如何制作一个Node命令行图像识别工具
从 0 开始制作一个 NodeJS 命令行验证码识别工具。实现如下效果。
初始化项目
# 创建 recognition 项目 mkdir recognition cd recognition npm init -y # 安装主依赖 yarn add images tesseract.js # 安装工具依赖 yarn add chalk yargs # 可选依赖 yarn add socks5-http-client
依赖说明
images:Node.js 轻量级跨平台图像编码库,用于处理下载下来的图片
tesseract.js :纯 JS 实现的 OCR(光学字符识别)工具,用于图像内容识别
chalk:让命令行内容样式好看
yargs:命令行参数解析器
socks5-http-client:SOCKS v5,用于设置代理,在需要拉取某些不能直接访问的资源时使用, request proxy 例子
项目准备
新建 cli.js
通常命令行工具入口名字为 cli.js ,我们新建一个 cli.js 文件,并在开头写上:
#!/usr/bin/env node
这样,我们告诉 *nix 系统,JavaScript 文件的解释器应该是 /usr/bin/env node ,它查找本地安装的 node 。
配置 bin
// package.json
{
"bin": {
"reg": "./cli.js"
}
}
这样配置完成后,别人 npm install -g @chenng/recognition 的包,就可以直接通过命令行运行了:
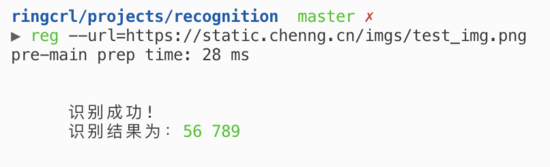
reg --url=https://static.chenng.cn/imgs/test_img.png
link 本地开发
我们如何能够在本地可以使用 rec 命令呢?只需要把本项目 link 即可:
yarn link
核心逻辑
主要逻辑在 cli.js 和 recognize.js 中。这里有几个注意点:
- request 图片的时候要设置
encoding: null,否则返回的是乱码 - 初次使用的时候需要下载训练集,需要花点时间
const Tesseract = require('tesseract.js');
const images = require('images');
const requset = require('request');
const fs = require('fs');
const { promisify } = require('util');
const chalk = require('chalk');
const writeFile = promisify(fs.writeFile);
const rp = promisify(requset);
class Recognize {
constructor(url) {
Recognize.downloadDir = `${__dirname}/dist/`;
Recognize.downloadFile = `${__dirname}/dist/temp.png`;
this.url = url;
this.start();
}
async start() {
const data = await this.downloadImg();
await writeFile(Recognize.downloadFile, data);
this.recognize();
const result = await Tesseract.recognize(Recognize.downloadFile, {
lang: 'eng',
tessedit_char_blacklist: 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ',
});
console.log(`
识别成功!
识别结果为:${chalk.green(result.text)}
`);
}
async downloadImg() {
if (!fs.existsSync(Recognize.downloadDir)) {
fs.mkdirSync(Recognize.downloadDir);
console.log(`创建了 ${Recognize.downloadDir} 文件夹`);
}
const res = await rp({
url: this.url,
method: 'GET',
encoding: null,
});
return res.body;
}
recognize() {
// 放大图片,并覆盖源文件
images(Recognize.downloadFile)
.size(400)
.save(Recognize.downloadFile);
}
}
module.exports = Recognize;
具体可以查看源码仓库: https://github.com/ringcrl/recognition
发布上线
# 新建代码仓库,git push # 登录到 npm npm adduser # 发包 npm publish --access public # 全局安装 npm install -g @chenng/recognition
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
JAVA演示阿里云图像识别API,印刷文字识别-营业执照识别
最近有由于需要,我开始接触阿里云的云市场的印刷文字识别-营业执照识别这里我加上了官网的申请说明,只要你有阿里云账号就可以用,前500次是免费的,API说明很简陋,只能做个简单参考. 一.API介绍 JAVA示例: public static void main(String[] args) { String host = "https://dm-58.data.aliyun.com"; String path = "/rest/160601/ocr/ocr_business_
-

iOS通过摄像头图像识别技术分享
