C++计数排序详解
计数排序不同于比较排序,是基于计数的方式,对于计数排序,假设每一个输入都是介于0~k之间的整数。对于每一个输入元素x,确定出小于x的元素的个数。假如有17个元素小于x,则x就属于第18个输出位置。
计数排序涉及到三个数组A[0…..length-1],length为数组A的长度;数组B与数组A长度相等,存放最终排序的结果;C[0…..K]存放A中每个元素的个数,k为数组A中的最大值。
int count_k(int A[],int length),此函数为了确定数组A中最大的元素,用来确定C数组的长度。
int count_k(int A[],int length)
{
int j,max;
max = A[0];
for(j=1;j<=length-1;j++)
{
if(A[j]>=max)
max = A[j];
}
return max;
}
计数排序的实现:
void count_sort(int A[],int B[],int k)
{
int *C = (int *)malloc((k+1) * sizeof(int));
int i,j;
for(i=0;i<=k;i++)//初始化数组C
C[i]=0;
for(j=0;j<=length-1;j++)//计算A中元素的个数
C[A[j]] = C[A[j]]+1;
for(i=1;i<=k;i++)//计算小于等于C[i]的元素的个数
C[i] = C[i] + C[i-1];
for(j=length-1;j>=0;j--)
{
int k=C[A[j]]-1;
B[k] = A[j];
C[A[j]] = C[A[j]] - 1;
}
free(C);
}
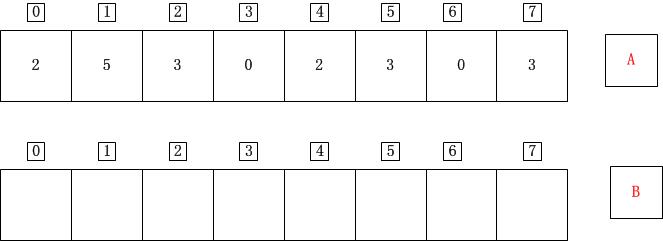
count_sort(A,B,k);
k=5
for(j=0;j<=length-1;j++)//计算A中元素的个数 C[A[j]] = C[A[j]]+1;
表示数组A中有2个0、0个1、2个2、3个3、0个4、1个5
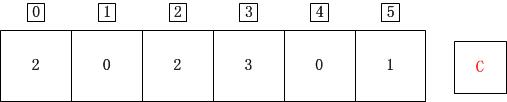
for(i=1;i<=k;i++)//计算小于等于C[i]的元素的个数 C[i] = C[i] + C[i-1];
小于等于0的数有两个,小于等于1的数有两个、小于等于2的数有4个、小于等于3的有7个、小于等于4的有7个、小于等于5的有8个
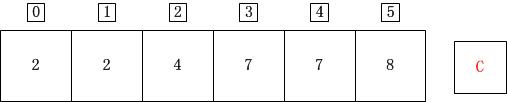
for(j=length-1;j>=0;j--)
{
int k=C[A[j]]-1;
B[k] = A[j];
C[A[j]] = C[A[j]] - 1;
}
for循环分析如下
j=7;A[j]=A[7]=3;C[A[j]]=C[3]=7;C[A[j]]-1=6;B[C[A[j]]-1]=B[6]=A[j]=3;C[A[j]]=C[A[j]]-1=6
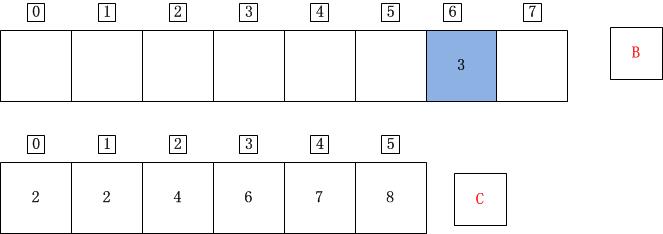
