C#实现二叉查找树
目录
- 1.实现API
- 1.数据结构
- 2.查找
- 3.插入
- 4.分析
- 有序性相关的方法和删除操作
- 1.最大键和最小键
- 2.向上取整和向下取整
- 3.选择操作
- 4.排名
- 5.删除最大键和删除最小键
- 6.删除操作
- 7.范围查找
- 8.性能分析
对于符号表,要支持高效的插入操作,就需要一种链式结构。但单链表无法使用二分查找,因为二分查找的高效来自于能够快速通过索引取得任何子数组的中间元素,链表只能遍历(详细描述)。为了将二分查找的效率和链表的灵活性结合,需要更复杂的数据结构:二叉查找树。具体来说,就是使用每个结点含有两个链接的二叉查找树来高效地实现符号表。
一棵二叉查找树(BST)是一棵二叉树,其中每个结点都含有一个IComparable 类型的键以及相关联的值,且每个结点的键都大于其左子树的任意结点的键而小于右子树的任意结点的键。

1.实现API
1.数据结构
public class BinarySearchTreesST<Key, Value> : BaseSymbolTables<Key, Value>
where Key : IComparable
{
private Node root;//二叉树根节点
/// <summary>
/// 嵌套定义一个私有类表示二叉查找树上的一个结点。
/// 每个结点都含有一个键,一个值,一条左连接,一条右连接和一个结点计数器。
/// 变量 N 给出了以该结点为根的子树的结点总数。
/// x.N = Size(x.left) + Size(x.right) + 1;
/// </summary>
private class Node
{
public Key key;
public Value value;
public Node left, right;
public int N;
public Node(Key key,Value value,int N)
{
this.key = key;
this.value = value;
this.N = N;
}
}
public override int Size()
{
return Size(root);
}
private int Size(Node x)
{
if (x == null)
return 0;
else
return x.N;
}
}
一棵二叉查找树代表了一组键(及其相应的值)的集合,而一个可以用多棵不同的二叉查找树表(起始根结点不同,树就不同),下面是一种情况。但不管什么情况的树,我们将一棵二叉查找树的所有键投影到一条直线上,一定可以得到一条有序的键列。
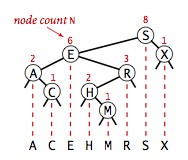
2.查找
在符号表中查找一个键可能有两种结果:命中和未命中。下面的实现算法是在二叉查找树中查找一个键的递归算法:如果树是空的,则查找未命中,如果被查找的键和根结点的键相等,查找命中,否则就递归地在适当地子树中继续查找。如果被查找的键较小就选择左子树,较大则选择右子树。当找到一个含有被查找键的结点(命中)或者当前子树变为空(未命中)时这个过程才结束。
public override Value Get(Key key)
{
return Get(root,key);
}
/// <summary>
///
/// </summary>
/// <param name="x">第一个参数是结点(子树的根结点)</param>
/// <param name="key">第二个参数是被查找的键</param>
/// <returns></returns>
private Value Get(Node x, Key key)
{
if (x == null)
return default(Value);
int cmp = key.CompareTo(x.key);
if (cmp < 0)
return Get(x.left, key);
else if (cmp > 0)
return Get(x.right, key);
else
return x.value;
}

3.插入
插入方法和查找的实现差不多,当查找一个不存在于树中的结点并结束于一条空连接时,需要将连接指向一个含有被查找的键的新节点。下面插入方法的逻辑:如果树是空的,就返回一个含有该键值对的新结点赋值给这个空连接;如果被查找的键小于根结点的键,继续在左子树中插入该键,否则就在右子树中插入。并且需要更新计数器。
public override void Put(Key key, Value value)
{
root = Put(root,key,value);
}
private Node Put(Node x, Key key, Value value)
{
if (x == null)
return new Node(key,value,1);
int cmp = key.CompareTo(x.key);
if (cmp < 0)
x.left = Put(x.left, key, value); //注意 x.left = 的意思
else if (cmp > 0)
x.right = Put(x.right, key, value);//注意 x.right =
else
x.value = value;
x.N = Size(x.left) + Size(x.right) + 1;
return x;
}

在查找和插入的递归实现中,可以将递归调用前的代码想象成沿着树向下走,将递归调用后的代码想象成沿着树向上爬。对于 Get 方法,这对应着一系列的返回指令。对于 Put 方法,意味着重置搜索路径上每个父结点指向子结点的连接,并增加路径上每个结点中计数器的值。在一棵简单的二叉查找树中,唯一的新连接就是在最底层指向新结点的连接,重置更上层的连接可以通过比较语句来避免。
