利用Pandas读取某列某行数据之loc和iloc用法总结
目录
- 1.loc方法
- 2.iloc方法
- 补充:利用loc、iloc提取所有数据
- 总结
实际操作中我们经常需要寻找数据的某行或者某列,这里介绍我在使用Pandas时用到的两种方法:iloc和loc。
loc:通过行、列的名称或标签来索引
iloc:通过行、列的索引位置来寻找数据
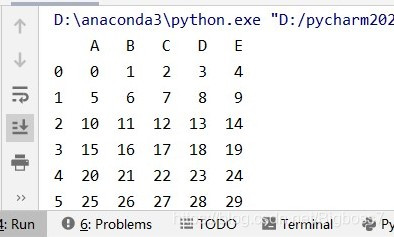
首先,我们先创建一个Dataframe,生成数据,用于下面的演示
import pandas as pd
import numpy as np
# 生成DataFrame
data = pd.DataFrame(np.arange(30).reshape((6,5)),
columns=['A','B','C','D','E'])
# 写入本地
data.to_excel("D:\\实验数据\\data.xls", sheet_name="data")
print(data)
1.loc方法
loc方法是通过行、列的名称或者标签来寻找我们需要的值。
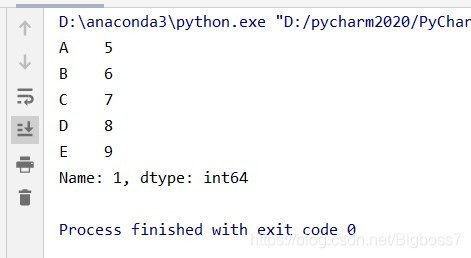
(1)读取第二行的值
# 索引第二行的值,行标签是“1” data1 = data.loc[1]
结果:
备注: #下面两种语法效果相同 data.loc[1] == data.loc[1,:]
(2)读取第二列的值
# 读取第二列全部值 data2 = data.loc[ : ,"B"]
结果:

(3)同时读取某行某列
# 读取第1行,第B列对应的值 data3 = data.loc[ 1, "B"]
结果:

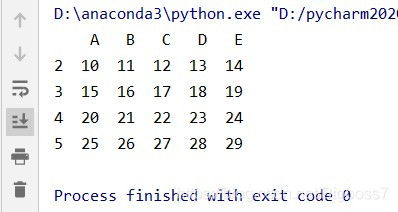
(4)读取DataFrame的某个区域
# 读取第1行到第3行,第B列到第D列这个区域内的值 data4 = data.loc[ 1:3, "B":"D"]
结果:

(5)根据条件读取
# 读取第B列中大于6的值 data5 = data.loc[ data.B > 6] #等价于 data5 = data[data.B > 6]
结果:
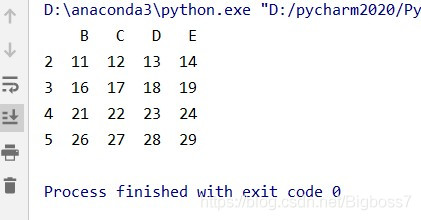
(6)也可以进行切片操作
# 进行切片操作,选择B,C,D,E四列区域内,B列大于6的值 data1 = data.loc[ data.B >6, ["B","C","D","E"]]
结果:
2.iloc方法
iloc方法是通过索引行、列的索引位置[index, columns]来寻找值
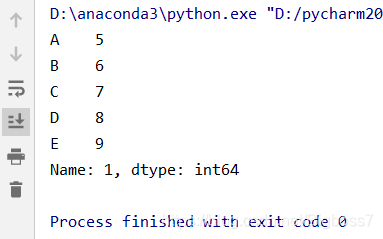
(1)读取第二行的值
# 读取第二行的值,与loc方法一样 data1 = data.iloc[1] # data1 = data.iloc[1, :],效果与上面相同
结果:
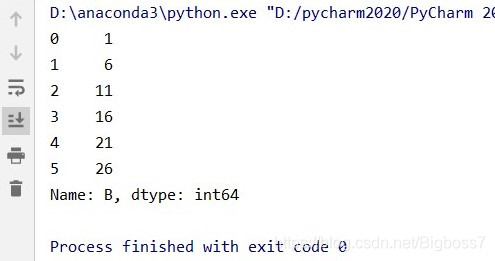
(2)读取第二列的值
# 读取第二列的值 data1 = data.iloc[:, 1]
结果:
(3)同时读取某行某列
# 读取第二行,第二列的值 data1 = data.iloc[1, 1]
结果:

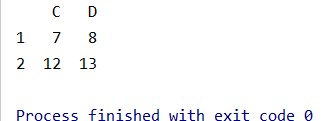
(4)进行切片操作
# 按index和columns进行切片操作 # 读取第2、3行,第3、4列 data1 = data.iloc[1:3, 2:4]
结果:
注意:
这里的区间是左闭右开,data.iloc[1:3, 2:4]中的第4行、第5列取不到
补充:利用loc、iloc提取所有数据
In[8]:data.loc[:,:] #取A,B,C,D列的所有行
Out[8]:
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
In[9]:data.iloc[:,:] #取第0,1,2,3列的所有行
Out[9]:
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
利用loc函数,根据某个数据来提取数据所在的行
In[10]: data.loc[data['A']==0] #提取data数据(筛选条件: A列中数字为0所在的行数据) Out[10]: A B C D a 0 1 2 3
总结
到此这篇关于利用Pandas读取某列某行数据之loc和iloc用法的文章就介绍到这了,更多相关Pandas读取列行数据之loc和iloc内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
对pandas中iloc,loc取数据差别及按条件取值的方法详解
Dataframe使用loc取某几行几列的数据: print(df.loc[0:4,['item_price_level','item_sales_level','item_collected_level','item_pv_level']]) 结果如下,取了index为0到4的五行四列数据. item_price_level item_sales_level item_collected_level item_pv_level 0 3 3 4 14 1 3 3 4 14 2 3 3 4 14
-
pandas.DataFrame删除/选取含有特定数值的行或列实例
