Python 实现多表和工作簿合并及一表按列拆分
目录
- 一、相关知识点讲解
- 1.1 需要使用的相关库
- 1.2 os.walk(pwd)
- 1.3 os.path.join(path1,path2…)
- 1.4 案例解析
- 1.5 如何在一个列表中存放多个 DataFrame 数据
- 二、多工作簿合并(一)
- 2.1 将多个Excel合并到一个Excel中(每个Excel中只有一个sheet表)
- 三、多工作簿合并(二)
- 3.1 相关知识点讲解
- 3.1.1 xlsxwrite 的用法
- 3.1.2 xlrd 的用法
- 3.2 将多个 Excel 合并到一个 Excel 中(每个 Excel 中不只一个 sheet 表)
- 四、一个工作簿多 heet 合并
- 4.1 将一个 Excel 表中的多个 sheet 表合并,并保存到同一个excel。
- 五、一表拆分(按照表中某一列进行拆分)
- 5.1 将一个Excel表,按某一列拆分成多张表。
一、相关知识点讲解
1.1 需要使用的相关库
import numpy as np import pandas as pd import os
1.2 os.walk(pwd)
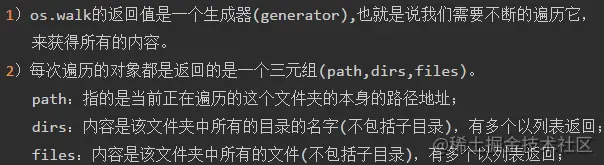
先来看看"G:\a"文件夹下有哪些东西:
代码操作如下:
pwd = "G:\\a" print(os.walk(pwd)) for i in os.walk(pwd): print(i) for path,dirs,files in os.walk(pwd): print(files)
结果如下:
<generator object walk at 0x0000029BB5AEAB88>
('G:\\a', [], ['aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx'])
['aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx']
1.3 os.path.join(path1,path2…)
作用:将多个路径组合后返回
举例如下:
path1 = 'G:\\a' path2 = 'aa.txt' print(os.path.join(path1,path2))
结果如下:
G:\a\aa.txt
1.4 案例解析

举例如下:
pwd = "G:\\a" file_path_list = [] for path,dirs,files in os.walk(pwd): for file in files: file_path_list.append(os.path.join(pwd,file)) print(file_path_list)
结果如下:
['G:\\a\\aa.txt','G:\\a\\bb.xlsx','G:\\a\\cc.txt','G:\\a\\dd.docx']
1.5 如何在一个列表中存放多个 DataFrame 数据
# 先使用如下代码创建两个DataFrame数据源。 import numpy as np xx = np.arange(15).reshape(5,3) yy = np.arange(1,16).reshape(5,3) xx = pd.DataFrame(xx,columns=["语文","数学","外语"]) yy = pd.DataFrame(yy,columns=["语文","数学","外语"]) print(xx) print(yy)
结果如下:
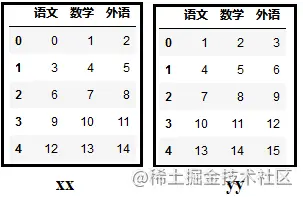
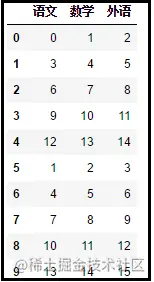
怎么讲上述两个DataFrame拼接在一起?