4.分析
二叉查找树上算法的运行时间取决于树的形状,而树的形状又取决于键的插入顺序。在最好情况下,一棵含有 N 个结点的树是完全平衡的,每条空连接和根结点的距离都是 ~lgN 。在最坏情况下,搜索路径上有 N 个结点。
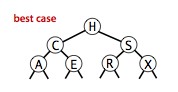


对于随机模型的分析而言,二叉查找树和快速排序很相似。根结点就是快速排序中的第一个切分元素,对于其他子树也同样使用。
在由 N 个随机键构造的二叉查找树,查找命中的平均所需的比较次数为 ~2lnN (约1.39lgN),插入和查找未命中平均所需的比较次数也为~2lnN (约1.39lgN)。插入和查找未命中比查找命中需要一次额外比较。
由此可知,在二叉查找树中查找比二分查找的成本高出约 39% ,但是插入操作所需的成本达到了对数界别。
有序性相关的方法和删除操作
1.最大键和最小键
如果根结点的左连接为空,那么一棵二叉查找树中最小的键就是根结点;如果左连接非空,那么树中的最小键就是左子树中的最小键。
public override Key Min()
{
return Min(root).key;
}
private Node Min(Node x)
{
if (x.left == null)
return x;
return Min(x.left);
}
2.向上取整和向下取整
如果给定的键 key 小于二叉查找树的根结点的键,那么小于等于 key 的最大键 Floor( key ) 一定在根结点的左子树中;如果给定的键大于二叉查找树的根结点,那么只有当根节点的右子树中存在小于等于给定键的结点时,小于等于给定键的最大键才会出现在右子树中,否则根结点就是小于等于 key 的最大键。
/// <summary>
/// 向下取整
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
public override Key Floor(Key key)
{
Node x = Floor(root,key);
if (x == null)
return default(Key);
return x.key;
}
private Node Floor(Node x, Key key)
{
if (x == null)
return default(Node);
int cmp = key.CompareTo(x.key);
if (cmp == 0)
return x;
if (cmp < 0)
return Floor(x.left,key);
Node t = Floor(x.right,key);
if (t != null)
return t;
else
return x;
}
3.选择操作
我们在二叉查找树的每个结点中维护的子树结点计数器变量 N 就是用来支持此操作的。
如果要找到排名为 k 的键(即树中正好有 k 个小于它的键)。如果左子树中的结点树 t 大于 k,就继续(递归地)在左子树中查找排名为 k 的键;如果 t == k,就返回根结点的键;如果 t 小于 k,就递归地在右子树中查找排名为 (k-t-1)的键。
public override Key Select(int k)
{
return Select(root, k).key;
}
private Node Select(Node x, int k)
{
if (x == null)
return default(Node);
int t = Size(x.left);
if (t > k)
return Select(x.left, k);
else if (t < k)
return Select(x.right, k - t - 1);
else
return x;
}
4.排名
排名是选择操作的逆方法,它会返回给定键的排名。它的实现和 Select 类似:如果给定的键等于根根结点的键,就返回左子树中的节点数 t ;如果给定的键小于根结点,就返回该键在左子树中的排名(递归计算);如果给定的键大于根结点,就返回 t+1 (根结点)再加上它在右子树中的排名(递归计算)。
public override int Rank(Key key)
{
return Rank(key,root);
}
private int Rank(Key key, Node x)
{
if (x == null)
return 0;
int cmp = key.CompareTo(x.key);
if (cmp < 0)
return Rank(key, x.left);
else if (cmp > 0)
return 1 + Size(x.left) + Rank(key, x.right);
else
return Size(x.left);
}
5.删除最大键和删除最小键
二叉查找树中最难实现的就是删除操作,我们先实现删除最小键的操作。我们要不断深入根节点的左子树直到遇到一个空连接,然后将指向该结点的连接指向该结点的右子树(只需在 x.left == null 时返回右链接,赋值给上层的左连接)。
/// <summary>
/// 注意可考虑删除根结点
/// </summary>
public override void DeleteMin()
{
root = DeleteMin(root);
}
private Node DeleteMin(Node x)
{
if (x.left == null)
