go语言实现二叉树的序例化与反序列化
目录
- 二叉树的反序列化
- 反序列化
- 解题思路
- TreeNode结构体
- 反序列化方法
- 代码解读
- 二叉树的序列化
- 介绍
- 解题思路
- 代码
- 代码解读
- 运行结果
二叉树的反序列化
反序列化
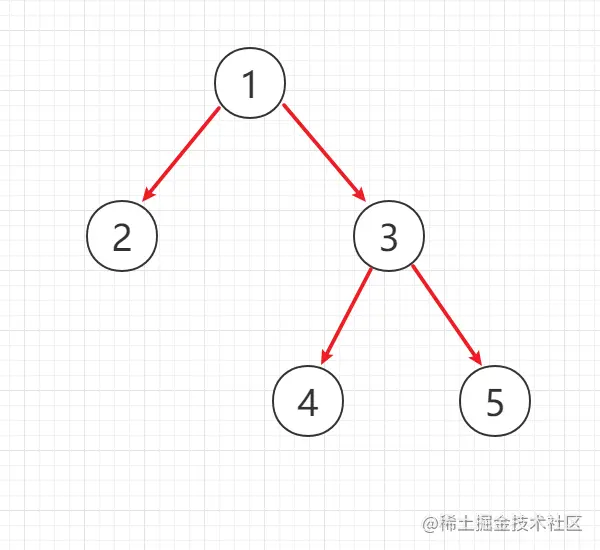
树的反序列化故名知意就是将一个序列化成字符串或者其它形式的数据重新的生成一颗二叉树,如下这颗二叉树将它序列化成字符串后的结果[5,4,null,null,3,2,1],而现在要做的是要将这个字符串重新的生成一颗二叉树(生成下面这颗树,因为这个字符串就是通过这颗树序列化来的)。
解题思路
- 首先,应该先拿到一个序列化后数据,可能是队列、栈、字符串(中间会有字符将其分割),或其它形式的数据
- 当一个节点下面没有数据的时候,我这里采用的是用
null来表示的空,比如上面节点2下面没有数据,在字符串中就用了null来表示 - 这里我将字符串转换成了队列的形式,当然使用字符串的形式也可以的,例如:通过
split方法来分割成数组 - 创建一个队列,把要进行处理的节点放和主到队列里面,比如,每次循环的时候将左右分支放到这个队列里面,因为队列有
FIFO的特性,在处理完左支的时候能够放便的拿到右支的node - 接下来分析代码
TreeNode结构体
这个里面的数据很容易就看懂,val是当前节点的数据;left ,right分别保存的是左支和右支的数据
针对每个数据生成对应的TreeNode
func GenerateNode(str string) *TreeNode {
if str == "null" {
return nil
}
return &TreeNode{val: str}
}
这个方法主要是生成TreeNode对象的方法,上面说到当节点下面没有子节点的时候就会用null来表不,所以这里接收到的形参如果是null的话就会反回一个空指针,相反如果不是null就会反回一个创建的TreeNode对象,并将val属性赋值
反序列化方法
func DeserializationTb(dataQueue []string) (resultNode *TreeNode) {
if len(dataQueue) == 0 {
return nil
}
var tempNodeQueue []*TreeNode
resultNode = generateNode(dataQueue[len(dataQueue) - 1])
dataQueue = dataQueue[:len(dataQueue) - 1]
if resultNode != nil {
tempNodeQueue = append(tempNodeQueue,resultNode)
}
var tempNode *TreeNode
for len(tempNodeQueue) != 0 {
tempNode = tempNodeQueue[0]
tempNodeQueue = tempNodeQueue[1:]
if len(dataQueue) > 0 {
tempNode.left = generateNode(dataQueue[len(dataQueue) - 1])
dataQueue = dataQueue[:len(dataQueue) - 1]
tempNode.right = generateNode(dataQueue[len(dataQueue) - 1])
dataQueue = dataQueue[:len(dataQueue) - 1]
}
if tempNode.left != nil {
tempNodeQueue = append(tempNodeQueue,tempNode.left)
}
if tempNode.right != nil {
tempNodeQueue = append(tempNodeQueue,tempNode.right)
}
}
return
}
代码解读
这个方法的代码比较多,这里就会块来说一下:
if len(dataQueue) == 0 {
return nil
}
这几行代码无非就是一个边界条件的判断的问题,当传来的队列没有数据的时候就返回一个空,为啥是队列?因为我将字符串转成了队列
var tempNodeQueue []*TreeNode
resultNode = generateNode(dataQueue[len(dataQueue) - 1])
dataQueue = dataQueue[:len(dataQueue) - 1]
if resultNode != nil {
tempNodeQueue = append(tempNodeQueue,resultNode)
}
var tempNodeQueue []*TreeNode:这里创建一个TreeNode指针数组的原因是存储要操作节点的数据,因为我将序列化后的数据转成了队列,所以在这个数组中最后一个元素应该是先出来的数组,同样第一个出来的数据是这颗二叉树的根节点,将这个节点保存到了这个队列里面,然后这个队列将在下面的for循环中使用到,其余的下面再说.
