合字段观察,乍一看数据比较规律,类似(币种 金额 万元)这样,我想着用sql写条件判断,统一转换为‘万元人民币' 单位,用sql脚本进行字符串截取即可完成,但是后面发现数据并不规则,条件判断太多清洗质量也不一定,有的前面不是左括号,有的字段里面没有币种,有的数字并不是整数,有的没有万字,这样如果存储成数字和‘万元人民币'单位两个字段写sql脚本复杂了,mysql我也没找到能从文本中提取数字的函数,正则表达式常用于where条件中好像,如果谁知道mysql有类似从文本中过滤文本提取数字的函数,可以告诉我哈,这样就不用费这么多功夫,用kettle一个工具即可,工具活学活用最好。
结合用python的经验,python对字符串过滤有许多函数稍后代码中就是用了这样的办法去过滤文本。
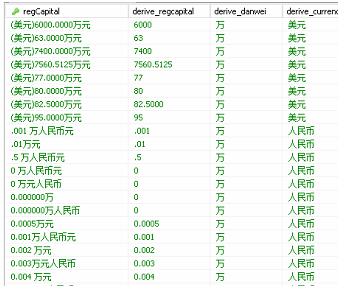
第一次部分清洗数据截图
三、对数据处理的宏观逻辑思考
拿到数据,先不要着急写代码,先思考清洗的逻辑,这点很关键,方向对了事半功倍,剩下的时间就是代码实现逻辑和调试代码的过程。
3.1思考过程 不写代码:
我想实现的最终的数据清洗是将资金字段换算成【金额+单位+各币种】的组合形式或者【金额+单位+统一的人民币币种】(币种进行汇率换算),分两步或者三步都可以
3.1.1拆分出三个字段,数字,单位,币种
(单元分为万和不含万,币种分为人民币和具体的外币)
3.1.2将单位统一换为万为单位
第一步中单位不是万的 数字部分/10000,是万的数字部分保持不变
3.1.3将币种统一为人民币
币种是人民币的前两个字段都不变,不是的数字部分变为数字*各外币兑换人民币的汇率,单位不变依旧是第二步统一的‘万'
3.2期望各步骤清洗效果 数据列举:
从这个结果着手我们步步拆解,先梳理 清洗逻辑部分
3.2.1第一次清洗期望效果 拆分出三个字段 数字 单位 币种:
①字段值=“2000元人民币”,第一次清洗
2000 不含万 人民币
②字段值=“2000万元人民币”,第一次清洗
2000 万 人民币
③字段值=“2000万元外币”, 第一次清洗
2000 万 外币
3.2.2第二次清洗期望效果 将单位 统一归为万:
#二次处理条件
case when 单位=‘万' then 金额 else 金额/10000 end as 第二次金额
①字段值=“2000元人民币”
0.2 万 人民币
②字段值=“2000万元人民币”
2000 万 人民币
③字段值=“2000万元外币”
2000 万 外币
注意:如果上面达到需求 则清洗完毕,如果想将单位换成人民币就进行下面三次清洗
3.2.3第三次清洗期望效果:单位 币种都统一为万+人民币
如果最后需求是换算成币种统一人民币,那么我们就在二次清洗后的基础上再写条件就好,
#三次处理条件
case when 币种=‘人民币' then 金额 else 金额*币种和人民币的换算汇率 end as 第三次金额
①字段值=“2000元人民币”
0.2 万 人民币
②字段值=“2000万元人民币”
2000 万 人民币
③字段值=“2000万元外币”
2000*外币兑换人民币汇率 万 人民币
四、对具体代码的宏观逻辑思考
币种和单位这两个就2种情况,很好写
4.1、币种部分
这个条件简单,如果币种的值在字符中出现就让新字段等于这个币种的值即可。
4.2、单位(万为单位)
这个条件也简单,万字出现在字符中 单位这个变量=‘万' 没出现就让单位变量等于‘不含万',这样写是为了方便下一步对数字进行二次处理的时候写条件判断了。
4.3、数字部分 确保清洗后和原值逻辑上一样 做些判断
确保清洗后和原值逻辑上一样意思是假如有这样字段300.0100万清洗后变成300.01 万 人民币 也是正确的。
filter(str.isdigit,字段的值)这个代码我首先知道可以将文本中数字取出,同过对字段group by 聚合以后知道有小数点的字段,取出的值不再带有小数点,如‘20.01万',filter(str.isdigit,‘20.01万')取出的数字就是2001,显然这个数字是不正确,因此就需要考虑有无小数点的情况,有小数点的做到和原字段一样
四、第一次清洗主要代码,先不读取数据库数据
从数据库中抽异常值10个左右做测试,info是regCapital字段的值
#带小数点的以小数点分割 取出小数点前后部分进行拼接
if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'
else:
derive_regcapital=filter(str.isdigit,info)
#单位 以万和不含万 为统一
if '万' in info:
derive_danwei='万'
else:
derive_danwei='不含万'
#币种 第一次清洗 外币保留外币字段 聚合大量数据 发现数据中含有外币的情况大致有下面这些情况 如果有新外币出现 进行数据的update操作即可
if '美元' in info:
derive_currency='美元'
elif '港币' in info:
derive_currency = '港币'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英镑' in info:
derive_currency = '英镑'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港币' in info:
derive_currency = '港币'
elif '法郎' in info:
derive_currency = '法郎'
elif '欧元' in info:
derive_currency = '欧元'
elif '新加坡' in info:
derive_currency = '新加坡元'
else:
derive_currency = '人民币'
五、全部代码:读取数据库数据 进行全量清洗
第四步我是将部分数据做了测试,验证代码无误,此时逻辑上应再从宏观上再拓展,将info变量动态变为数据库中所有的值,进行全量清洗
#coding:utf-8
from class_mysql import Mysql
project=Mysql('s_58infor_data',[],0,conn_type='local')
p2=Mysql('etl1_58infor_data',[],24,conn_type='local')
field_list=p2.select_fields(db='local_db',table='etl1_58infor_data')
print field_list
project2=Mysql('etl1_58infor_data',field_list=field_list,field_num=26,conn_type='local')
#以上部分 看不懂没关系 由于我有两套数据库环境,测试和生产
#不同的数据库连接和网段,因此要传递不同的参数进行切换数据库和数据连接 如果一套环境 连接一次数据库即可 数据处理需要经常做测试 方便自己调用
data_tuple=project.select(db='local_db',id=0)
#data_tuple 是我实例化自己写的操作数据库的类对数据库数据进行全字段进行读取,返回值是一个不可变的对象元组tuple,清洗需要保留旧表全部字段,同时增加3个清洗后的数据字段
data_tuple=project.select(db='local_db',id=0)
#遍历元组 用字典去存储每个字段的值 插入到增加3个清洗字段的表 etl1_58infor_data
for data in data_tuple:
item={}
#old_data不取最后一个字段 是因为那个字段我想用当前处理的时间
#这样可以计算数据总量运行的时间 来调整二次清洗的时间去和和kettle定时任务对接
#元组转换为列表 转换的原因是因为元组为不可变类型 如果有数据中有null值 遍历转换为字符串会报错
old_data=list(data[:-1])
if data[-2]:
if len(data[-2]) >0 :
info=data[-2].encode('utf-8')
else:
info=''
if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'
else:
derive_regcapital=filter(str.isdigit,info)
if '万' in info:
derive_danwei='万'
else:
derive_danwei='不含万'
if '美元' in info:
derive_currency='美元'
elif '港币' in info:
derive_currency = '港币'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英镑' in info:
derive_currency = '英镑'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港币' in info:
derive_currency = '港币'
elif '法郎' in info:
derive_currency = '法郎'
elif '欧元' in info:
derive_currency = '欧元'
elif '新加坡' in info:
derive_currency = '新加坡元'
else:
derive_currency = '人民币'
time_58infor_data = p2.create_time()
old_data.append(time_58infor_data)
old_data.append(derive_regcapital)
old_data.append(derive_danwei)
old_data.append(derive_currency)
#print len(old_data)
for i in range(len(old_data)):
if not old_data[i] :
old_data[i]=''
else:
pass
data2=old_data[i].replace('"','')
item[i+1]=data2
print item[1]
#插入测试环境 的表
project2.insert(item=item,db='local_db')
六、代码运行情况
6.1读取数据库原表数据和新表创建的字段

读取数据库原表数据和新表创建的字段
6.2 插入新表 并进行第一次数据清洗
红框部分为清洗部分,其他数据做了脱敏处理
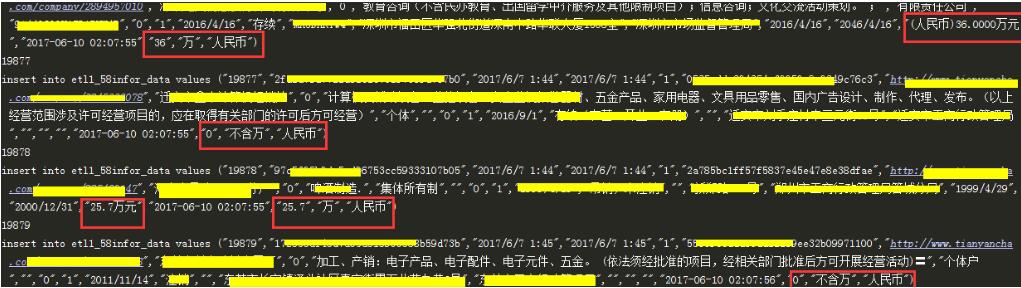