return x.right;
x.left = DeleteMin(x.left);
x.N = Size(x.left) + Size(x.right) + 1;
return x;
}
6.删除操作
我们 可以使用上面类似的方法删除任意只有一个子结点或者没有子结点的结点,但是无法实现删除有两个子结点的结点的方法。我们在删除 x 结点后用它的右子树最小结点结点填补它的位置,这样就可以保证树的有序性,分四步完成:
- 1.将指向即将被删除的结点的连接保存为 t ;
- 2.将 x 指向它的后继结点 Min(t.right);
- 3.将 x 的右链接指向 DeleteMin(t.right),也就是删除右子树最小连接,然后返回 t 的右链接;
- 4.将 x 的左连接设为 t.left;
public override void Delete(Key key)
{
root = Delete(root,key);
}
private Node Delete(Node x, Key key)
{
if (x == null)
return null;
int cmp = key.CompareTo(x.key);
if (cmp < 0)
x.left = Delete(x.left, key);
else if (cmp > 0)
x.right = Delete(x.right, key);
else
{
if (x.right == null)
return x.left;
if (x.left == null)
return x.right;
Node t = x;
x = Min(t.right);
x.right = DeleteMin(t.right);
x.left = t.left;
}
x.N = Size(x.left) + Size(x.right) + 1;
return x;
}
该算法有个问题,在选择后继结点应该是随机的,应该考虑树的对成性。
7.范围查找
要实现能够返回给定范围内键的方法 Keys(),需要一个遍历二叉查找树的基本方法,叫做中序遍历。先找出根结点的左子树中的符合的所有键,然后找出根结点的键,最后找出根结点右子树的符合的所有键。
public override IEnumerable<Key> Keys(Key lo, Key hi)
{
Queue<Key> quene = new Queue<Key>();
Keys(root, quene,lo,hi);
return quene;
}
private void Keys(Node x, Queue<Key> quene, Key lo, Key hi)
{
if (x == null)
return;
int cmplo = lo.CompareTo(x.key);
int cmphi = hi.CompareTo(x.key);
if (cmplo < 0)
Keys(x.left,quene,lo,hi);
if (cmplo <= 0 && cmphi >= 0)
quene.Enqueue(x.key);
if (cmphi > 0)
Keys(x.right,quene,lo,hi);
}
全部代码
public class BinarySearchTreesST<Key, Value> : BaseSymbolTables<Key, Value>
where Key : IComparable
{
private Node root;//二叉树根节点
/// <summary>
/// 嵌套定义一个私有类表示二叉查找树上的一个结点。
/// 每个结点都含有一个键,一个值,一条左连接,一条右连接和一个结点计数器。
/// 变量 N 给出了以该结点为根的子树的结点总数。
/// x.N = Size(x.left) + Size(x.right) + 1;
/// </summary>
private class Node
{
public Key key;
public Value value;
public Node left, right;
public int N;
public Node(Key key,Value value,int N)
{
this.key = key;
this.value = value;
this.N = N;
}
}
public override int Size()
{
return Size(root);
}
private int Size(Node x)
{
if (x == null)
return 0;
else
return x.N;
}
public override Value Get(Key key)
{
return Get(root,key);
}
/// <summary>
///
/// </summary>
/// <param name="x">第一个参数是结点(子树的根结点)</param>
/// <param name="key">第二个参数是被查找的键</param>
/// <returns></returns>
private Value Get(Node x, Key key)
{
if (x == null)
return default(Value);
int cmp = key.CompareTo(x.key);
if (cmp < 0)
return Get(x.left, key);
else if (cmp > 0)
return Get(x.right, key);
else
return x.value;
}
public override void Put(Key key, Value value)
