C语言简明讲解快速排序的应用
目录
- 快速排序
- 1.1快速排序引入
- 1.2快速排序的基本思想
- 1.3快速排序的排序流程
- 1.4实例说明
- 1.5代码实现
- 1.6性能分析
快速排序
快速排序,说白了就是给基准数据找其正确索引位置的过程
1.1快速排序引入
希尔排序相当于直接插入排序的升级,他们属于插入排序类;堆排序相当于简单选择排序的升级,他们同属于选择排序类;而对于交换排序类的冒泡排序升级版本就是快速排序。
1.2快速排序的基本思想
通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个排序的目的。
1.3快速排序的排序流程
- 首先设定一个分界值,通过该分界值将数组分成左右两部分。
- 将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
- 然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
- 重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
总结来说:就是分治+填数
1.4实例说明
以12、10、8、22、5、13、28、21、11我们要将它按从小到大排序排序过程:
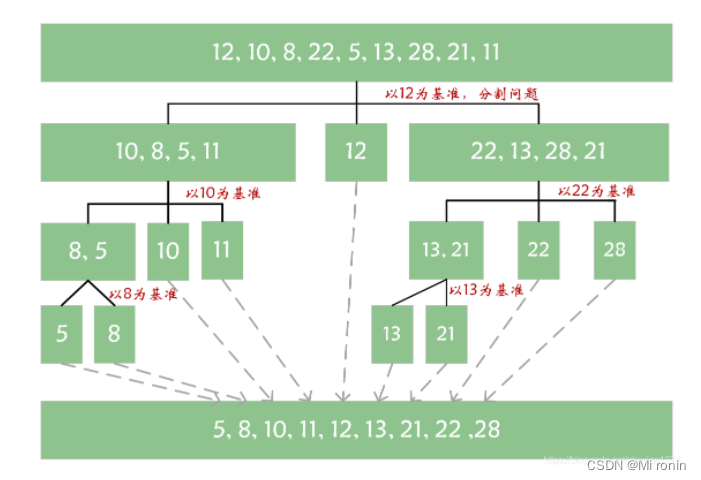
详细过程:
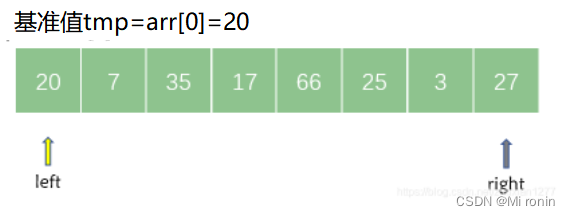
设定两个指针 left 和 right,它们初始分别指向待排序序列的左端和右端;此外还要附设一个基准元素 tmp(一般选取第一个,本例中基准tmp的值为 20)。
首先从 right 所指的位置从右向左搜索找到第一个小于 tmp 的元素,然后将其记录在基准元素所在的位置。
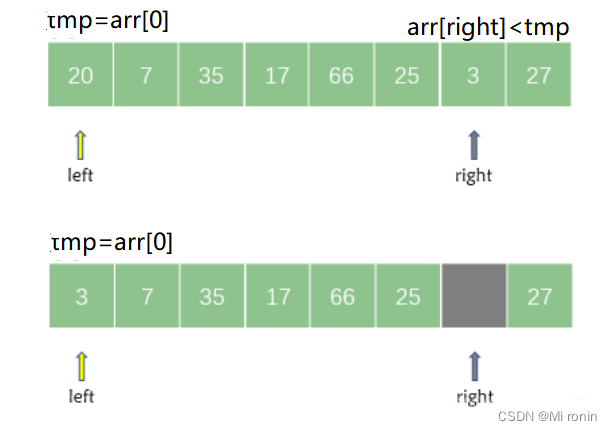
接着从 left 所指的位置从左向右搜索找到第一个大于 tmp的元素,然后将其记录在 right 所指向的位置。
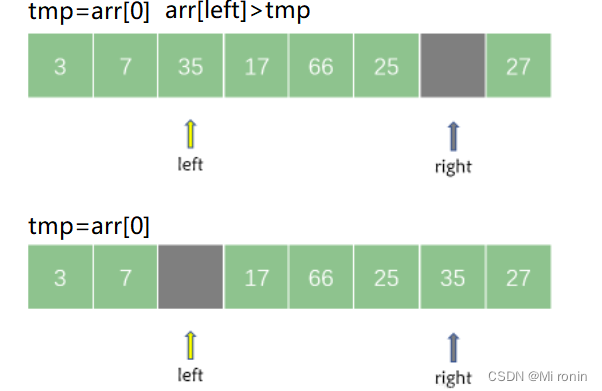
然后再从 right 所指向的位置继续从右向左搜索找到第一个小于 tmp 的元素,然后将其记录在 left 所指向的位置。
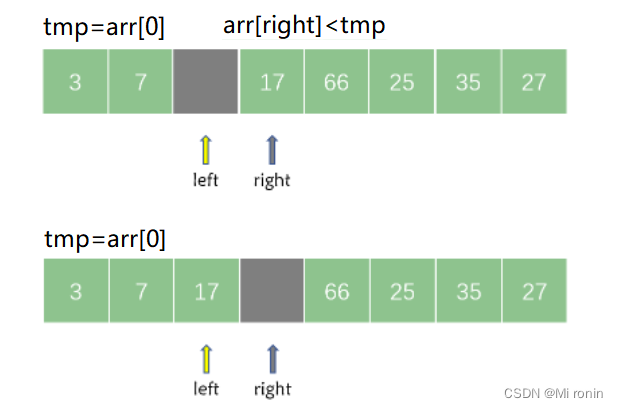
接着,left 继续从左向右搜索第一个大于 tmp的元素,如果在搜索过程中出现了 left == right ,则说明一趟快速排序结束。此时将 tmp 记录在 left 和 right 共同指向的位置即可。
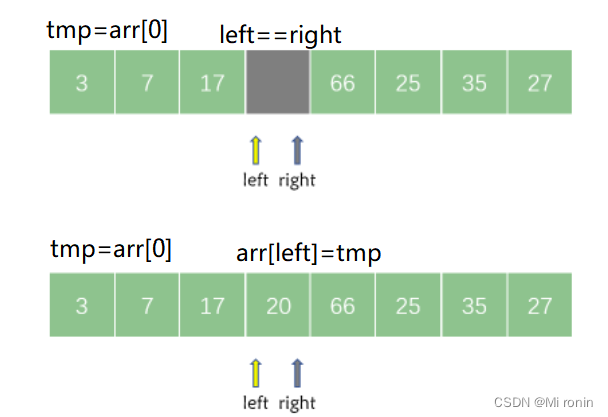
以上便是一轮快速排序的详细过程
注意:
- 向下划分至少需要这个组两个数据,才有必要划分,0个或者1个都没有必要
- 划分时:从右向左找比基准小的(相等)
- 从左向右找比基准值大的
1.5代码实现
//一次划分函数 核心函数 //返回基准值最终所在下标
int Partition(int *arr, int left, int right)
{
//先讲arr数组里的[left, right]的第一个值 作为基准值
int tmp = arr[left];
while(left < right)
{
while(left<right && arr[right] > tmp)//左右边界没有相遇且当前右边的值大于基准值tmp
right--;
if(left < right)//如果此时,左右边界没有相遇,那就只能证明右边right找到了一个小于等于基准值tmp的值
{
arr[left] = arr[right];
}
else
{
break;
}
while(left<right && arr[left] <= tmp)//左右边界没有相遇且当前左边的值小于等于基准值tmp
left++;
if(left < right)//如果此时,左右边界没有相遇,那就只能证明左边left找到了一个大于基准值tmp的值
{
arr[right] = arr[left];
}
else
{
break;
}
}
arr[left] = tmp;//此时 因为 left == right
return left;//return right ok
}