concat_list = [] concat_list.append(xx) concat_list.append(yy) # pd.concat(list)中【默认axis=0】默认的是数据的纵向合并。 # pd.concat(list)括号中传入的是一个DataFrame列表。 # ignore_list=True表示忽略原有索引,重新生成一组新的索引。 z = pd.concat(concat_list,ignore_list=True) print(z) # 或者直接可以写成z = pd.concat([xx,yy],ignore_list=True)
结果如下:
二、多工作簿合并(一)
2.1 将多个Excel合并到一个Excel中(每个Excel中只有一个sheet表)

操作如下:
import pandas as pd
import os
pwd = "G:\\b"
df_list = []
for path,dirs,files in os.walk(pwd):
for file in files:
file_path = os.path.join(path,file)
df = pd.read_excel(file_path)
df_list.append(df)
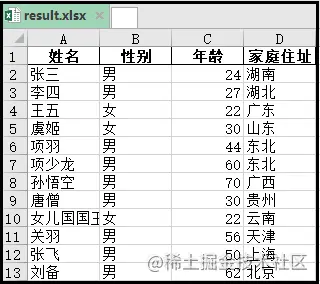
result = pd.concat(df_list)
print(result)
result.to_excel('G:\\b\\result.xlsx',index=False)
结果如下:
三、多工作簿合并(二)
3.1 相关知识点讲解
3.1.1 xlsxwrite 的用法
1)创建一个"工作簿",此时里面会默认生成一个名叫"Sheet1"的Sheet表。
import xlsxwriter
# 这一步相当于创建了一个新的"工作簿";
# "demo.xlsx"文件不存在,表示新建"工作簿";
# "demo.xlsx"文件存在,表示新建"工作簿"覆盖原有的"工作簿";
workbook = xlsxwriter.Workbook("demo.xlsx")
# close是将"工作簿"保存关闭,这一步必须有。否则创建的文件无法显示出来。
workbook.close()
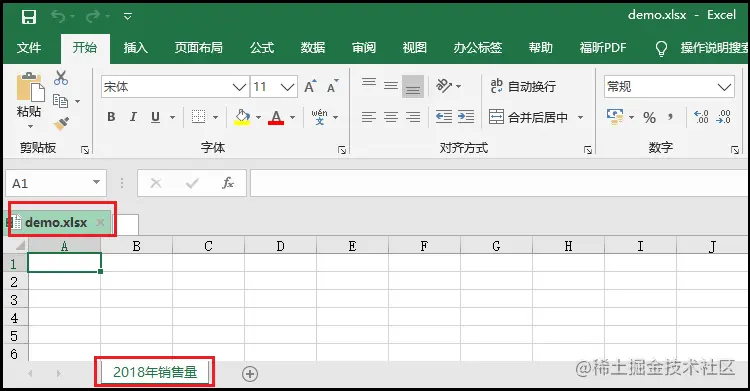
2)创建一个"工作簿"并添加一个"工作表",工作表命名为"2018年销量"。
import xlsxwriter
workbook = xlsxwriter.Workbook("cc.xlsx")
worksheet = workbook.add_worksheet("2018年销售量")
workbook.close()
结果如下:
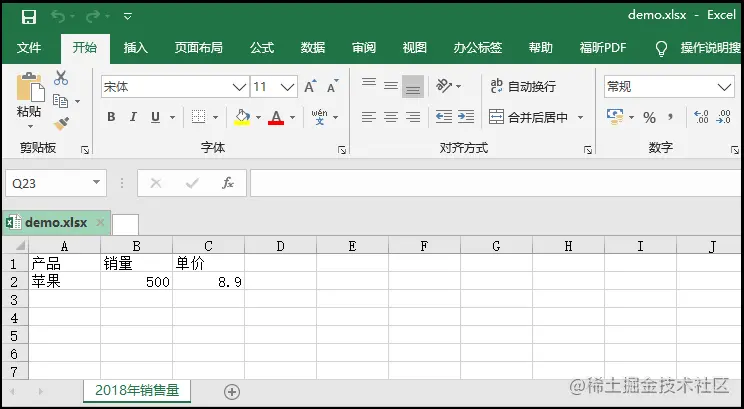
3)给"2018年销售量"工作表创建一个表头,向其中插入一条数据。
import xlsxwriter
# 创建一个名为【demo.xlsx】工作簿;
workbook = xlsxwriter.Workbook("demo.xlsx")
# 创建一个名为【2018年销售量】工作表;
worksheet = workbook.add_worksheet("2018年销售量")
# 使用write_row方法,为【2018年销售量】工作表,添加一个表头;
headings = ['产品','销量',"单价"]
worksheet.write_row('A1',headings)
# 使用write方法,在【2018年销售量】工作表中插入一条数据;
# write语法格式:worksheet.write(行,列,数据)
data = ["苹果",500,8.9]
for i in range(len(headings)):
worksheet.write(1,i,data[i])
workbook.close()
结果如下:
3.1.2 xlrd 的用法

1)打开某一个存在的excel文件,返回给我们"xlrd.book.Book"工作簿对象; # 这里所说的"打开"并不是实际意义上的打开,只是将该表加载到内存中打开。 # 我们并看不到"打开的这个效果" # 以打开上述创建的"test.xlsx"文件为例; import xlrd file = r"G:\Jupyter\test.xlsx" xlrd.open_workbook(file) # 结果如下: <xlrd.book.Book at 0x29bb8e4eda0> 2)sheet_names():获取所有的sheet表表名,假如有多个sheet表,返回一个列表; import xlrd file = r"G:\Jupyter\test.xlsx" fh = xlrd.open_workbook(file) fh.sheet_names() # 结果如下: ['2018年销售量', '2019年销售量'] 3)sheets()方法:返回的是sheet表的对象列表。 # 返回sheet表的对象列表 fh.sheets() # 结果如下: [<xlrd.sheet.Sheet at 0x29bb8f07a90>, <xlrd.sheet.Sheet at 0x29bb8ef1390>] # 可以利用索引,获取每一个sheet表的对象 fh.sheets()[0] 结果是:<xlrd.sheet.Sheet at 0x29bb8f07a90> fh.sheets()[1] 结果是:<xlrd.sheet.Sheet at 0x29bb8ef1390> 4)返回每一个sheet表的行数(nrows) 和 列数(ncols); # 我们可以利用上述创建的sheet表对象,对每一个sheet表进行操作; fh.sheets()[0].nrows # 结果是:4 fh.sheets()[0].ncols # 结果是:3 5)row_values(行数):获取每一个sheet表中每一行的数据; sheet1 = fh.sheets()[0] for row in range(fh.sheets()[0].nrows): value = sheet1.row_values(row) print(value)