j=6;A[j]=A[6]=0;C[A[j]]=C[0]=2;C[A[j]]-1=1;B[C[A[j]]-1]=B[1]=A[j]=0;C[A[j]]=C[A[j]]-1=1
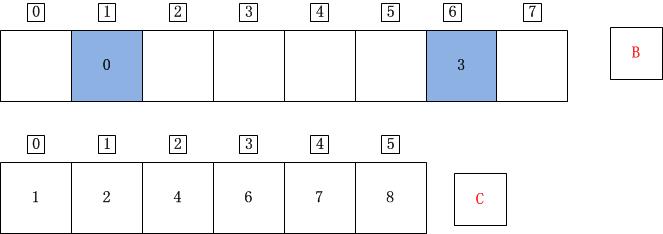
j=5;A[j]=A[5]=3;C[A[j]]=C[3]=6;C[A[j]]-1=5;B[C[A[j]]-1]=B[5]=A[j]=3;C[A[j]]=C[A[j]]-1=5;
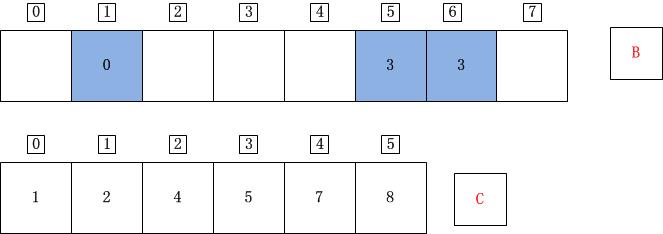
j=4;A[j]=A[4]=2;C[A[j]]=C[2]=4;C[A[j]]-1=3;B[C[A[j]]-1]=B[3]=A[j]=2;C[A[j]]=C[A[j]]-1=3;
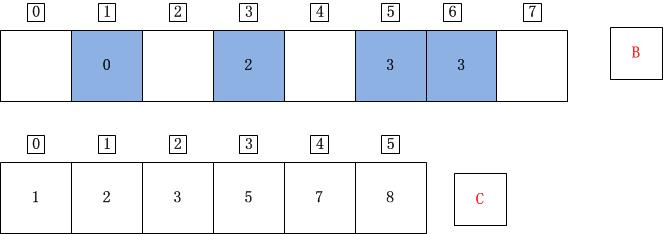
j=3;A[j]=A[3]=0;C[A[j]]=C[0]=1;C[A[j]]-1=0;B[C[A[j]]-1]=B[0]=A[j]=0;C[A[j]]=C[A[j]]-1=0;
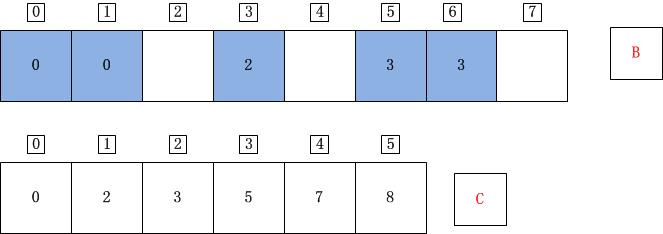
j=2;A[j]=A[2]=3;C[A[j]]=C[3]=5;C[A[j]]-1=4;B[C[A[j]]-1]=B[4]=A[j]=3;C[A[j]]=C[A[j]]-1=4;
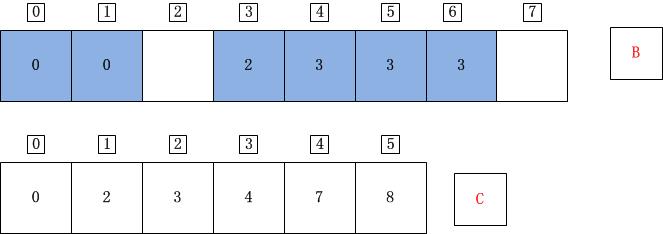
j=1;A[j]=A[1]=5;C[A[j]]=C[5]=8;C[A[j]]-1=7;B[C[A[j]]-1]=B[7]=A[j]=5;C[A[j]]=C[A[j]]-1=7;
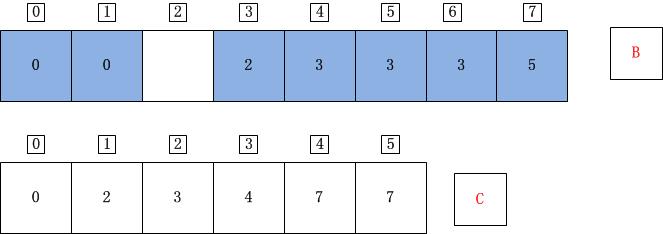
j=0;A[j]=A[0]=2;C[A[j]]=C[2]=3;C[A[j]]-1=2;B[C[A[j]]-1]=B[2]=A[j]=2;C[A[j]]=C[A[j]]-1=2;
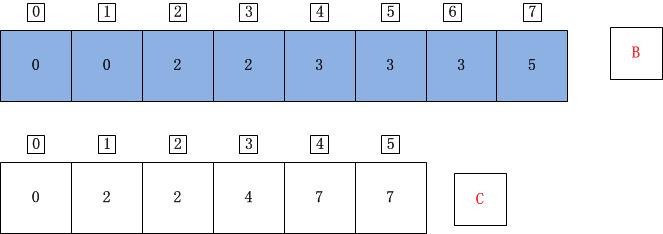
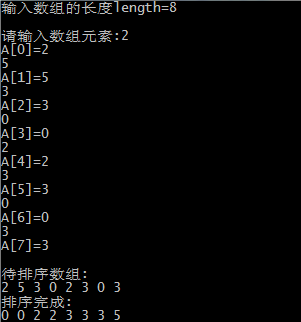
计数排序的最后运行截图
计数排序分析:j=length-1;j>=0;j–此处为倒序,是为了保证排序的稳定性,这个在基数排序中有重要的作用。
相关推荐
-

C++ 计数排序实例详解
计数排序 计数排序是一种非比较的排序算法 优势: 计数排序在对于一定范围内的整数排序时,时间复杂度为O(N+K) (K为整数在范围)快于任何比较排序算法,因为基于比较的排序时间复杂度在理论上的上下限是O(N*log(N)). 缺点: 计数排序是一种牺牲空间换取时间的做法,并且当K足够大时O(K)>O(N*log(N)),效率反而不如比较的排序算法.并且只能用于对无符号整形排序. 时间复杂度: O(N) K足够大时为O(K) 空间复杂度: O(最大数-最小数) 性能: 计数排序是一种稳定排序
-
C++计数排序详解
