python 制作python包,封装成可用模块教程
首先编写py程序:
printtest.py
def test():
print('print test')
将以上.py文件做成python模块,需要在相同目录下创建setup.py文件,setup.py中输入配置信息:
from setuptools import setup setup(name='printtest', version='1.0', py_modules=['printtest'], )
打开终端,定位到该文件夹下,输入:
python setup.py sdist
此时在目录中生成dist文件夹,文件夹中有testpg-1.0.tar.gz文件,用户安装的话只需要testpg-1.0.tar.gz文件即可。将此文件解压得到testpg-1.0文件夹,会发现该文件夹有我们刚刚书写的3个py文件,还有一个PKG-INFO,打开该文件,会显示该模块的具体信息:由于我们没有设置,所以为UNKOWN
Metadata-Version: 1.0
Name: printtest
Version: 1.0
Summary: UNKNOWN
Home-page: UNKNOWN
Author: UNKNOWN
Author-email: UNKNOWN
License: UNKNOWN
Description: UNKNOWN
Platform: UNKNOWN
终端定位到此文件夹下,输入以下命令,模块将会被安装到解释器对应的Lib/site-packages目录下:
python setup.py install
安装后,会发现Lib/site-packages目录下存在printtest.py文件和printtest-1.0-py3.6.egg-info
应用:
import printtest
printtest.test()
输出:
print test
补充知识:python 将自定义常用的一些函数封装成可以直接调用的模块方法
将常用一些的函数封装成可以直接调用的模块方法
1. 背景
在实际的操作过程中,经常会用到一个功能,如果每次编写代码的时候都进行重新编写或者打开已经编写好的函数进行复制粘贴,这样就显得很麻烦,有没有什么方法可以像导入python模块的那样,直接把要用的函数以模块名+方法的形式调用呢?
答案当然是可以的,比如做数据分析时候经常要使用的功能是:实现某一路径下的所有xlsx的合并,文件如下
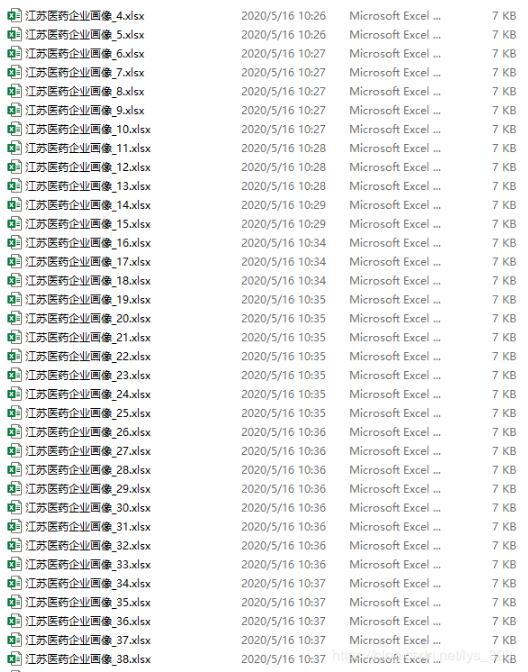
直接给出合并的函数,保留数据格式筛选的接口,将合并后的数据保存在fltered_data文件夹下的data_ok.xlsx文件中
def concat_excels(pattern):
import pandas as pd
import os
import glob
if not os.path.exists('filtered_data'):
os.mkdir('filtered_data')
file_paths = glob.glob(pattern)
df = pd.DataFrame()
for file_path in file_paths:
df_ = pd.read_excel(file_path)
df = pd.concat([df,df_])
df.to_excel('filtered_data/data_ok.xlsx',index = False)
print('Finished!')