结果如下:

6)col_values(列数):获取每一个sheet表中每一列的数据; sheet1 = fh.sheets()[0] for col in range(fh.sheets()[0].ncols): value = sheet1.col_values(col) print(value)
结果如下:

3.2 将多个 Excel 合并到一个 Excel 中(每个 Excel 中不只一个 sheet 表)

import xlrd
import xlsxwriter
import os
# 打开一个Excel文件,创建一个工作簿对象
def open_xlsx(file):
fh=xlrd.open_workbook(file)
return fh
# 获取sheet表的个数
def get_sheet_num(fh):
x = len(fh.sheets())
return x
# 读取文件内容并返回行内容
def get_file_content(file,shnum):
fh=open_xlsx(file)
table=fh.sheets()[shnum]
num=table.nrows
for row in range(num):
rdata=table.row_values(row)
datavalue.append(rdata)
return datavalue
def get_allxls(pwd):
allxls = []
for path,dirs,files in os.walk(pwd):
for file in files:
allxls.append(os.path.join(path,file))
return allxls
# 存储所有读取的结果
datavalue = []
pwd = "G:\\d"
for fl in get_allxls(pwd):
fh = open_xlsx(fl)
x = get_sheet_num(fh)
for shnum in range(x):
print("正在读取文件:"+str(fl)+"的第"+str(shnum)+"个sheet表的内容...")
rvalue = get_file_content(fl,shnum)
# 定义最终合并后生成的新文件
endfile = "G:\\d\\concat.xlsx"
wb1=xlsxwriter.Workbook(endfile)
# 创建一个sheet工作对象
ws=wb1.add_worksheet()
for a in range(len(rvalue)):
for b in range(len(rvalue[a])):
c=rvalue[a][b]
ws.write(a,b,c)
wb1.close()
print("文件合并完成")
将上述代码封装后如下:
import xlrd
import xlsxwriter
import os
class Xlrd():
def __init__(self,pwd):
self.datavalue = []
self.pwd = pwd
# 打开一个Excel文件,创建一个工作簿对象;
def open_xlsx(self,fl):
fh=xlrd.open_workbook(fl)
return fh
# 获取sheet表的个数;
def get_sheet_num(self,fh):
x = len(fh.sheets())
return x
# 读取不同工作簿中每一个sheet中的内容,并返回每行内容组成的列表;
def get_file_content(self,file,shnum):
fh = self.open_xlsx(file)
table=fh.sheets()[shnum]
num=table.nrows
for row in range(num):
rdata=table.row_values(row)
# 因为每一个sheet表都有一个表头;
# 这里的判断语句,把这个表头去除掉;
# 然后在最后写入数据的,添加上一个表头,即可;
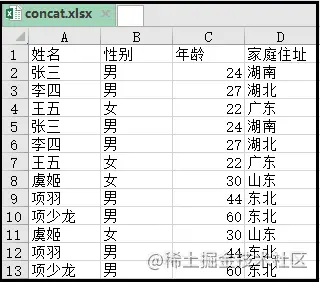
if rdata == ['姓名','性别','年龄','家庭住址']:
pass
else:
self.datavalue.append(rdata)
return self.datavalue
# 获取xlsx文件的全路径;
def get_allxls(self):
allxls = []
for path,dirs,files in os.walk(self.pwd):
for file in files:
allxls.append(os.path.join(path,file))
return allxls
# 返回不同工作簿中,所有的sheet表的内容列表;
def return_rvalue(self):
for fl in self.get_allxls():
fh = self.open_xlsx(fl)
x = self.get_sheet_num(fh)
for shnum in range(x):
print("正在读取文件:"+str(fl)+"的第"+str(shnum)+"个sheet表的内容...")