void Quick(int *arr, int left, int right)
{
if(left < right)//通过left <right 保证[left, right]这个范围内至少两个数据
{
int par = Partition(arr, left, right);
if(left < par-1)//基准值左半部分 至少有两个值才有必要去递归
{
Quick(arr, left, par-1);
}
if(par+1 < right)//基准值右半部分 至少有两个值才有必要去递归
{
Quick(arr, par+1, right);
}
}
}
void QuickSort(int *arr, int len)
{
Quick(arr, 0, len-1);
}
1.6性能分析
越乱越快,越有序越慢
时间复杂度:
最优情况:O(nlogn)每次数据元素都能平均的分成两个部分。得到一个完全二叉树;
最坏情况: O(n^2)这个数仅有右子树或左子树,比较次数为 (n-1)+(n-2) + (n-3) + … +1=n*(n-1)/2 ;
平均情况:O(nlogn)。
空间复杂度:O(1)。
稳定性:因为关键字的比较和交换是跳跃进行的,会改变数据元素的相对位置;因此,快速排序是一种不稳定的排序方法,但是也是内排序中平均效率最高的排序算法。
(小白一位,如有错误欢迎指正)
到此这篇关于C语言简明讲解快速排序的应用的文章就介绍到这了,更多相关C语言快速排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C语言的冒泡排序和快速排序算法使用实例
冒泡排序法 题目描述: 用一维数组存储学号和成绩,然后,按成绩排序输出. 输入: 输入第一行包括一个整数N(1<=N<=100),代表学生的个数. 接下来的N行每行包括两个整数p和q,分别代表每个学生的学号和成绩. 输出: 按照学生的成绩从小到大进行排序,并将排序后的学生信息打印出来. 如果学生的成绩相同,则按照学号的大小进行从小到大排序. 样例输入: 3 1 90 2 87 3 92 样例输出: 2 87 1 90 3 92 代码: #
-

C语言中使用快速排序算法对元素排序的实例详解
调用C语言的快速排序算法qsort(); #include<stdio.h> #include<stdlib.h> #include<string.h> #define SIZE 100 //从小到大排序 int comp1(const void *x,const void *y) { return *(int *)x - *(int *)y; } //从大到小排序 int comp2(const void *x,const void *y) { return *(in
-
C语言非递归算法解决快速排序与归并排序产生的栈溢出
目录 1.栈溢出原因和递归的基本认识 2.快速排序(非递归实现) 3.归并排序(非递归实现) 建议还不理解快速排序和归并排序的小伙伴们可以先去看我上一篇博客哦!C语言超详细讲解排序算法下篇 1.栈溢出原因和递归的基本认识 我们先简单来了解下内存分布结构: 栈区:用于存放地址.临时变量等: 堆区:程序运行期间动态分配所使用的场景: 静态区
-
C语言实现快速排序算法
一.快速排序算法(Quicksort) 1. 定义 快速排序由C. A. R. Hoare在1962年提出.快速排序是对冒泡排序的一种改进,采用了一种分治的策略. 2. 基本思想 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 3. 步骤 a. 先从数列中取出一个数作为基准数. b. 分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全
-
C语言之快速排序算法(递归Hoare版)介绍
废话不多说,先看代码 #define _CRT_SECURE_NO_WARNINGS 1 //快速排序算法,递归求解 #include <stdio.h> void swap(int* a, int* b) { int c = 0; c = *a; *a = *b; *b = c; } void Compare(int arr[], int one, int end) { int first = one;//最左边数组下标 int last = end;//最右边数组下标 int key =