{
root = Put(root,key,value);
}
private Node Put(Node x, Key key, Value value)
{
if (x == null)
return new Node(key,value,1);
int cmp = key.CompareTo(x.key);
if (cmp < 0)
x.left = Put(x.left, key, value); //注意 x.left = 的意思
else if (cmp > 0)
x.right = Put(x.right, key, value);//注意 x.right =
else
x.value = value;
x.N = Size(x.left) + Size(x.right) + 1;
return x;
}
public override Key Min()
{
return Min(root).key;
}
private Node Min(Node x)
{
if (x.left == null)
return x;
return Min(x.left);
}
/// <summary>
/// 向下取整
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
public override Key Floor(Key key)
{
Node x = Floor(root,key);
if (x == null)
return default(Key);
return x.key;
}
private Node Floor(Node x, Key key)
{
if (x == null)
return default(Node);
int cmp = key.CompareTo(x.key);
if (cmp == 0)
return x;
if (cmp < 0)
return Floor(x.left,key);
Node t = Floor(x.right,key);
if (t != null)
return t;
else
return x;
}
public override Key Select(int k)
{
return Select(root, k).key;
}
private Node Select(Node x, int k)
{
if (x == null)
return default(Node);
int t = Size(x.left);
if (t > k)
return Select(x.left, k);
else if (t < k)
return Select(x.right, k - t - 1);
else
return x;
}
public override int Rank(Key key)
{
return Rank(key,root);
}
private int Rank(Key key, Node x)
{
if (x == null)
return 0;
int cmp = key.CompareTo(x.key);
if (cmp < 0)
return Rank(key, x.left);
else if (cmp > 0)
return 1 + Size(x.left) + Rank(key, x.right);
else
return Size(x.left);
}
/// <summary>
/// 注意可考虑删除根结点
/// </summary>
public override void DeleteMin()
{
root = DeleteMin(root);
}
private Node DeleteMin(Node x)
{
if (x.left == null)
return x.right;
x.left = DeleteMin(x.left);
x.N = Size(x.left) + Size(x.right) + 1;
return x;
}
public override void Delete(Key key)
{
root = Delete(root,key);
}
private Node Delete(Node x, Key key)
{
if (x == null)
return null;
int cmp = key.CompareTo(x.key);
if (cmp < 0)
x.left = Delete(x.left, key);
else if (cmp > 0)
x.right = Delete(x.right, key);
else
{
if (x.right == null)
return x.left;
if (x.left == null)
return x.right;
Node t = x;
x = Min(t.right);
x.right = DeleteMin(t.right);
x.left = t.left;
}
x.N = Size(x.left) + Size(x.right) + 1;
return x;
}
public override IEnumerable<Key> Keys(Key lo, Key hi)
{
Queue<Key> quene = new Queue<Key>();
Keys(root, quene,lo,hi);
return quene;
}
private void Keys(Node x, Queue<Key> quene, Key lo, Key hi)
{
if (x == null)
return;