rvalue = self.get_file_content(fl,shnum)
return rvalue
class Xlsxwriter():
def __init__(self,endfile,rvalue):
self.endfile = endfile
self.rvalue = rvalue
def save_data(self):
wb1 = xlsxwriter.Workbook(endfile)
# 创建一个sheet工作对象;
ws = wb1.add_worksheet("一年级(7)班")
# 给文件添加表头;
ws = wb1.add_worksheet("2018年销售量")
headings = ['姓名','性别','年龄','家庭住址']
for a in range(len(self.rvalue)):
for b in range(len(self.rvalue[a])):
c = self.rvalue[a][b]
# 因为给文件添加了表头,因此,数据从下一行开始写入;
ws.write(a+1,b,c)
wb1.close()
print("文件合并完成")
pwd = "G:\\d"
xl = Xlrd(pwd)
rvalue = xl.return_rvalue()
endfile = "G:\\d\\concat.xlsx"
write = Xlsxwriter(endfile,rvalue)
write.save_data();
结果如下:
四、一个工作簿多 heet 合并
4.1 将一个 Excel 表中的多个 sheet 表合并,并保存到同一个excel。

import xlrd import pandas as pd from pandas import DataFrame from openpyxl import load_workbook excel_name = r"D:\pp.xlsx" wb = xlrd.open_workbook(excel_name) sheets = wb.sheet_names() alldata = DataFrame() for i in range(len(sheets)): df = pd.read_excel(excel_name, sheet_name=i, index=False, encoding='utf8') alldata = alldata.append(df) writer = pd.ExcelWriter(r"C:\Users\Administrator\Desktop\score.xlsx",engine='openpyxl') book = load_workbook(writer.path) writer.book = book # 必须要有上面这两行,假如没有这两行,则会删去其余的sheet表,只保留最终合并的sheet表 alldata.to_excel(excel_writer=writer,sheet_name="ALLDATA") writer.save() writer.close()
结果如下:

五、一表拆分(按照表中某一列进行拆分)
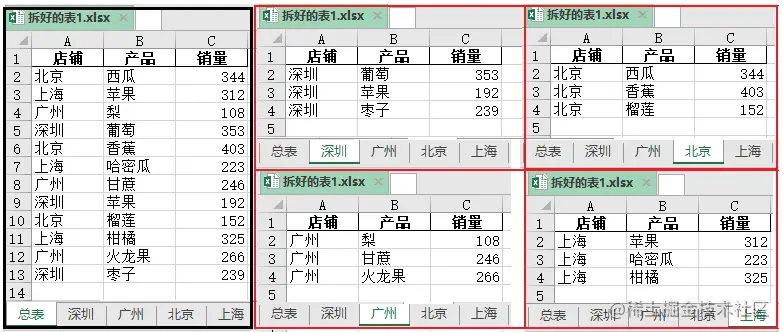
5.1 将一个Excel表,按某一列拆分成多张表。
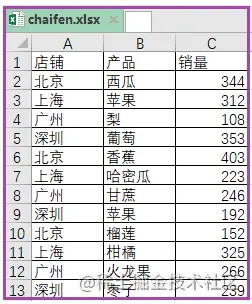
import pandas as pd import xlsxwriter data=pd.read_excel(r"C:\Users\Administrator\Desktop\chaifen.xlsx",encoding='gbk') area_list=list(set(data['店铺'])) writer=pd.ExcelWriter(r"C:\Users\Administrator\Desktop\拆好的表1.xlsx",engine='xlsxwriter') data.to_excel(writer,sheet_name="总表",index=False) for j in area_list: df=data[data['店铺']==j] df.to_excel(writer,sheet_name=j,index=False) writer.save() #一定要加上这句代码,“拆好的表”才会显示出来
结果如下:
到此这篇关于Python 实现多表和工作簿合并及一表按列拆分的文章就介绍到这了,更多相关 Python 表合并内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 合并列表的八种方法