目前的计算机图像识别,透过现象看本质,主要分为两大类: 1.基于规则运算的图像识别,例如颜色形状等模板匹配方法 2.基于统计的图像识别.例如机器学习ML,神经网络等人工智能方法 **区别:**模板匹配方法适合固定的场景或物体识别,机器学习方法适合大量具有共同特征的场景或物体识别. **对比:**无论从识别率,准确度,还是适应多变场景变换来讲,机器学习ML都是优于模板匹配方法的:前提你有大量的数据来训练分类器.如果是仅仅是识别特定场景.物体或者形状,使用模板匹配方法更简单更易于实现. **目标:*
-
Node Puppeteer图像识别实现百度指数爬虫的示例
之前看过一篇脑洞大开的文章,介绍了各个大厂的前端反爬虫技巧,但也正如此文所说,没有100%的反爬虫方法,本文介绍一种简单的方法,来绕过所有这些前端反爬虫手段. 下面的代码以百度指数为例,代码已经封装成一个百度指数爬虫node库: https://github.com/Coffcer/baidu-index-spider note: 请勿滥用爬虫给他人添麻烦 百度指数的反爬虫策略 观察百度指数的界面,指数数据是一个趋势图,当鼠标悬浮在某一天的时候,会触发两个请求,将结果显示在悬浮框里面: 按照常规
-
python实现图像识别功能
本文实例为大家分享了python实现图像识别的具体代码,供大家参考,具体内容如下 #! /usr/bin/env python from PIL import Image import pytesseract url='img/denggao.jpeg' image=Image.open(url) #image=image.convert('RGB') # RGB image=image.convert('L') # 灰度 image.load() text=pytesseract.image_
-
用Python进行简单图像识别(验证码)
这是一个最简单的图像识别,将图片加载后直接利用Python的一个识别引擎进行识别 将图片中的数字通过 pytesseract.image_to_string(image)识别后将结果存入到本地的txt文件中 #-*-encoding:utf-8-*- import pytesseract from PIL import Image class GetImageDate(object): def m(self): image = Image.open(u"C:\\a.png") text
-
python自动截取需要区域,进行图像识别的方法
实例如下所示: import os os.chdir("G:\Python1\Lib\site-packages\pytesser") from pytesser import * from pytesseract import image_to_string from PIL import Image from PIL import ImageGrab #截图,获取需要识别的区域 x = 345 y = 281 m = 462 n = 327 k = 54 for i in rang
-
PHP图像识别技术原理与实现
其实图像识别技术与我们平时做的密码验证之类的没有什么区别,都是事先把要校验的数据入库,然后使用时将录入(识别)的数据与库中的数据做对比,只不过图像识别技术有一部分的容错性,而我们平时的密码验证是要100%匹配. 前几天,有朋友谈到做游戏点击抽奖,识别图片中的文字,当时立马想到的就是js控制或者flash做遮罩层,感觉这种办法是最方便快捷效果好,而且节省服务器资源,但是那边提的要求竟然是通过php识别图像中的文字. 赶巧那两天的新闻有:1.马云人脸识别支付:2.12306使用新的验证码,说什么现在
-
微信跳一跳python辅助软件思路及图像识别源码解析
本文将梳理github上最火的wechat_jump_game的实现思路,并解析其图像处理部分源码 首先废话少说先看效果 核心思想 获取棋子到下一个方块的中心点的距离 计算触摸屏幕的时间 点击屏幕 重要方法 计算棋子到下一个方块中心点的距离 使用 adb shell screencap -p 命令获取手机当前屏幕画面 再通过图像上的信息找出棋子的坐标和下一个方块中心点的坐标 然后通过两点间距离公式计算出距离 计算触摸屏幕的时间 T=A * S 其中S为上步算出的像素距离,T为按压时间(ms),A
-
基于MATLAB神经网络图像识别的高识别率代码
MATLAB神经网络图像识别高识别率代码 I0=pretreatment(imread('Z:\data\PictureData\TestCode\SplitDataTest\0 (1).png')); I1=pretreatment(imread('Z:\data\PictureData\TestCode\SplitDataTest\1 (1).png')); I2=pretreatment(imread('Z:\data\PictureData\TestCode\SplitDataTest\
-
python实现识别手写数字 python图像识别算法
写在前面 这一段的内容可以说是最难的一部分之一了,因为是识别图像,所以涉及到的算法会相比之前的来说比较困难,所以我尽量会讲得清楚一点. 而且因为在编写的过程中,把前面的一些逻辑也修改了一些,将其变得更完善了,所以一切以本篇的为准.当然,如果想要直接看代码,代码全部放在我的GitHub中,所以这篇文章主要负责讲解,如需代码请自行前往GitHub. 本次大纲 上一次写到了数据库的建立,我们能够实时的将更新的训练图片存入CSV文件中.所以这次继续往下走,该轮到识别图片的内容了. 首先我们需要从文件夹中
-
C#图像识别 微信跳一跳机器人
更新 GitHub中所有类库的源码已经转换为C#版本. 准备 IDE:VisualStudio Language:C#/VB.NET GitHub:AutoJump.NET 本文将向你介绍一种通过图像识别实现"跳一跳"机器人的方法. 第一节 图像识别 文中提到的所有方法和步骤只涉及简单的向量计算. 需要用到哪些计算? 比较像素点的颜色 求向量集合的中心 计算颜色的相似度 一个RGB颜色可以看作一个三维向量 比较两个颜色的相似度可以计算它们的欧几里得距离 也可以直接比较它们的夹角:夹角越