resultNode = generateNode(dataQueue[len(dataQueue) - 1]):这里便是将出队列,并通过generateNode生成一个TreeNode对象
dataQueue = dataQueue[:len(dataQueue) - 1]:因为有一个数组已经出了队列,就要将其去掉
tempNodeQueue = append(tempNodeQueue,resultNode):经过一个判空处理,便将这个节点保存到了上面提到的队列里面
for len(tempNodeQueue) != 0 {
tempNode = tempNodeQueue[0]
tempNodeQueue = tempNodeQueue[1:]
if len(dataQueue) > 0 {
tempNode.left = generateNode(dataQueue[len(dataQueue) - 1])
dataQueue = dataQueue[:len(dataQueue) - 1]
tempNode.right = generateNode(dataQueue[len(dataQueue) - 1])
dataQueue = dataQueue[:len(dataQueue) - 1]
}
if tempNode.left != nil {
tempNodeQueue = append(tempNodeQueue,tempNode.left)
}
if tempNode.right != nil {
tempNodeQueue = append(tempNodeQueue,tempNode.right)
}
}
当进入For循环后,也就证明现在这个队列里面有数据,不管三七二十一,先将里面的数据弹出,因为只有有了数据才可以进行下面的操作(无数据,不编程)
tempNodeQueue = tempNodeQueue[1:]:因为前一行代码将数据在这个队列里面弹出了, 所以一行代码是将已弹出的数据去除
tempNode.left = generateNode(dataQueue[len(dataQueue) - 1]):当传来序列化二叉树的存在数据的时候就将其节点的left , right分支进么赋值,下一行代码就是将弹出的数据去除,接下来的两行便是对right节点的处理,同left一样
tempNodeQueue = append(tempNodeQueue,tempNode.left):如果tempNode的左节点存在的时候就将其保存到队列中,遍历tempNodeQueue队列,再次执行上面的步骤.
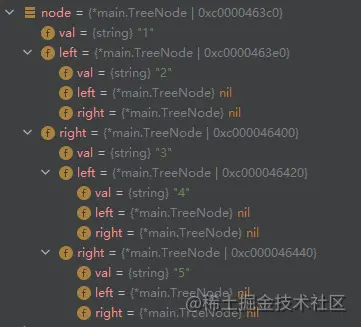
可能有小伙伴存在疑问?