Python 语言里有许多(而且是越来越多)的高级特性,是 Python 发烧友们非常喜欢的.在这些人的眼里,能够写出那些一般开发者看不懂的高级特性,就是高手,就是大神. 但你要知道,在团队合作里,炫技是大忌. 为什么这么说呢?我说下自己的看法: 越简洁的代码,越清晰的逻辑,就越不容易出错: 在团队合作中,你的代码不只有你在维护,降低别人的阅读/理解代码逻辑的成本是一个良好的品德 简单的代码,只会用到最基本的语法糖,复杂的高级特性,会有更多的依赖(如语言的版本) 1. 最直观的相加 使用 + 对
-
Python编程根据字典列表相同键的值进行合并
目录 一.前言 两个列表的数据为: 期望合并的结果 二.实现分析 三.总结 一.前言 今天有粉丝咨询了一个问题,他现在有两个列表,它们的元素都为字典,且字典都有一个key为id,现在想把这两个字典根据id合并为一个字典,类型下面的效果: 两个列表的数据为: a_list = [{'id': 1, 'value': 11}, {'id': 2, 'value': 22}, {'id': 3, 'value': 33}] b_list = [{'id': 1, 'name': 'a'}, {'id'
-
Python3 列表list合并的4种方法
下面是列表合并的4种方法,其中的代码都在Python3下测试通过,在Python2下运行应该也没问题,时间关系就没测试,遇到问题可以联系小编 方法1: 直接使用"+"号合并列表 aList = [1,2,3] bList = ['www', 'jb51.net'] cList = aList + bList dList = bList + aList print(cList) print(dList) 输出为: [1, 2, 3, 'www', 'jb51.net'] ['www',
-
Python合并Excel表(多sheet)的实现
使用xlrd模块和xlwt模块 解题思想:xlwt模块是非追加写.xls的模块,所以要借助for循环和列表,来一次性写入,这样就没有追加与非追加的说法. 而合并Excel表,把每个Excel表当做行,即行合并,换一种想法,把Excel表中的标签当做列,可进行列合并,即合并不同文件中相同标签组成的不同标签,可以先合并不同文件中相同的标签,不同文件的相同标签组成一个列表,后合并前面组成的不同的标签,即可得到所有Excel文件的内容. 源码如下: #导入xlrd和xlwt模块 #xlrd模块是读取.x
-
Python中的字典合并与列表合并技巧
目录 前言 1 合并字典 2 合并列表 前言 又到了每日分享Python小技巧的时候了,今天给大家分享的是Python中两种常见的数据类型合并方法. 1 合并字典 在某些场景下,我们需要对两个(多个)字典进行合并.例如需要将如下两个字典进行合并: dict1 = {"a": 2, "b": 3, "c": 5} dict2 = {"a": 1, "c": 3, "d": 8} 且合并后的
-

教你如何把Python CSV 合并到多个sheet工作表
目标 将多个CSV文件,合并到一个Excel文件中的,多个sheet工作表. 前言 网上大多方法都是将csv直接合并在一起,也不分别创建sheet表. 还有一些解答说CSV不支持合并到多个sheet表. 网上有用宏命令的,我试了,但是只能导入一个sheet表.也有用python的,大多都没什么用. 尽管困难重重,最后终于还是利用pandas库实现了目标. 开始 下面的代码用到了,两个带数据的csv文件.(2019-04-01.csv和2019-04-02.csv) import pandas a
-
python 合并表格详解
编程小白在线学习代码,前几天帮女朋友合并表格cv大佬在线泪目,想想之前合并表格也是一直cv,重复性且效率低下的操作完全可以用代码来实现.就用python写了一个自动合并表格的程序,并且已经打包成了.exe文件,不需要安装py环境就可以直接运行.算是在py下写的第一个程序. 遇到的几大问题 1. 开始pip install 库的时候提升要啥更新(一串英文我也没有看懂),又不影响我安装就没有管,一定要即使更新 2. xlrd这个库,它更新了以后竟然不支持打开.xrlx文件 解决办法为安装老版本pip
-
Python 实现多表和工作簿合并及一表按列拆分
目录 一.相关知识点讲解 1.1 需要使用的相关库 1.2 os.walk(pwd) 1.3 os.path.join(path1,path2…) 1.4 案例解析 1.5 如何在一个列表中存放多个 DataFrame 数据 二.多工作簿合并(一) 2.1 将多个Excel合并到一个Excel中(每个Excel中只有一个sheet表) 三.多工作簿合并(二) 3.1 相关知识点讲解 3.1.1 xlsxwrite 的用法 3.1.2 xlrd 的用法 3.2 将多个 Excel 合并到一个 Ex
-
Python自动化之批量处理工作簿和工作表