-
c语言快速排序算法示例代码分享
步骤为:1.从数列中挑出一个元素,称为 "基准"(pivot);2.重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边).在这个分区退出之后,该基准就处于数列的中间位置.这个称为分区(partition)操作.3.递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序.递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了.虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iterat
-
C语言实现单链表的快速排序算法
目录 背景 设计思路 算法主要步骤 快速排序算法实现 整个程序源代码 测试案例 总结 背景 传统QuickSort算法最大不足之处在于,由于其基于可索引存储结构设计(一般为数组或索引表),因而无法用于链式存储结构,而链式存储结构的实际应用非常广泛,例如动态存储管理.动态优先级调度等等,故本文针对于单向链表,以QuickSort的分治策略为基础,提出一种可用于单向链表的快速排序算法. 设计思路 将单向链表的首节点作为枢轴节点,然后从单向链表首部的第二个节点开始,逐一遍历所有后续节点,并将这些已遍历
-
C语言快速排序与二分查找算法示例
本文实例讲述了C语言二分排序与查找算法.分享给大家供大家参考,具体如下: 题目:首先产生随机数,再进行快速排序,再进行二分查找. 实现代码: #include <stdio.h> #include <stdlib.h> #include <time.h> void quiksort(int a[],int low,int high) { int i = low; int j = high; int temp = a[i]; if( low < high) { wh
-
C语言库函数qsort及bsearch快速排序算法使用解析
目录 qsort 含义 实现 格局打开 bsearch qsort qsrot 就是C语言库函数中的快速排序函数,对数组,结构体都可以实现快速排序, 他在头文件<stdlib.h>中使用,声明格式为: void qsort(void* base, size_t nums, size_t size, int (*compare)(const void *, const void*)) 这么烦人一长串的参数各是什么意思呢,base 是指向要排序的数组的第一个元素的指针.nums是由 base 指向
-
C语言简明讲解快速排序的应用
目录 快速排序 1.1快速排序引入 1.2快速排序的基本思想 1.3快速排序的排序流程 1.4实例说明 1.5代码实现 1.6性能分析 快速排序 快速排序,说白了就是给基准数据找其正确索引位置的过程 1.1快速排序引入 希尔排序相当于直接插入排序的升级,他们属于插入排序类:堆排序相当于简单选择排序的升级,他们同属于选择排序类:而对于交换排序类的冒泡排序升级版本就是快速排序. 1.2快速排序的基本思想 通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字比另一部分记录的关键字小,则可分
-
C语言简明讲解三目运算符和逗号表达式的使用
目录 一.三目运算符 二.逗号表达式 三.小结 一.三目运算符 三目运算符( a ? b : c)可以作为逻辑运算的载体 规则:当 a 的值为真时,返回 b 的值:否则返回 c 的值 下面看一段代码: #include <stdio.h> int main() { int a = 1; int b = 2; int c = 0; c = a < b ? a : b; (a < b ? a : b) = 3; printf("%d\n", a); printf(&
-
C语言简明讲解队列的实现方法
目录 前言 队列的表示和实现 队列的概念及结构 代码实现 束语 前言 大家好啊,我又双叒叕来水博客了,道路是曲折的,前途是光明的,事物是呈螺旋式上升的,事物最终的发展结果还是我们多多少少能够决定的,好啦,吹水结束,这与这篇博客的主题并没有太多联系.关于栈和队列这一板块本来是想不写(就是想偷懒),但是想了想,觉得这样不太好,关于数据结构这一块可能会有缺失,所以最终还是决定写,必须补齐这一块,恰好最近有时间写博客,所以还是写了,这篇博客将介绍队列的知识点,理解链表那一块的操作后,栈和队列的相关操作还