插入新表 并进行第一次数据清洗
6.3 数据表数据清洗结果
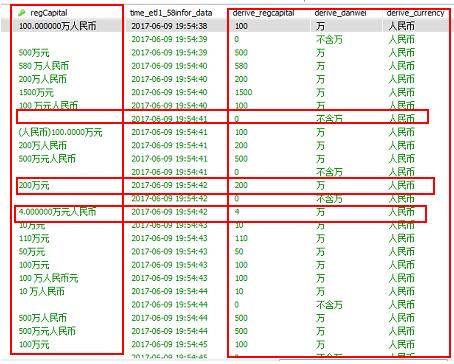
数据表数据清洗结果
七、增量数据处理
由于每天数据有增量进入,因此第一次执行完初始话之后,我们要根据表中的时间戳字段进行判断,读取昨日新的数据进行清洗插入,这部分留到下篇博客。
初步计划用下面函数 作为参数 判断增量 create_time 是爬虫脚本执行时候写入的时间,yesterday是昨日时间,在where条件里加以限制,取出昨天进入数据库的数据 进行执行 win7系统支持定时任务
import datetime
from datetime import datetime as dt
#%进行转义使用%%来转义
#主要构造sql中条件“where create_time like %s%%“ % yesterday
#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')
return create_time
def yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)
return yestoday
以上这篇python数据处理实战(必看篇)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

基于python爬虫数据处理(详解)
一.首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1.设置变量 set @变量名=值 set @address='中国-山东省-聊城市-莘县'; select @address 1.2 .length()函数 char_length()函数区别 select length('a') ,char_length('a') ,length('中') ,char_length('中') 1.3. replace() 函数
-
从零学python系列之数据处理编程实例(一)
要求:分别以james,julie,mikey,sarah四个学生的名字建立文本文件,分别存储各自的成绩,时间格式都精确为分秒,时间越短成绩越好,分别输出每个学生的无重复的前三个最好成绩,且分秒的分隔符要统一为"." 数据准备:分别建立四个文本文件 james.txt 2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22 julie.txt 2.59,2.11,2:11,2:23,3-10,2-23,3:10,3.21,3-21
-
Python 处理数据的实例详解
Python 处理数据的实例详解 最近用python(3.2的版本)写了根据特定规则,处理数据的一个小程序,用到了一些python常用的基础知识,在此总结一下: 1,python读文件 2,python写文件 3,python的流程控制 4,python的for循环 5,python的集合,或字符串里判断是否存在某个元素 6,python的逻辑或,逻辑与 7,python的正则过滤 8,python的字符串忽略空格,和以某个字符串开头和按某个字符拆分成list python的打开文件的模式: 关
-
python实现爬虫统计学校BBS男女比例之数据处理(三)
本文主要介绍了数据处理方面的内容,希望大家仔细阅读. 一.数据分析 得到了以下列字符串开头的文本数据,我们需要进行处理 二.回滚 我们需要对httperror的数据进行再处理 因为代码的原因,具体可见本系列文章(二),会导致文本里面同一个id连续出现几次httperror记录: //httperror265001_266001.txt 265002 httperror 265002 httperror 265002 httperror 265002 httperror 265003 httper
-
从零学python系列之数据处理编程实例(二)
在上一节从零学python系列之数据处理编程实例(一)的基础上数据发生了变化,文件中除了学生的成绩外,新增了学生姓名和出生年月的信息,因此将要成变成:分别根据姓名输出每个学生的无重复的前三个最好成绩和出生年月 数据准备:分别建立四个文本文件 james2.txt James Lee,2002-3-14,2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22 julie2.txt Julie Jones,2002-8-17,2.59,2.11
-
python数据处理实战(必看篇)
一.运行环境 1.python版本 2.7.13 博客代码均是这个版本 2.系统环境:win7 64位系统 二.需求 对杂乱文本数据进行处理 部分数据截图如下,第一个字段是原字段,后面3个是清洗出的字段,从数据库中聚合字段观察,乍一看数据比较规律,类似(币种 金额 万元)这样,我想着用sql写条件判断,统一转换为'万元人民币' 单位,用sql脚本进行字符串截取即可完成,但是后面发现数据并不规则,条件判断太多清洗质量也不一定,有的前面不是左括号,有的字段里面没有币种,有的数字并不是整数,有的没有万
-
新手如何快速入门Python(菜鸟必看篇)