所返回的resultNode变量只赋值过一次,那子节点是如何赋值的呢?因为所有的TreeNode的节点我都是通过指针来处理的,
而在For里面的第一行代码所弹出的数据指向的地址正是resultNode的地址,所以在生成完树之后,我只要抓住这颗树的根节点就好了
二叉树的序列化
介绍
树的序列化又是怎么一回事呢?我可以将这颗树转换成一定格式的数据结构,比如:转换成一段文本可以持久化到硬盘中。
那有什么作用呢?比如Redis中的数据是在内存中的,它有一个功能是每隔一段 时间可以将数据保存到硬盘中以防止突发的断电导至数据的丢失
这里说的树的序列化你也可以这样的理解,我要将一颗二叉树里面的数据序列化保存到硬盘,以便下次使用这里面的数的据的时候可以直接生成这颗树
解题思路
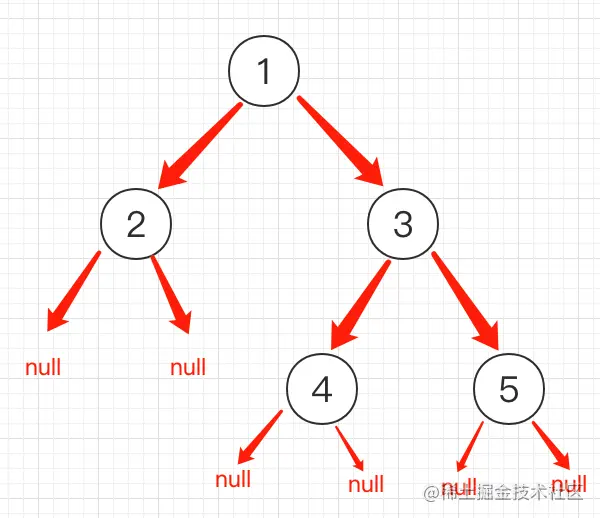
- 参于解这种题,想到的是通过对二叉树的按层来遍历来解决,当一个节点没有子节点的时候,将其视为空, 我这里用
null来表示的 - 在这个里面序列化时我是先处理的左子节点,然后在处理右子节点
- 同反序列化一样,暂存数据的结构我使用的是队列的方式,还需要将获得的数据也要保存到一个队列里面
- 在程序的开始如果所给的头节点不为空,就将头节点加入到队列
- 在对队列遍历的时候弹出队列里面的数据(注:队列有FIFO的特性),将本节点的val放到保存数据的队列里面
- 依次将本节点的左子节点和右子节点放到队列里面,在次执行上述步骤
代码
/**
序列化二叉树
*/
func SerializationTb(bt *TreeNode) (saveSerData []string) {
root := bt
var tempQueue []*TreeNode
if root != nil {
tempQueue = append(tempQueue, root)
}
var tempNode *TreeNode
for len(tempQueue) != 0 {
tempNode = tempQueue[0]
if tempNode != nil {
saveSerData = append(saveSerData, tempNode.val)
} else {
saveSerData = append(saveSerData, "null")
}
tempQueue = tempQueue[1:]
if tempNode != nil {
tempQueue = append(tempQueue, tempNode.left)
tempQueue = append(tempQueue, tempNode.right)
}
}
return
}
代码解读
这些代码还是很好看懂的,这里就说下for里面的代码吧~~
tempNode = tempQueue[0]:在队列里面弹出一个数据
saveSerData = append(saveSerData, tempNode.val):将tempNode的val属性保存到saveSerData队列里面
下面的if就是判断当这个节点为空或者是不为空的时候需要分别怎么处理数据,上面说到如果一个节点下面没有子节点,这里就用null来表示,所以当没有子节点的时候就用将null添加到队列里面
tempQueue = tempQueue[1:]:对队列重新赋值,将弹出的那个数据去掉
tempQueue = append(tempQueue, tempNode.left):将左节点加入到队列里面,下一行同理
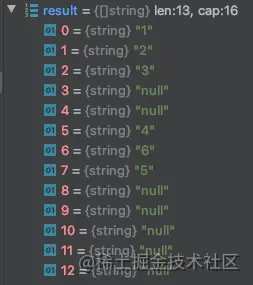
运行结果
到此这篇关于go语言实现二叉树的序例化与反序列化的文章就介绍到这了,更多相关go序例化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Go 数据结构之二叉树详情
目录 Go 语言实现二叉树 定义二叉树的结构 二叉树遍历 创建二叉树 插入值 测试 前言: 树可以有许多不同的形状,并且它们可以在每个节点允许的子节点数量或它们在节点内组织数据值的方式上有所不同. 而在其中最常用的树之一是二叉树. 二叉树是一棵树,其中每个节点最多可以有两个孩子. 一个孩子被识别为左孩子,另一个孩子被识别为右孩子. 二叉树是一种数据结构,在每个节点下面最多存在两个其他节点.即一个节点要么连接至一个.两个节点或不连接其他节点. 树形结构的深度(也被称作高度)则被定义为根节点为根节点