-
C语言简明讲解类型转换的使用与作用
目录 一.类型之间的转换 二.强制类型转换 三.隐式类型转换 四.表达式中的隐式类型转换 五.小结 一.类型之间的转换 C语言中的数据类型可以进行转换 强制类型转换 隐式类型转换 二.强制类型转换 强制类型转换的语法 (Type)var_name; (Type)value; 强制类型转换的结果 目标类型能够容纳目标值:结果不变 目标类型不能容纳目标值:结果将产生截断 注意:不是所有的强制类型转换都能成功,当不能进行强制类型转换时,编译器将产生错误信息(比如将自定义数据类型转换成基本数据类型).
-
C语言简明讲解操作符++和--的使用方法
目录 一.++与--操作符的本质 二.++与-- 操作符使用分析 三.小结 一.++与--操作符的本质 ++ 和 -- 操作符对应两条汇编指令 前置 变量自增(减)1 取变量值 后置 取变量值 变量自增(减)1 下面看一段神奇的代码: #include <stdio.h> int main() { int i = 0; int r = 0; r = (i++) + (i++) + (i++); printf("i = %d\n", i); printf("r =
-
C语言简明讲解变量的属性
目录 一.C语言中的变量属性 二.auto 关键字 三.register 关键字 四.static 关键字 五.extern 关键字 六.小结 一.C语言中的变量属性 C语言中的变量可以有自己的属性 在定义变量的时候可以加上“属性”关键字 "属性”关键字指明变量的特有意义 语法: property type var_name; 示例: int main() { auto char i; register int j; static long k; extern double m; return
-
C语言简明讲解单引号与双引号的使用
目录 一.单引号和双引号 二.小贴士 三.程序实例分析1 四.程序实例分析2 五.容易混淆的代码 六.小结 一.单引号和双引号 C语言中的单引号用来表示字符字面量 C语言中的双引号用来表示字符串字面量 'a'表示字符字面量,在内存中占1个字节,'a'+1表示'a'的ASCII码加1,结果为'b' "a"表示字符串字面量,在内存中占2个字节,"a"+1表示指针运算,结果指向"a"结束符'\0' 下面看一段单引号和双引号本质的代码: #include
-
C语言简明讲解预编译的使用
目录 小复习 1.内置符号 2.自定义符号 3.自定义宏 4.条件编译 小复习 预处理,预编译是编译的第一步. 会有三件基本的事情发生: 引入#include 去除注释 修改#define 1.内置符号 这些符号都可以直接使用: __FILE__ 点c文件全名__LINE__ 当前行号__DATE__ 编译日期__TIME__ 编译时间 举例: #include<stdio.h> int main() {
-
C语言简明讲解归并排序的应用
目录 一.归并排序 1.1归并排序引入 1.2归并排序的概念 1.3归并排序的原理 1.4实例说明 1.5具体步骤说明 1.6代码实现 1.7性能分析 一.归并排序 1.1归并排序引入 对于堆排序来说,因为用到了完全二叉树的深度是(log2n+1)的特性,所以效率就比较高,但是堆结构的设计比较复杂,现在我们想要可以直接利用完全二叉树来排序的方法,这个方法就是归并排序. 1.2归并排序的概念 归并排序是建立在归并操作上的一种有效的排序算法,归并排序对序列的元素进行逐层折半分组,然后从最小分组开始比
-
C语言简明清晰讲解枚举
目录 概述 简单使用 入门 判断 自定义数值 一种不严格的写法 概述 一个类型,值只能是一堆值中的一个. 比如星期几,只会是星期一到星期天. 用数值表示的话就是0到6,但是0到6不太好理解. 而枚举可以用单词表示,提高了可读性. 本质上还是0到6. 简单使用 入门 新建三个变量,值分别为a b c #include<stdio.h> enum Gender { Male, Female, Empty }; int main() { enum Gender a = Male; enum Gend