学习任何一门语言都是从入门(1年左右),通过不间断练习达到熟练水准(3到5年),少数人最终能精通语言,成为执牛耳者,他们是金字塔的最顶层.虽然万事开头难,但好的开始是成功的一半,今天这篇文章就来谈谈如何开始入门Python.只要方向对了,就不怕路远. 设定目标 当你决定入门 Python 时,需要一个清晰且短期内可实现的目标,比如通过学习找一份初级程序员工作,目标明确后,你需要了解企业对初级程序员有哪些技能要求,下面是我从拉勾网找的一个初级 Python 工程师的任职要求: 1.熟悉 Pytho
-
老生常谈python的私有公有属性(必看篇)
python中,类内方法外的变量叫属性,类内方法内的变量叫字段.他们的私有公有访问方法类似. class C: __name="私有属性" def func(self): print(C.__name) class sub_C(C): def info(self): print(C.__name)#派生类中不可以访问父类的私有字段 obj=C() obj.func() obj=sub_C() obj.info() 方法.属性的访问于上述方式相似,即:私有成员只能在类内部使用 以上这篇老
-
初学python的操作难点总结(新手必看篇)
如下所示: 1 在cmd下 盘与盘之间的切换 直接 D或d: 就好 2 查找当前盘或者文件下面的目录 直接 dir 3 想在一个盘下进去一个文件夹,用cd空格目标文件 cd p 4 写文件的第一个字母后 按tab键自动补全 如果有多个p开头的则在按tab 会在所有之间切换 5 d:切盘 dir 查找目录 cd 进去目标文件(相当于双击) 6 往上走一层 cd .. 走两层 cd ../..(之间有无空格都行) 7 用python打开一个预先用记事本打好的txt 则先打开python f:\Dem
-
python常用知识梳理(必看篇)
接触python已有一段时间了,下面针对python基础知识的使用做一完整梳理: 1)避免'\n'等特殊字符的两种方式: a)利用转义字符'\' b)利用原始字符'r' print r'c:\now' 2)单行注释,使用一个#,如: #hello Python 多行注释,使用三个单引号(或三个双引号),如: '''hello python hello world''' 或 """hello python hello world""" 另外跨越多行
-
老生常谈python函数参数的区别(必看篇)
在运用python的过程中,发现当函数参数为list的时候,在函数内部调用list.append()会改变形参,与C/C++的不太一样,查阅相关资料,在这里记录一下. python中id可以获取对象的内存地址 >>> num1 = 10 >>> num2 = num1 >>> num3 = 10 >>> id(num1) >>> id(num2) >>> id(num3) 可以看到num1.num2
-
Python学习思维导图(必看篇)
无意间碰到的一个大神整理的Python学习思维导图,感觉对初学者理清学习思路大有裨益,非常感谢他的分享. 14 张思维导图 基础知识 数据类型 序列 字符串 列表 & 元组 字典 & 集合 条件 & 循环 文件对象 错误 & 异常 函数 模块 面向对象编程 以上这篇Python学习思维导图(必看篇)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Linux磁盘分区实战案例(必看篇)
一.查看新添加磁盘 [root@localhost /]# fdisk -l 磁盘 /dev/sda:53.7 GB, 53687091200 字节,104857600 个扇区 Units = 扇区 of 1 * 512 = 512 bytes 扇区大小(逻辑/物理):512 字节 / 512 字节 I/O 大小(最小/最佳):512 字节 / 512 字节 磁盘标签类型:dos 磁盘标识符:0x0009f1d1 设备 Boot Start End Blocks Id System /dev/s
-
python之virtualenv的简单使用方法(必看篇)
什么是virtualenv? virtualenv可以创建独立Python开发环境,比如当前的全局开发环境是python3.6,现在我们有一个项目需要使用django1.3,另一个项目需要使用django1.9,这个时候就可以使用virtualenv创建各自的python开发环境了. virtualenv的优点 使不同的应用开发环境独立 环境升级不影响其他的应用,也不会影响全局的python开发环境 它可以防止系统中出现包管理混乱和版本的冲突 安装和新建虚拟环境 cmd下输入:前提是你的pyth
-
浅谈django model的get和filter方法的区别(必看篇)
django的get和filter方法是django model常用到的,搞清楚两者的区别非常重要. 为了说明它们两者的区别定义2个models class Student(models.Model): name = models.CharField('姓名', max_length=20, default='') age = models.CharField('年龄', max_length=20, default='') class Book(models.Model): student =