-
利用go语言实现查找二叉树中的最大宽度
目录 介绍 流程 代码 二叉树结构体 测试代码 查找二叉树最大宽度的代码 代码解读 介绍 这道题是这样的,有一个二叉树,让求出这颗Bt树里面最大的宽度是有几个节点,同时还要求出最大宽度的这些节点在第几层? 比如:下面这颗树,它每层最大的宽度是3,所在的层数是在第3层 流程 这个题主要是使用队列的方式来存储需要遍历的节点 同时还需要几个变量来存储最大的宽度(maxWidth).每层有几个节点(count).最大宽度所在的层(maxInrow).当前层最后一个节点(currentRowEndNode
-
详解Go语言如何实现二叉树遍历
目录 1. 二叉树的定义 2. 前序遍历 3. 中序遍历 4. 后序遍历 1. 二叉树的定义 二叉树需满足的条件 ① 本身是有序树 ② 树中包含的各个节点的长度不能超过2,即只能是0.1或者2 2. 前序遍历 前序遍历二叉树的顺序:根——>左——>右 package main import "fmt" //定义结构体 type Student struct { Name string Age int Score float32 left *Student //左子树指针 r
-
利用go语言判断是否是完全二叉树
目录 一.什么是完全二叉树? 二.流程 三.代码 1.树节点 2.测试代码 3.判断树是否为完全二叉树代码 4.代码解读 5.运行结果 一.什么是完全二叉树? 先看如下这一张图: 这个一颗二叉树,如何区分该树是不是完全二叉树呢? 当一个节点存在右子节点但是不存在左子节点这颗树视为非完全二叉树 当一个节点的左子节点存在但是右子节点不存在视为完全二叉树 如果没有子节点,那也是要在左侧开始到右侧依次没有子节点才视为完全二叉树,就像上图2中 而上面第一张图这颗二叉树很明显是一颗非完全二叉树,因为在第三层
-
go语言实现二叉树的序例化与反序列化
目录 二叉树的反序列化 反序列化 解题思路 TreeNode结构体 反序列化方法 代码解读 二叉树的序列化 介绍 解题思路 代码 代码解读 运行结果 二叉树的反序列化 反序列化 树的反序列化故名知意就是将一个序列化成字符串或者其它形式的数据重新的生成一颗二叉树,如下这颗二叉树将它序列化成字符串后的结果[5,4,null,null,3,2,1],而现在要做的是要将这个字符串重新的生成一颗二叉树(生成下面这颗树,因为这个字符串就是通过这颗树序列化来的). 解题思路 首先,应该先拿到一个序列化后数据,
-
C语言数据结构二叉树先序、中序、后序及层次四种遍历
目录 一.图示展示 (1)先序遍历 (2)中序遍历 (3)后序遍历 (4)层次遍历 (5)口诀 二.代码展示 一.图示展示 (1)先序遍历 先序遍历可以想象为,一个小人从一棵二叉树根节点为起点,沿着二叉树外沿,逆时针走一圈回到根节点,路上遇到的元素顺序,就是先序遍历的结果 先序遍历结果为:A B D H I E J C F K G 动画演示: 记住小人沿着外围跑一圈(直到跑回根节点),多看几次动图便能理解 (2)中序遍历 中序遍历可以看成,二叉树每个节点,垂直方向投影下来(可以理解为每个节点从最
-
C语言非递归后序遍历二叉树
本文实例为大家分享了C语言非递归后序遍历二叉树的具体代码,供大家参考,具体内容如下 法一:实现思路:一个栈 先按 根->右子树->左子树的顺序访问二叉树.访问时不输出.另一个栈存入前一个栈只进栈的结点. 最后输出后一个栈的结点数据. #include<stdio.h> #include<stdlib.h> typedef struct TreeNode{ char element; struct TreeNode *left,*right; }Tree,*BTree;
-
Verilog语言关键字模块例化实例讲解
