python爬取酷狗音乐Top500榜单
目录
- 网页情况
- python 代码
- 运行效果
- 总结
网页情况
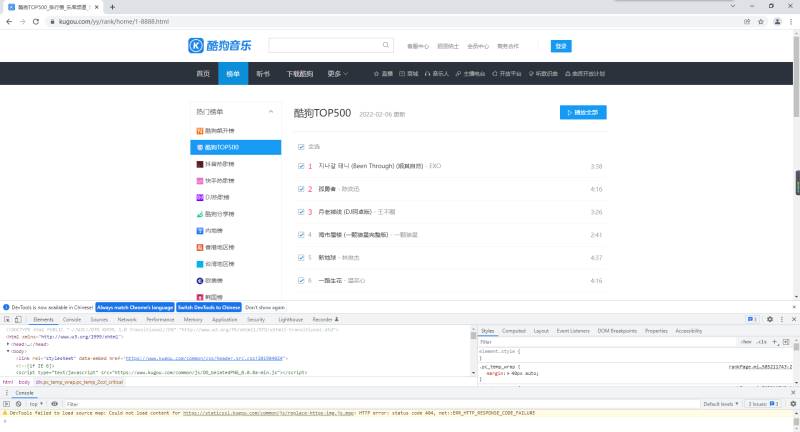
爬取数据包含
歌曲排名、歌手、歌曲名、歌曲时长
python 代码
import requests #请求网页获取网页数据
from bs4 import BeautifulSoup #解析网页数据
import time #时间库
#user-Agent,伪装成浏览器,便于爬虫的稳定性
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
}
def get_info(url):
web_data = requests.get(url,headers= headers)
soup = BeautifulSoup(web_data.text,'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
"rank":rank.get_text().strip(),
"singer":title.get_text().replace("\n","").replace("\t","").split('-')[1],
"song":title.get_text().replace("\n","").replace("\t","").split('-')[0],
"time":time.get_text().strip()
}
print(data)
if __name__ == '__main__':
urls = ["https://www.kugou.com/yy/rank/home/{}-8888.html".format(str(i)) for i in range(1,24)]
for url in urls:
get_info(url)
time.sleep(1)
运行效果


总结
到此这篇关于python爬取酷狗音乐Top500榜单的文章就介绍到这了,更多相关python爬取酷狗音乐榜单内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python获取酷狗音乐top500的下载地址 MP3格式
下面先给大家介绍下python获取酷狗音乐top500的下载地址 MP3格式,具体代码如下所示: # -*- coding: utf-8 -*- # @Time : 2018/4/16 # @File : kugou_top500.py # @Software: PyCharm # @pyVer : python 2.7 import requests,json headers={ 'UserAgent' : 'Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 lik
-
python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下 #coding=utf-8 from pymongo import MongoClient import time import requests from lxml import etree client = MongoClient() #连接mongo hello = client.hello #连接数据库 user = hello.song #连接表 headers = { 'User-Agent': 'M
-
Python反爬实战掌握酷狗音乐排行榜加密规则
目录 效果展示 爬取目标 工具使用 项目思路解析 简易源码分享 效果展示 爬取目标 网址:酷我音乐 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,re 项目思路解析 找到需要解析的榜单数据 随意点击一个歌曲获取到音乐的详情数据 通过抓包的方式获取到音乐播放数据 找到MP3的数据提交地址 mp3数据来自于这个url地址 提交数据的网址: https://wwwapi.kugou.com/yy/index.php?r=play/
-
python爬取酷狗音乐Top500榜单
目录 网页情况 python 代码 运行效果 总结 网页情况 爬取数据包含 歌曲排名.歌手.歌曲名.歌曲时长 python 代码 import requests #请求网页获取网页数据 from bs4 import BeautifulSoup #解析网页数据 import time #时间库 #user-Agent,伪装成浏览器,便于爬虫的稳定性 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64;
-
python使用beautifulsoup4爬取酷狗音乐代码实例
这篇文章主要介绍了python使用beautifulsoup4爬取酷狗音乐代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, 安装方法:pip install beautifulsoup4 完整代码如下:双击就能直接运行 from bs4 import BeautifulSoup
-
Python爬取酷狗MP3音频的步骤
分析问题 音频url 点入某个音乐的播放界面,通过F12-Network,分析数据,可以看到有一个index.php?..返回数据中有一个play_url,打开后正是我们需要的音频. 查看该url的headers,其params参数如下,通过反复不同的几次尝试,得知r.callback.dfid.mid.platid这几项不变,而通过初步的requests尝试,发现最后一项'_'可有可无,改变的只有hash和album_id两项. r: play/getdata callback: jQuery
-
python爬取网易云音乐热歌榜实例代码
首先找到要下载的歌曲排行榜的链接,这里用的是: https://music.163.com/discover/toplist?id=3778678 然后更改你要保存的目录,目录要先建立好文件夹,例如我的是保存在D盘-360下载-网易云热歌榜文件夹内,就可以完成下载. 如果文件夹没有提前建好,会报错[Errno 2] No such file or directory. 代码实现: from urllib import request from bs4 import BeautifulSoup i
-
教你如何使Python爬取酷我在线音乐
目录 前言 获取歌曲信息列表 请求参数分析 请求代码 获取歌曲下载链接 免费歌曲 付费歌曲 请求代码 后记 前言 写这篇博客的初衷是加深自己对网络请求发送和响应的理解,仅供学习使用,请勿用于非法用途!文明爬虫,从我做起.下面进入正题. 获取歌曲信息列表 在酷我的搜索框中输入关键词 aiko,回车之后可以看到所有和 aiko 相关的歌曲.打开开发者模式,在网络面板下按下 ctrl + f,搜索 二人,可以找到响应结果中包含 二人 的请求,这个请求就是用来获取歌曲信息列表的. 请求参数分析 请求的具
-
python爬取网易云音乐排行榜实例代码
目录 网易云音乐排行榜歌曲及评论爬取 一.模拟登录 二.排行榜数据爬取 三.排行榜评论获取 总结 网易云音乐排行榜歌曲及评论爬取 主要注意问题:selenium 模拟登录.iframe标签定位.页面元素提取. 在利用selenium定位元素并取值的过程中遇到问题.比如xpath正确但无法定位,在进行翻页提取评论的过程中,利用selenium似乎不能提取不同页的数据,比如,明明定位的第三页的评论数据,而只能返回第一页的评论数据. 一.模拟登录 selenium 定位元素模拟人的操作进行登录,直接上
-
python爬取网易云音乐评论
本文实例为大家分享了python爬取网易云音乐评论的具体代码,供大家参考,具体内容如下 import requests import bs4 import json def get_hot_comments(res): comments_json = json.loads(res.text) hot_comments = comments_json['hotComments'] with open("hotcmments.txt", 'w', encoding = 'utf-8') a
-
Python爬取网易云音乐上评论火爆的歌曲
前言 网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论.但是,网易云音乐并没有提供热评排行榜和按评论排序的功能,没关系,本文就使用爬虫给大家爬一爬网易云音乐上那些热评的歌曲. 结果 对过程没有兴趣的童鞋直接看这里啦. 评论数大于五万的歌曲排行榜 首先恭喜一下我最喜欢的歌手(之一)周杰伦的<晴天>成为网易云音乐第一首评论数过百万的歌曲! 通过结果发现目前评论数过十万的歌曲正好十首,通过这