一.批量新建并保存工作簿 import xlwings as xw # 导入库 # 启动Excel程序,但不新建工作簿 app = xw.App(visible = True, add_book = False) for i in range(6): workbook = app.books.add() # 新建工作簿 workbook.save(f'e:\\file\\test{i}.xlsx') # 保存新建的多个工作簿 workbook.close() # 关闭当前工作簿 app.quit
-
python利用openpyxl拆分多个工作表的工作簿的方法
实现按目录拆分工作簿,源数据如下图 按目录拆分成N个文件. 上代码,没有找是否有整个sheet 复制的,先逐个cell复制解决问题.: # encoding: utf-8 """ @author: 陈年椰子 @contact: hndm@qq.com @version: 1.0 @file: Split_Xls.py @time: 2019/9/24 0028 15:04 说明 """ def Split_Xls(xls_file): from
-
Python批量处理工作簿和工作表的实现示例
目录 批量新建并保存工作簿 批量打开一个文件夹中的打开工作簿 批量重命名一个工作簿的所有工作表 批量重命名多个工作簿 批量重命名多个工作簿中的同名工作表 将一个工作簿的所有工作表批量复制到其他工作簿 按条件将一个工作表拆分为多个工作簿 批量新建并保存工作簿 代码 import xlwings as xw # 启动 Excel,但不新建工作簿 app = xw.App(visible=True,add_book=False) for i in range(5): #新建工作簿 workbook =
-
使用python创建Excel工作簿及工作表过程图解
1 配置信息: 创建 excel 工作簿之前的路径 2 创建工作簿 创建工作簿之后的路径 工作簿内容 3 创建工作表 工作簿信息 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们.
-
Python操作Excel工作簿的示例代码(\*.xlsx)
前言 Excel 作为流行的个人计算机数据处理软件,混迹于各个领域,在程序员这里也是常常被处理的对象,可以处理 Excel 格式文件的 Python 库还是挺多的,比如 xlrd.xlwt.xlutils.openpyxl.xlwings 等等,但是每个库处理 Excel 的方式不同,有些库在处理时还会有一些局限性. 接下来对比一下几个库的不同,然后主要记录一下 xlwings 这个库的使用,目前这是个人感觉使用起来比较方便的一个库了,其他的几个库在使用过程中总是有这样或那样的问题,不过在特定情
-
python实现跨excel的工作表sheet之间的复制方法
python,将test1的Sheet1通过"跨文件"复制到test2的Sheet2里面. 包括谷歌没有能搜出这种问题答案. 我们贴出代码. 我们加载openpyxl这个包来解决: from openpyxl import load_workbook filename = 'test1.xlsx' filename2 = 'test2.xlsx' def replace_xls(sheetname): wb = load_workbook(filename) wb2 = load_wo
-
Python如何把多个PDF文件合并代码实例
这篇文章主要介绍了Python如何把多个PDF文件合并,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 from PyPDF2 import PdfFileMerger import os files = os.listdir()#列出目录中的所有文件 merger = PdfFileMerger() for file in files: #从所有文件中选出pdf文件合并 if file[-4:] == ".pdf": mer
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有
-
Python实现将sqlite数据库导出转成Excel(xls)表的方法
本文实例讲述了Python实现将sqlite数据库导出转成Excel(xls)表的方法.分享给大家供大家参考,具体如下: 1. 假设已经安装带有sliqte 库的Python环境 我的是Python2.5 2. 下载 python xls 写操作包(xlwt)并安装 下载地址: http://pypi.python.org/pypi/xlwt 3. 下面就是代码(db2xls.py): import sqlite3 as sqlite from xlwt import * #MASTER_COL