if __name__ == '__main__':
concat_excels('*.xlsx')
2. 具体步骤
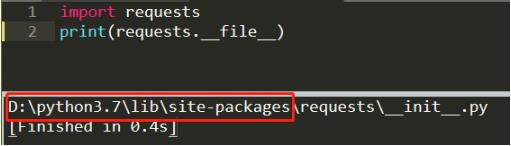
第一步:首先找到当前编辑器(可能会存在多个python解析器)对应的第三方库的安装路径,如果不知道具体的位置,可以在使用的编辑器窗口输入如下代码,这里以requests库为例,查看一下第三方库的文件位置,红色标记的即是
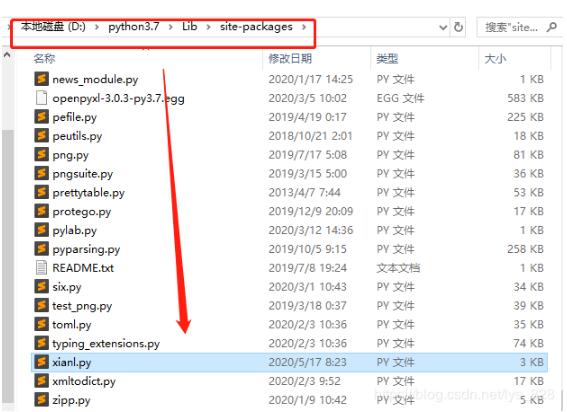
第二步:将上面的函数所在py文件命名,可以以自己名字的简称进行命名,即方便导入也方便自己记住。然后将保存好的py文件移动到上面的红色标记下,如下图
第三步:在欲合并的文件夹下创建一个py文件(比如命名为:合并数据.py),如下

第四步:编辑代码,直接导入模块和方法完成文件数据的合并,代码运行截图如下,这样就是实现了多文件的合并,括号中保留了合并数据的筛选格式,方便进行之后不同格式的Excel文件的合并
from 模块名 import * 意思是导入该模块的所有的方法(可以直接调用函数)
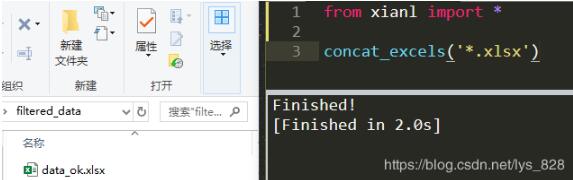
3. 扩展
通过这种方式,就可以把我们在日常工作中经常使用的方法(要实现的功能)都放置在以自己命名的py文件中,使用的时候直接就可以调用非常简单,如果需要添加,就打开这个py文件,把代码复制粘贴进去就可以了。
比如在处理图像时候,可以直接把图片的读取过程中色彩的矫正和图片的显示封装成函数,在使用的时候一行代码就可以实现之前繁杂的程序

使用演示:

以上这篇python 制作python包,封装成可用模块教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python打包模块wheel的使用方法与将python包发布到PyPI的方法详解
wheel文件 Wheel和Egg都是python的打包格式,目的是支持不需要编译或制作的安装过程,实际上也是一种压缩文件,将.whl的后缀改为.zip即可可看到压缩包里面的内容.按照官网说法,wheels是发行版Python的新标准并且要取代.egg. Egg格式是由setuptools在2004年引入,而Wheel格式是由PEP427在2012年定义. Wheel现在被认为是Python的二进制包的标准格式. 以下是Wheel和Egg的主要的不同点: Wheel有一个官方的PEP427来定义
-
Python实现封装打包自己写的代码,被python import
1.新建一个文件夹example,里面放入要打包的.py文件,以及必需的_init_.py. 代码如下: # -*- coding: utf-8 -*- """ Created on Thu Nov 1 17:04:02 2018 @author: Jo """ #!/usr/bin/env python #-*- coding:utf-8 -*- def run(): print ('This is a run package!') if __
-
打包发布Python模块的方法详解
前言 昨天把自己的VASP文件处理库进行了打包并上传到PyPI,现在可以直接通过pip和easy_install来安装VASPy啦(同时欢迎使用VASP做计算化学的童鞋们加星和参与进来), VASPy的GotHub地址:https://github.com/PytLab/VASPy VASPy的PyPI地址:https://pypi.python.org/pypi/vaspy/ 由于自己的记性真是不咋地,怕时间久了就忘了,于是在这里趁热打铁以自己的VASPy程序为例对python的打包和上传进行
-
Python模块的制作方法实例分析
本文实例讲述了Python模块的制作方法.分享给大家供大家参考,具体如下: 1 目的 利用setup.py将框架安装到python环境中,作为第三方模块来调用, 2 第一步:完成setup.py的编写 以下代码相当于一个模板,只用更改name字段出,改为对应的需要安装的模块名称就可以,比如这里是:py_plus 将setup.py文件放到py_plus的同级目录下 from os.path import dirname, join # from pip.req import parse_requ
-
python 制作python包,封装成可用模块教程
首先编写py程序: printtest.py def test(): print('print test') 将以上.py文件做成python模块,需要在相同目录下创建setup.py文件,setup.py中输入配置信息: from setuptools import setup setup(name='printtest', version='1.0', py_modules=['printtest'], ) 打开终端,定位到该文件夹下,输入: python setup.py sdist 此时
-
python将logging模块封装成单独模块并实现动态切换Level方式