int cmplo = lo.CompareTo(x.key);
int cmphi = hi.CompareTo(x.key);
if (cmplo < 0)
Keys(x.left,quene,lo,hi);
if (cmplo <= 0 && cmphi >= 0)
quene.Enqueue(x.key);
if (cmphi > 0)
Keys(x.right,quene,lo,hi);
}
}
8.性能分析
给定一棵树,树的高度决定了所有操作在最坏情况下的性能(范围查找除外,因为它的额外成本和返回的键的数量成正比),成正比。
随机构造的二叉查找树的平均高度为树中结点数量的对数级别,约为 2.99 lgN 。但如果构造树的键不是随机的(例如,顺序或者倒序),性能会大大降低,后面会讲到平衡二叉查找树。
| 算法 | 最坏情况下运行时间的增长量级 | 平均情况下的运行时间的增长量级 | 是否支持有序性相关操作 | ||
| 查找 | 插入 | 查找命中 | 插入 | ||
| 顺序查找(无序链表) | N | N | N/2 | N | 否 |
| 二分查找(有序数组) | lgN | N | lgN | N/2 | 是 |
| 二叉树查找 | N | N | 1.39lgN | 1.39lgN | 是 |
到此这篇关于C#实现二叉查找树的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

C#实现优先队列和堆排序
目录 优先队列 1.API 2.初级实现 3.堆的定义 二叉堆表示法 4.堆的算法 上浮(由下至上的堆的有序化) 下沉(由上至下的堆的有序化) 改进 堆排序 1.堆的构造 2.下沉排序 先下沉后上浮 优先队列 许多应用程序都需要处理有序的元素,但不一定要求它们全部有序,或是不一定要一次就将它们排序.很多情况下是收集一些元素,处理当前键值最大的元素,然后再收集更多的元素,再处理当前键值最大的元素.这种情况下,需要的数据结构支持两种操作:删除最大的元素和插入元素.这种数据结构类型叫优先队列. 这里,
-
C#算法之散列表
目录 1.散列函数 正整数 浮点数 字符串 组合键 将 HashCode() 的返回值转化为一个数组索引 自定义的 HashCode 软缓存 2.基于拉链法的散列表 散列表的大小 删除操作 有序性相关的操作 3.基于线性探测法的散列表 删除操作 键簇 线性探测法的性能分析 调整数组大小 拉链法 均摊分析 4.内存的使用 如果所有的键都是小整数,我们可以使用一个数组来实现无序的符号表,将键作为数组的索引而数组中键 i 处存储的就是它对应的值.散列表就是用来处理这种情况,它是简易方法的扩展并能够处理
-
C#使用符号表实现查找算法
高效检索海量信息(经典查找算法)是现代信息世界的基础设施.我们使用符号表描述一张抽象的表格,将信息(值)存储在其中,然后按照指定的键来搜索并获取这些信息.键和值的具体意义取决于不同的应用.符号表中可能会保存很多键和很多信息,因此实现一张高效的符号表是很重要的任务. 符号表有时被称为字典,有时被称为索引. 1.符号表 符号表是一种存储键值对的数据结构,支持两种操作:插入(put),即将一组新的键值对存入表中:查找(get),即根据给定的键得到相应的值.符号表最主要的目的就是将一个健和一个值联系起来
-
C#实现希尔排序
对于大规模乱序的数组,插入排序很慢,因为它只会交换相邻的元素,因此元素只能一点一点地从数组地一段移动到另一端.希尔排序改进了插入排序,交换不相邻地元素以对数组地局部进行排序,最终用插入排序将局部有序的数组排序. 希尔排序的思想是使数组中任意间隔为 h 的元素都是有序的.这样的数组成为 h 有序数组.换句话说,一个 h 有序数组就是 h 个相互独立的有序数组组合在一起的一个数组. 在进行排序时,刚开始 h 很大,就能将元素移动到很远的地方,为实现更小的 h 有序创造方便.h 递减到 1 时,相当于
-
C#实现快速排序算法
快速排序是应用最广泛的排序算法,流行的原因是它实现简单,适用于各种不同情况的输入数据且在一般情况下比其他排序都快得多. 快速排序是原地排序(只需要一个很小的辅助栈),将长度为 N 的数组排序所需的时间和 N lg N 成正比. 1.算法 快速排序也是一种分治的排序算法.它将一个数组分成两个子数组,将两部分独立地排序. 快速排序和归并排序是互补:归并排序是将数组分成两个子数组分别排序,并将有序数组归并,这样数组就是有序的了:而快速排序将数组通过切分变成部分有序数组,然后拆成成两个子数组,当两个子数
-
C#实现平衡查找树
目录 1. 2-3查找树 1.查找 2.向 2- 结点中插入新键 3.向一棵只含有一个 3- 结点的树中插入新键 4.向一个父结点为 2- 结点的 3- 结点中插入新键 5.向一个父结点为 3- 结点的 3- 结点插入新键 6.分解根结点 7.局部变换 8.全局性质 2.红黑二叉查找树 1.定义 2.一一对应 3.颜色表示 4.旋转 5.在旋转后重置父结点的链接 6.向单个 2- 结点中插入新键 7.向树底部的 2- 结点插入新键 8.向一棵双键树(即一个 3- 结点)中插入新键 9.颜色变换
-
JavaScript数据结构之二叉查找树的定义与表示方法
本文实例讲述了JavaScript数据结构之二叉查找树的定义与表示方法.分享给大家供大家参考,具体如下: 树是一种非线性的数据结构,以分层的方式存储数据.树被用来存储具有层级关系的数据,比如文件系统中的文件:树还被用来存储有序列表.这里将研究一种特殊的树:二叉树.选择树而不是那些基本的数据结构,是因为在二叉树上进行查找非常快(而在链表上查找则不是这样),为二叉树添加或删除元素也非常快(而对数组执行添加或删除操作则不是这样). 树是n个结点的有限集.最上面的为根,下面为根的子树.树的节点包含一个数
