python读取文本中数据并转化为DataFrame的实例
在技术问答中看到一个这样的问题,感觉相对比较常见,就单开一篇文章写下来。
从纯文本格式文件 “file_in”中读取数据,格式如下:

需要输出成“file_out”,格式如下:
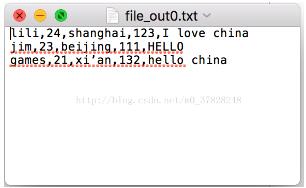
数据的原格式是“类别:内容”,以空行“\n”为分条目,转换后变成一个条目一行,按照类别顺序依次写出内容。
建议读取后,使用pandas,把数据建立称DataFrame的表格。这样方便以后处理数据。但是原格式并不是通常的表格格式,所以要先做一些简单的处理。
#coding:utf8
import sys
from pandas import DataFrame #DataFrame通常来装二维的表格
import pandas as pd #pandas是流行的做数据分析的包
#建立字典,键和值都从文件里读出来。键是nam,age……,值是lili,jim……
dict_data={}
#打开文件
with open('file_in.txt','r')as df:
#读每一行
for line in df:
#如果这行是换行符就跳过,这里用'\n'的长度来找空行
if line.count('\n') == len(line):
continue
#对每行清除前后空格(如果有的话),然后用":"分割
for kv in [line.strip().split(':')]:
#按照键,把值写进去
dict_data.setdefault(kv[0],[]).append(kv[1])
#print(dict_data)看看效果
#这是把键读出来成为一个列表
columnsname=list(dict_data.keys())
#建立一个DataFrame,列名即为键名,也就是nam,age……
frame = DataFrame(dict_data,columns=columnsname)
#把DataFrame输出到一个表,不要行名字和列名字
frame.to_csv('file_out0.txt',index=False,header=False)
以上这篇python读取文本中数据并转化为DataFrame的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python中datetime常用时间处理方法
- pandas中的DataFrame按指定顺序输出所有列的方法
- python DataFrame 修改列的顺序实例
- 在pandas中一次性删除dataframe的多个列方法
- python 处理dataframe中的时间字段方法
相关推荐
-
在pandas中一次性删除dataframe的多个列方法
之前沉迷于使用index删除,然而发现pandas貌似有bug? import pandas as pd import numpy as np df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A', 'B', 'C', 'D']) x=[1,2] df.drop(index=[1,2], axis=1, inplace=True) #axis=1,试图指定列,然并卵 print df 输出为 A B C D 0 0 1 2 3 还是
-
python 处理dataframe中的时间字段方法
在机器学习过程中,通常会通过pandas读取csv文件,保持成dadaframe格式,然而有时候需要对dataframe中的时间字段进行数据建模,比如时间格式为datetime,那么像一般操作dataframe的方式来操作时间字段会报错的,所以在使用sklearn库进行fit和predict的时候,通常要把时间字段首先转换为timestamp格式,在fit和predict之后,如果需要matplotlib绘图的时候,再把timestamp格式转换为时间字符串,比如2017-02-01 14:25
-
pandas中的DataFrame按指定顺序输出所有列的方法
问题: 输出新建的DataFrame对象时,DataFrame中各列的显示顺序和DataFrame定义中的顺序不一致. 例如: import pandas as pd grades = [48,99,75,80,42,80,72,68,36,78] df = pd.DataFrame( {'ID': ["x%d" % r for r in range(10)], 'Gender' : ['F', 'M', 'F', 'M', 'F', 'M', 'F', 'M', 'M', 'M'],
-
python DataFrame 修改列的顺序实例
假设我有一个DataFrame(df)如下: name age id mike 10 1 tony 14 2 lee 20 3 现在我想把id 放到最前面,变成: id name age df_id = df.id df = df.drop('id',axis=1) df.insert(0,'id',df_id) 以上这篇python DataFrame 修改列的顺序实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: Python中datet
-
Python中datetime常用时间处理方法
常用时间转换及处理函数: import datetime # 获取当前时间 d1 = datetime.datetime.now() print d1 # 当前时间加上半小时 d2 = d1 + datetime.timedelta(hours=0.5) print d2 # 格式化字符串输出 d3 = d2.strftime('%Y-%m-%d %H:%M:%S') print d3 # 将字符串转化为时间类型 d4 = datetime.datetime.strptime(date,'%Y-
-
python读取文本中数据并转化为DataFrame的实例