计数排序不同于比较排序,是基于计数的方式,对于计数排序,假设每一个输入都是介于0~k之间的整数.对于每一个输入元素x,确定出小于x的元素的个数.假如有17个元素小于x,则x就属于第18个输出位置. 计数排序涉及到三个数组A[0-..length-1],length为数组A的长度:数组B与数组A长度相等,存放最终排序的结果:C[0-..K]存放A中每个元素的个数,k为数组A中的最大值. int count_k(int A[],int length),此函数为了确定数组A中最大的元素,用来确定C数组
-
JAVA十大排序算法之计数排序详解
目录 计数排序 问题 代码实现 时间复杂度 算法稳定性 总结 计数排序 一种非比较排序.计数排序对一定范围内的整数排序时候的速度非常快,一般快于其他排序算法.但计数排序局限性比较大,只限于对整数进行排序,而且待排序元素值分布较连续.跨度小的情况. 如果一个数组里所有元素都是整数,而且都在0-k以内.对于数组里每个元素来说,如果能知道数组里有多少项小于或等于该元素,就能准确地给出该元素在排序后的数组的位置. 如给定一个0~5范围内的数组[2,5,3,0,2,3,0,3],对于元素5为其中最大的元素
-
Java并发编程Semaphore计数信号量详解
Semaphore 是一个计数信号量,它的本质是一个共享锁.信号量维护了一个信号量许可集.线程可以通过调用acquire()来获取信号量的许可:当信号量中有可用的许可时,线程能获取该许可:否则线程必须等待,直到有可用的许可为止. 线程可以通过release()来释放它所持有的信号量许可(用完信号量之后必须释放,不然其他线程可能会无法获取信号量). 简单示例: package me.socketthread; import java.util.concurrent.ExecutorService;
-
MySQL对中文进行排序详解及实例
MySQL对中文进行排序详解 MySQL默认只支持对日期.时间和英文字符串进行排序,如果对中文进行order by很可能得不到想要的结果,如下面的查询并不会按我们所想的根据汉字的拼音进行排序: SELECT * from user order by user_name; 如果相对中文进行排序的话,可以使用CONVERT(coloum_name USING GBK)将中文转为GBK编码形式,然后再排序,就可以实现根据汉子的拼音进行排序: SELECT * from user order by CO
-
Linux中du-查看文件夹大小并按大小进行排序详解
Linux中du-查看文件夹大小并按大小进行排序详解 某天,我想检查一下电脑硬盘的的使用情况,作为一个命令控,废话少说,开始吧: 使用df 命令查看当前磁盘使用情况: jack@jiaobuchong:~$ df -lh Filesystem Size Used Avail Use% Mounted on /dev/sda3 18G 5.7G 11G 35% / udev 2.7G 4.0K 2.7G 1% /dev tmpfs 553M 916K 552M 1% /run none 5.0M
-
C++冒泡排序与选择排序详解