-
JS实现二叉查找树的建立以及一些遍历方法实现
二叉查找树是由节点和边组成的. 我们可以定义一个节点类Node,里面存放节点的数据,及左右子节点,再定义一个用来显示数据的方法: //以下定义一个节点类 function Node(data,left,right){ // 节点的键值 this.data = data; // 左节点 this.left = left; // 右节点 this.right = left; // 显示该节点的键值 this.show = show; } // 实现show方法 function show(){ re
-
二叉查找树的插入,删除,查找
二叉查找树是满足以下条件的二叉树:1.左子树上的所有节点值均小于根节点值,2.右子树上的所有节点值均不小于根节点值,3.左右子树也满足上述两个条件. 二叉查找树的插入过程如下:1.若当前的二叉查找树为空,则插入的元素为根节点,2.若插入的元素值小于根节点值,则将元素插入到左子树中,3.若插入的元素值不小于根节点值,则将元素插入到右子树中. 二叉查找树的删除,分三种情况进行处理:1.p为叶子节点,直接删除该节点,再修改其父节点的指针(注意分是根节点和不是根节点),如图a. 2.p为单支节点(即只有
-
java二叉查找树的实现代码
本文实例为大家分享了java二叉查找树的具体代码,供大家参考,具体内容如下 package 查找; import edu.princeton.cs.algs4.Queue; import edu.princeton.cs.algs4.StdOut; public class BST<Key extends Comparable<Key>, Value> { private class Node { private Key key; // 键 private Value value;
-
c语言实现二叉查找树实例方法
以下为算法详细流程及其实现.由于算法都用伪代码给出,就免了一些文字描述. 复制代码 代码如下: /*******************************************=================JJ日记=====================作者: JJDiaries(阿呆) 邮箱:JJDiaries@gmail.com日期: 2013-11-13============================================二叉查找树,支持的操作包括:SERA
-
java 二叉查找树实例代码
java 二叉查找树实例代码 1.左边<中间<右边 2.前序遍历 左中右 3.中序遍历 中左右 4.后序遍历 左右中 public class BinaryTree { // 二叉树的根节点 public TreeNode rootNode ; // 记录搜索深度 public int count; /** * 利用传入一个数组来建立二叉树 */ public BinaryTree(int[] data) { for (int i = 0; i < data. length; i++)
-
Java基于二叉查找树实现排序功能示例
本文实例讲述了Java基于二叉查找树实现排序功能.分享给大家供大家参考,具体如下: /** * 无论排序的对象是什么,都要实现Comparable接口 * * @param <T> */ public class BinaryNode<T extends Comparable<T>> { private static int index = 0; // 排序下标 private static int len = 0; // 最大数组长度 private T t; //
-
浅谈二叉查找树的集合总结分析
我们都知道Dictionary<TKey, TValue>查找元素非常快,其实现原理是:将你TKey的值散列到数组的指定位置,将TValue的值存入对应的位置,由于取和存用的是同一个算法,所以就很容易定位到TValue的位置,花费的时间基本上就是实现散列算法的时间,跟其中元素的个数没有关系,故取值的时间复杂度为O(1).集合无非都是基于最基础语法的数组[],先欲分配,然后向其中添加元素,容量不够就创建一个2倍容量的数组,将之前的元素赋值过来,将之前的数组回收,但基于散列算法的集合这点上有点不同
-
C语言 二叉查找树性质详解及实例代码
二叉查找树性质 1.二叉树 每个树的节点最多有两个子节点的树叫做二叉树. 2.二叉查找树 一颗二叉查找树是按照二叉树的结构来组织的,并且满足一下性质: 一个节点所有左子树上的节点不大于盖节点,所有右子树的节点不小于该节点. 对查找树的操作查询,插入,删除等操作的时间复杂度和树的高度成正比, 因此,构建高效的查找树尤为重要. 查找树的遍历 先序遍历 查找树的遍历可以很简单的采用递归的方法来实现. struct list { struct list *left;//左子树 struct list *
-
c++实现二叉查找树示例
复制代码 代码如下: /** 实现二叉查找树的基本功能*/ #include <iostream>#include <cstring>#include <algorithm>#include <cstdio>#include <string> using namespace std; const int M = 10000; //定义数据节点class dNode{public: string name; int age; bool sex; d