在技术问答中看到一个这样的问题,感觉相对比较常见,就单开一篇文章写下来. 从纯文本格式文件 "file_in"中读取数据,格式如下: 需要输出成"file_out",格式如下: 数据的原格式是"类别:内容",以空行"\n"为分条目,转换后变成一个条目一行,按照类别顺序依次写出内容. 建议读取后,使用pandas,把数据建立称DataFrame的表格.这样方便以后处理数据.但是原格式并不是通常的表格格式,所以要先做一些简单的处理
-
python读取文本中的坐标方法
利用python读取文本文件很方便,用到了string模块,下面用一个小例子演示读取文本中的坐标信息. import string x , y , z = [] , [] ,[] with open("test.txt") as A: for eachline in A: tmp = eachline.split() x.append(string.atof(tmp[0])) y.append(string.atof(tmp[1])) z.append(string.atof(tmp[
-
python 读取更新中的log 或其它文本方式
在项目中遇到这个问题,想把本地的log文件通过 Server-Send Event 的形式 发送给前端. 但是如何把那些 新增加log文本 读取出来就成了问题. 想过遍历log文件取得行数,读取最后几行文件,这种方式,不过缺点也很明显,log 文件很有可能会重复.因此在网上看了些介绍,也查了些资料,整理了如下代码. start_point=0 def read_logs(): fo = open("heakth_info.log", "rb") # 一定要用'rb'
-
python 读取txt中每行数据,并且保存到excel中的实例
使用xlwt读取txt文件内容,并且写入到excel中,代码如下,已经加了注释. 代码简单,具体代码如下: # coding=utf-8 ''' main function:主要实现把txt中的每行数据写入到excel中 ''' ################# #第一次执行的代码 import xlwt #写入文件 import xlrd #打开excel文件 fopen=open("e:\\a\\bb\\a.txt",'r') lines=fopen.readlines() #新
-

python读取word 中指定位置的表格及表格数据
1.Word文档如下: 2.代码 # -*- coding: UTF-8 -*- from docx import Document def readSpecTable(filename, specText): document = Document(filename) paragraphs = document.paragraphs allTables = document.tables specText = specText.encode('utf-8').decode('utf-8') f
-
使用 Python 读取电子表格中的数据实例详解
Python 是最流行.功能最强大的编程语言之一.由于它是自由开源的,因此每个人都可以使用.大多数 Fedora 系统都已安装了该语言.Python 可用于多种任务,其中包括处理逗号分隔值(CSV)数据.CSV文件一开始往往是以表格或电子表格的形式出现.本文介绍了如何在 Python 3 中处理 CSV 数据. CSV 数据正如其名.CSV 文件按行放置数据,数值之间用逗号分隔.每行由相同的字段定义.简短的 CSV 文件通常易于阅读和理解.但是较长的数据文件或具有更多字段的数据文件可能很难用肉眼
-
利用Python第三方库xlrd读取Excel中数据实例代码
目录 1. 安装 xlrd 库 2. 使用 xlrd 库 2.1 打开 Excel 工作表对象 2.2 读取单个单元格数据 2.3 读取多个单元格数据 2.3 读取所有单元格数据 附:行.列操作 3. 总结 1. 安装 xlrd 库 Python 读取 Excel 中的数据主要用到 xlrd 第三方库.xlrd 其实就是两个单词的简化拼接,我们可以把它拆开来看,xl 代表 excel, rd 代表 read, 合并起来就是 xlrd, 意思就是读 excel 的第三方库. 这种命名风格也正是我们
-
python读取文本绘制动态速度曲线
本文实例为大家分享了python读取文本绘制动态速度曲线的具体代码,供大家参考,具体内容如下 由于需要分析机械加工过程中各个轴的速度,于是用软件导出了数据,写了这个python脚本来显示速度曲线. 效果图如下: 源代码: import numpy as np from matplotlib import pyplot as plt from matplotlib import animation path = "Nccut_TraceFile.log" file = open(path
-
Python判断文本中消息重复次数的方法
本文实例讲述了Python判断文本中消息重复次数的方法.分享给大家供大家参考,具体如下: #coding:gbk ''' Created on 2012-2-3 从文件中读取文本,并判断文本中形如"message0"."message123"这样的消息有多少条是重复的 @author: Administrator ''' import re if __name__ == '__main__': pattern = u"(message((\d)+))&qu
-
python 读取.csv文件数据到数组(矩阵)的实例讲解
利用numpy库 (缺点:有缺失值就无法读取) 读: import numpy my_matrix = numpy.loadtxt(open("1.csv","rb"),delimiter=",",skiprows=0) 写: numpy.savetxt('2.csv', my_matrix, delimiter = ',') 可能遇到的问题: SyntaxError: (unicode error) 'unicodeescape' codec