1.删除/选取某列含有特殊数值的行 import pandas as pd import numpy as np a=np.array([[1,2,3],[4,5,6],[7,8,9]]) df1=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC')) print(df1) df2=df1.copy() #删除/选取某列含有特定数值的行 #df1=df1[df1['A'].isin([1])] #df1[df1['A'].
-
![详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据](/assets/blank.gif)
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
pandas的DataFrame对象,本质上是二维矩阵,跟常规二维矩阵的差别在于前者额外指定了每一行和每一列的名称.这样内部数据抽取既可以用"行列名称(对应.loc[]方法)",也可以用"矩阵下标(对应.iloc[]方法)"两种方式进行. 下面具体说明: (以下程序均在Jupyter notebook中进行,部分语句的print()函数省略) 首先生成一个DataFrame对象: import pandas as pd score = [[34,67,87],[68
-
详谈Pandas中iloc和loc以及ix的区别
Pandas库中有iloc和loc以及ix可以用来索引数据,抽取数据.但是方法一多也容易造成混淆.下面将一一来结合代码说清其中的区别. 1. iloc和loc的区别: iloc主要使用数字来索引数据,而不能使用字符型的标签来索引数据.而loc则刚好相反,只能使用字符型标签来索引数据,不能使用数字来索引数据,不过有特殊情况,当数据框dataframe的行标签或者列标签为数字,loc就可以来其来索引. 好,先上代码,先上行标签和列标签都为数字的情况. import pandas as pd impo
-
Python Pandas数据分析之iloc和loc的用法详解
Pandas 是一套用于 Python 的快速.高效的数据分析工具.它可以用于数据挖掘和数据分析,同时也提供数据清洗功能.本篇目录如下: 一.iloc 1.定义 iloc索引器用于按位置进行基于整数位置的索引或者选择. 2.语法 df.iloc [row selection, column selection] 3.代码示例 (1)导入数据 (2)选择单行或单列 (3)选择多行或多列 (4)注意 iloc选择一行时返回Series,选择多行返回DataFrame,通过传递列表可转为DataFra
-
详解pandas中iloc, loc和ix的区别和联系
Pandas库十分强大,但是对于切片操作iloc, loc和ix,很多人对此十分迷惑,因此本篇博客利用例子来说明这3者之一的区别和联系,尤其是iloc和loc. 对于ix,由于其操作有些复杂,我在另外一篇博客专门详细介绍ix. 首先,介绍这三种方法的概述: loc gets rows (or columns) with particular labels from the index. loc从索引中获取具有特定标签的行(或列).这里的关键是:标签.标签的理解就是name名字. iloc get
-
聊聊Python pandas 中loc函数的使用,及跟iloc的区别说明
loc和iloc的意思 首先,loc是location的意思,和iloc中i的意思是指integer,所以它只接受整数作为参数,详情见下面. loc和iloc的区别及用法展示 1.区别 loc works on labels in the index. iloc works on the positions in the index (so it only takes integers). 2.用法展示 首先创建一个dataframe: 1)loc为Selection by Label函数,即为
-
pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 1.重新索引:reindex和ix 上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号.列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子. 1.1 Series 比方说:data=Series([4,5,6],index=['a',
-
pandas 选取行和列数据的方法详解
前言 本文介绍在 pandas 中如何读取数据行列的方法.数据由行和列组成,在数据库中,一般行被称作记录 (record),列被称作字段 (field).回顾一下我们对记录和字段的获取方式:一般情况下,字段根据名称获取,记录根据筛选条件获取.比如获取 student_id 和 studnent_name 两个字段:记录筛选,比如 sales_amount 大于 10000 的所有记录.对于熟悉 SQL 语句的人来说,就是下面的语句: select student_id, student_name
-
利用Pandas读取某列某行数据之loc和iloc用法总结
目录 1.loc方法 2.iloc方法 补充:利用loc.iloc提取所有数据 总结 实际操作中我们经常需要寻找数据的某行或者某列,这里介绍我在使用Pandas时用到的两种方法:iloc和loc. loc:通过行.列的名称或标签来索引 iloc:通过行.列的索引位置来寻找数据 首先,我们先创建一个Dataframe,生成数据,用于下面的演示 import pandas as pd import numpy as np # 生成DataFrame data = pd.DataFrame(np.ar
-
利用Pandas读取表格行数据判断是否相同的方法