目录 关键字:例化,generate,全加器,层次访问 命名端口连接 顺序端口连接 端口连接规则 用 generate 进行模块例化 层次访问 关键字:例化,generate,全加器,层次访问 在一个模块中引用另一个模块,对其端口进行相关连接,叫做模块例化.模块例化建立了描述的层次.信号端口可以通过位置或名称关联,端口连接也必须遵循一些规则. 命名端口连接 这种方法将需要例化的模块端口与外部信号按照其名字进行连接,端口顺序随意,可以与引用 module 的声明端口顺序不一致,只要保证端口名字与外
-
C语言线索二叉树基础解读
目录 线索二叉树的意义 线索二叉树的定义 线索二叉树结构的实现 二叉树的线索存储结构 二叉树的中序线索化 线索二叉树的中序遍历 总结 线索二叉树的意义 对于一个有n个节点的二叉树,每个节点有指向左右孩子的指针域.其中会出现n+ 1个空指针域,这些空间不储存任何事物,浪费着内存的资源. 对于一些需要频繁进行二叉树遍历操作的场合,二叉树的非递归遍历操作过程相对比较复杂,递归遍历虽然简单明了,但是会有额外的开销,对于操作的时间和空间都比较浪费. 我们可以考虑利用这些空地址,存放指向节点在某种遍历次序下
-
C语言实现二叉树遍历的迭代算法
本文实例讲述了C语言实现二叉树遍历的迭代算法,是数据结构算法中非常经典的一类算法.分享给大家供大家参考. 具体实现方法如下: 二叉树中序遍历的迭代算法: #include <iostream> #include <stack> using namespace std; struct Node { Node(int i, Node* l = NULL, Node* r = NULL) : item(i), left(l), right(r) {} int item; Node* le
-
C语言数据结构二叉树简单应用
C语言数据结构二叉树简单应用 在计算机科学中,二叉树是每个节点最多有两个子树的树结构.通常子树被称作"左子树"(left subtree)和"右子树"(right subtree),接下来我就在这里给大家介绍一下二叉树在算法中的简单使用: 我们要完成总共有 (1)二叉树的创建 (2)二叉树的先中后序递归遍历 (3)统计叶子结点的总数 (4)求树的高度 (5)反转二叉树 (6)输出每个叶子结点到根节点的路径 (7)输出根结点到每个叶子结点的路径. 定义二叉树结点类型
-
C语言实现二叉树的搜索及相关算法示例
本文实例讲述了C语言实现二叉树的搜索及相关算法.分享给大家供大家参考,具体如下: 二叉树(二叉查找树)是这样一类的树,父节点的左边孩子的key都小于它,右边孩子的key都大于它. 二叉树在查找和存储中通常能保持logn的查找.插入.删除,以及前驱.后继,最大值,最小值复杂度,并且不占用额外的空间. 这里演示二叉树的搜索及相关算法: #include<stack> #include<queue> using namespace std; class tree_node{ public
-
C语言实现二叉树的基本操作
二叉树是一种非常重要的数据结构.本文总结了二叉树的常见操作:二叉树的构建,查找,删除,二叉树的遍历(包括前序遍历.中序遍历.后序遍历.层次遍历),二叉搜索树的构造等. 1. 二叉树的构建 二叉树的基本构建方式为:添加一个节点,如果这是一棵空树,则将该节点作为根节点:否则按照从左到右.先左子树后右子树的顺序逐个添加节点.比如依次添加节点:1,6,10,2,7,11,则得到的二叉树为: 在这里,我们需要借助一个链表来保存节点,以实现二叉树的顺序插入,具体做法如下: 1.0 初始化一个用来保存二叉树节
-
C语言数据结构二叉树之堆的实现和堆排序详解
目录 一.本章重点 二.堆 2.1堆的介绍 2.2堆的接口实现 三.堆排序 一.本章重点 堆的介绍 堆的接口实现 堆排序 二.堆 2.1堆的介绍 一般来说,堆在物理结构上是连续的数组结构,在逻辑结构上是一颗完全二叉树. 但要满足 每个父亲节点的值都得大于孩子节点的值,这样的堆称为大堆. 每个父亲节点的值都得小于孩子节点的值,这样的堆称为小堆. 那么以下就是一个小堆. 百度百科: 堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆. 若将和此次序列对应的一维数