目录 一.冒泡排序 1.概念 2.图解 3.代码的思路 4.代码例子 二.选择排序 1.概念 2.图解 3.代码的思路 总结 一.冒泡排序 1.概念 冒泡排序这种排序方法其实关键词就在于冒泡两个字,顾名思义就是数字不断比较然后最大的突出来,也就是说把相邻的两个数字两两比较,当一个数字大于右侧相邻的数字时,交换他们的位置,当一个数字和他右侧的数字小于或等于的时候,不交换. 2.图解 关于冒泡排序我自己画了一幅图来描述他的一轮过程 这里我举了五个无序的数{7,3,6,5,4} 由此可看出
-
java 集合工具类Collections及Comparable和Comparator排序详解
目录 一.常用功能 二.Comparator比较器 三.Comparable和Comparator两个接口的区别 四.练习 五.扩展 一.常用功能 java.utils.Collections是集合工具类,用来对集合进行操作. 部分方法如下: public static <T> boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素. public static void shuffle(List<?> lis
-
Java数据结构之有向图的拓扑排序详解
目录 前言 拓扑排序介绍 检测有向图中的环 实现思路 API设计 代码实现 基于深度优先的顶点排序 实现思路 API设计 代码实现 拓扑排序 API设计 代码实现 测试验证 前言 在现实生活中,我们经常会同一时间接到很多任务去完成,但是这些任务的完成是有先后次序的.以我们学习java 学科为例,我们需要学习很多知识,但是这些知识在学习的过程中是需要按照先后次序来完成的.从java基础,到 jsp/servlet,到ssm,到springboot等是个循序渐进且有依赖的过程.在学习jsp前要首先掌
-
C++ 算法之希尔排序详解及实例
C++ 算法之希尔排序算法详解及实例 希尔排序算法 定义: 希尔排序是插入排序的一种,也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本. 算法思想: 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序,随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰好被分为一组,算法终止. 时间复杂度: O(N) 空间复杂度: O(1) 性能: 希尔排序为不稳定算法(一次插入排序是稳定的,不会改变相同元素的相对顺序,但是在不同的插入排序中,相同的元素可能在各自的
-
JAVA十大排序算法之桶排序详解
目录 桶排序 代码实现 时间复杂度 算法稳定性 总结 桶排序 桶排序是计数排序的升级,计数排序可以看成每个桶只存储相同元素,而桶排序每个桶存储一定范围的元素,通过函数的某种映射关系,将待排序数组中的元素映射到各个对应的桶中,对每个桶中的元素进行排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序),最后将非空桶中的元素逐个放入原序列中. 桶排序需要尽量保证元素分散均匀,否则当所有数据集中在同一个桶中时,桶排序失效. 代码实现 1.找出数组中的最大值max和最小值min,可以确定出数组所在范