描述: 下午快下班的时候公司供应链部门的同事跑过来问我能不能以程序的方法帮他解决一些excel表格每周都需要手工重复做的事情,Excel 是数据处理最常用的办公工具对于市场.运营都应该很熟练.哈哈,然而程序员是不怎么会用excel的.下面给大家介绍一下pandas, Pandas是一个强大的分析结构化数据的工具集:它的使用基础是Numpy(提供高性能的矩阵运算):用于数据挖掘和数据分析,同时也提供数据清洗功能. 具体需求: 找出相同的数字,把与数字对应的英文字母合并在一起. 期望最终生成值:
-
如何利用Pandas删除某列指定值所在的行
目录 前言 1.data.dropna() 1-1 axis确定删除存在缺失值的行或者是列 1-2 how 确定存在缺失值时,是否删除行或者列 1-3 thresh=n表示保留至少含有n个非na数值的行 1-4 subset确定要在哪些列中查找缺失值 1-5 inplace确定是否直接在原DataFrame修改 2.data.drop 2-1 labels 指定行或者列的名称 2-2 index 指定要删除的行 2-3 columns 指定要删除的列 3.实例 3-1 统计0的数量 3-2 找出
-
Python如何利用pandas读取csv数据并绘图
目录 如何利用pandas读取csv数据并绘图 绘制图像 展示结果 pandas画pearson相关系数热力图 pearson相关系数计算函数 如何利用pandas读取csv数据并绘图 导包,常用的numpy和pandas,绘图模块matplotlib, import matplotlib.pyplot as plt import pandas as pd import numpy as np fig = plt.figure() ax = fig.add_subplot(111) 读取csv文
-
利用pandas读取中文数据集的方法
直接利用numpy读取非数字型的数据集时需要先进行转换,而且python3在处理中文数据方面确实比较蛋疼.最近在学习周志华老师的那本西瓜书,需要没事和一堆西瓜反复较劲,之前进行联系的时候都是利用批量替换先清理一遍数据,不过这样实在是太麻烦了,今天偶然发现可以使用pandas来实现读取中文数据集的功能. 首先分享一下数据集: 编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.7
-
Python利用pandas计算多个CSV文件数据值的实例
功能:扫描当前目录下所有CSV文件并对其中文件进行统计,输出统计值到CSV文件 pip install pandas import pandas as pd import glob,os,sys input_path='./' output_fiel='pandas_union_concat.csv' all_files=glob.glob(os.path.join(input_path,'sales_*')) all_data_frames=[] for file in all_files:
-
Pandas.DataFrame重置列的行名实现(set_index)
目录 set_index()的使用方法 基本用法 将指定的列保留为数据:参数drop 分配多索引 将索引更改为另一列(重置) 更改原始对象:参数inplace 读取csv文件等时指定索引 使用索引(行名)提取(选择)行和元素 pandas.DataFrame中的现有列分配给索引index(行名,行标签).为索引指定唯一的名称很方便,因为使用loc,at选择(提取)元素时很容易理解. 将描述以下内容. set_index()的使用方法 基本用法 将指定的列保留为数据:参数drop 分配多索引 将索
-
利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入: import pandas as pd df=pd.read_csv('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') 解决方法如下: import pandas as pd f=open('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') df=pd.read_csv(f) 以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编
-
python 读取txt中每行数据,并且保存到excel中的实例
使用xlwt读取txt文件内容,并且写入到excel中,代码如下,已经加了注释. 代码简单,具体代码如下: # coding=utf-8 ''' main function:主要实现把txt中的每行数据写入到excel中 ''' ################# #第一次执行的代码 import xlwt #写入文件 import xlrd #打开excel文件 fopen=open("e:\\a\\bb\\a.txt",'r') lines=fopen.readlines() #新
-
使用实现pandas读取csv文件指定的前几行
用于存储数据的csv文件有时候数据量是十分庞大的,然而我们有时候并不需要全部的数据,我们需要的可能仅仅是前面的几行. 这样就可以通过pandas中read_csv中指定行数读取的功能实现. 例如有data.csv文件,文件的内容如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv ,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04,co