查找了很多资料,但网上给出的教程都是大同小异的,而我想将代码进一步精简,解耦,想实现如下两个目标 1. 将logging模块的初始化,配置,设置等代码封装到一个模块中: 2. 能根据配置切换logging.level, 网上给出的教程都是写死的,如果我在线上之前使用了logging.info(msg),现在想切换为logging.debug(msg)怎么办?需要能够根据配置文件中的 设置配置logging.level 两个文件: logging_class:将logging模块的初始化,配置,设
-
python 制作自定义包并安装到系统目录的方法
python 中的包的概念跟c++中的namespace很相似,在大型的工程开发中,多个开发人员很容使用相同的函数名,为了避免相同函数名带来的问题,就引入了包的概念. 在看别人写的程序中经常看到形如"from xx import yy"xx就是包 制作一个本地使用的包 建立一个文件夹并命名为dl,文件夹名"dl"就是我们的包名,在文件夹内部新建一个"__init__.py"(注意init左右两边都是两个底线符号),在文件夹下添加自己的模块即可,代
-
Python的os包与os.path模块的用法详情
目录 一.os常用方法 1.获取当前路径os.getcwd() 2.获取指定路径下有哪些文件和目录,os.listdir(path)返回一个list 3.创建目录(一级)os.mkdir(paht) 4.删除文件os.remove(path) 5.递归删除空目录os.removedirs(path) 6.删除空目录os.rmdir(path) 7.创建多级目录os.makedirs(path) 二.os.path常用方法 1.路径拼接os.path.join(path1,path2…) 2.路径
-

使用Python制作表情包实现换脸功能
"表情包"是现在非常流行的交流方式,通过一张图片就能把文字不能表达或不便于表达的情感给表示出来,表情包一经诞生,就统治了中国人的社交圈,尤其是年轻人,他们的社交方式是所谓"天可不聊,图不可不斗",几乎任何对话都会出现表情包的身影,一言不合就斗图,自己也会在聊天中发几个表情包,可是总会造成一些小误会,比如下面的图 有好多朋友看到这个表情包之后误以为这也是我用Python做的,其实不然,这个图就是网上普通的表情包,但是今天我要用Python做几个表情包. 今天制作表情包
-
python制作爬虫爬取京东商品评论教程
本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化.下面是要抓取的商品信息,一款女士文胸.这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论. 京东商品评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论的信息.因此我们需要先找到存放商品评论信息的文件.这里我们使用Chrome浏览器里的开发者工具进行查找. 具体方法是在商品详情页点击鼠标右键,选择检查,在弹出的开发者工具界
-
用Python制作简单的朴素基数估计器的教程
假设你有一个很大的数据集,非常非常大,以至于不能全部存入内存.这个数据集中有重复的数据,你想找出有多少重复的数据,但数据并没有排序,由于数据量太大所以排序是不切实际的.你如何来估计数据集中含有多少无重复的数据呢?这在许多应用中是很有用的,比如数据库中的计划查询:最好的查询计划不仅仅取决于总共有多少数据,它也取决于它含有多少无重复的数据. 在你继续读下去之前,我会引导你思考很多,因为今天我们要讨论的算法虽然很简单,但极具创意,它不是这么容易就能想出来的. 一个简单的朴素基数估计器 让我们从一个简单
-
把jQuery的类、插件封装成seajs的模块的方法
注:本文使用的seajs版本是2.1.1一.把Jquery封装成seajs的模块 复制代码 代码如下: define(function () { //这里放置jquery代码 把你喜欢的jquery版本放进来就好了 return $.noConflict();}); 调用方法:这样引进就可以像以前一样使用jquery 复制代码 代码如下: define(function (require, exports, module) { var $ = require('./js/jquery');
-
python实战之制作表情包游戏
导语 大家好,我是木木子(๑╹◡╹)ノ" 今日迟来的游戏更新! 仅仅是因为最近练车一直没咋时间了~ 科二还挂科了23333~我emo了
-
Python学习之包与模块详解
目录 什么是 Python 的包与模块 包的身份证 如何创建包 创建包的小练习 包的导入 - import 模块的导入 - from…import 导入子包及子包函数的调用 导入主包及主包的函数调用 导入的包与子包模块之间过长如何优化 强大的第三方包 什么是第三方包 如何安装第三方包 总结 大家好,学完面向对象与异常处理机制之后,接下里我们要学习 包与模块 .首先我们要了解什么是包?什么是模块?接下来我们还要学习 如何自定义创建包.自定义创建模块以及如何导入包与模块.最后我们在学习如何使用第三方