Mysql读写分离过期常用解决方案
mysql读写分离的坑
读写分离的主要目标是分摊主库的压力,由客户端选择后端数据库进行查询。还有种架构就是在MYSQL和客户端之间有一个中间代理层proxy,客户端之连接proxy,由proxy根据请求类型和上下文决定请求的分发路由。
- 客户端直连方案:因为少了一层proxy转发,所以查询性能稍微好一点儿,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。
- 带proxy架构:对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由proxy完成的。但这样的话,对后端维护团队的要求会更高。
无论使用哪种架构,由于主从可能存在延迟,客户端执行完一个更新事务后马上发起查询,如果查询选择的是从库的话,就有可能读到刚刚的事务更新之前的状态。这种“在从库上会读到系统的一个过期状态”的现象,我们暂且称之为“过期读”。
方案一:强制走主库方案
将查询请求分为两类:
- 对于必须要拿到最新结果的请求,强制将其发到主库上。比如,在一个交易平台上,卖家发布商品以后,马上要返回主页面,看商品是否发布成功。那么,这个请求需要拿到最新的结果,就必须走主库。
- 对于可以读到旧数据的请求,才将其发到从库上。在这个交易平台上,买家来逛商铺页面,就算晚几秒看到最新发布的商品,也是可以接受的。那么,这类请求就可以走从库。这个方案的最大问题在于会碰到所有查询都不是“过期读”的需求,比如金融类业务,这样就要放弃读写分离,所有的压力都在主库。采用以下方案。
方案二:Sleep方案
主库更新后,读从库之前先sleep一下,类似执行了select sleep(1)命令,这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以有很大概率拿到最新的数据。
以卖家发布商品为例,商品发布后,用Ajax直接把客户端输入的内容作为“新的商品”显示在页面上,而不是真正地去数据库做查询。这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题。
方案三:判断主备无延迟方案:
第一种方法:先用show slave status结果里的seconds_behind_master参数的值,可以用来衡量主备延迟时间的长短。先判断这个参数值是否为0,如果不为0,必须等到这个参数变为0才能执行请求。
第二种方法:对比位点确保主备无延迟。
- Master_Log_File和Read_Master_Log_Pos,表示的是读到的主库的最新位点;
- Relay_Master_Log_File和Exec_Master_Log_Pos,表示的是备库执行的最新位点。
如果Master_Log_File和Relay_Master_Log_File、Read_Master_Log_Pos和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成。
第三种方法:对比GTID(全局事物ID)确保主备无延迟
- Auto_Position=1 ,表示这对主备关系使用了GTID协议。
- Retrieved_Gtid_Set,是备库收到的所有日志的GTID集合;
- Executed_Gtid_Set,是备库所有已经执行完成的GTID集合。
如果这两个集合相同,表示备库接收到的日志都已经同步完成。
方案四:等主库位点方案
select master_pos_wait(file, pos[, timeout]);
这条命令是在从库执行的 ,参数file和pos指的是主库上的文件名和位置,timeout表示这个函数最多等待N秒。
- 这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务。
- 如果备库同步线程发生异常,则返回null
- 如果等待超过N秒,就返回-1
- 如果刚开始执行就发现已经执行过了,则返回0
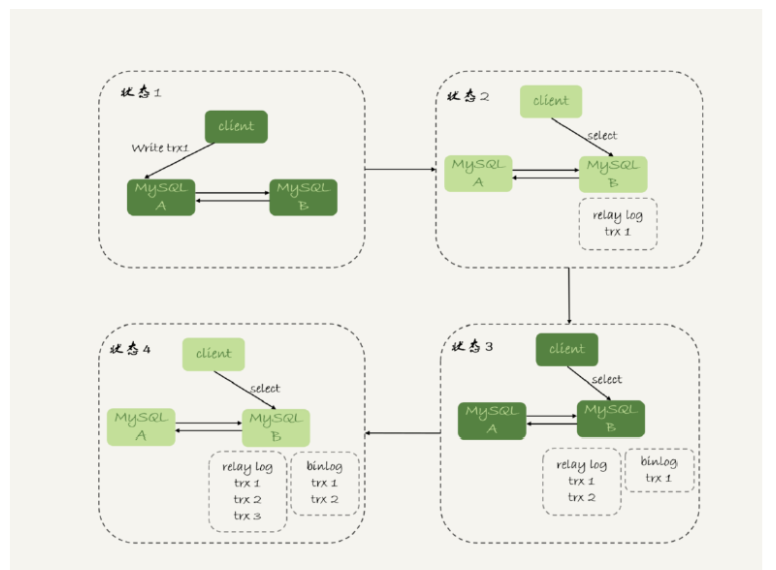
如图:先执行trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,我们可以使用
这个逻辑
1. trx1事物更新完成后,马上执行show master status得到当前主库执行到的File和Position;
2. 选定一个从库执行查询语句;
3. 在从库上执行select master_pos_wait(File, Position, 1);
4. 如果返回值是>=0的正整数,则在这个从库执行查询语句;
5. 否则,到主库执行查询语句。
这里我们假设,这条select查询最多在从库上等待1秒。那么,如果1秒内master_pos_wait返回
一个大于等于0的整数,就确保了从库上执行的这个查询结果一定包含了trx1的数据。
5到主库执行查询语句,是这类方案常用的退化机制。因为从库的延迟时间不可控,不能无
限等待,所以如果等待超时,就应该放弃,然后到主库去查。按照我们设定不允许过期读的要求,就只有两种选择,一种是超时放弃,一种是转到主库查询。
并发连接和并发查询
innodb_thread_concurrency参数是控制innodb的并发线程上限。一旦超过这个数值,新请求就会进入等待。
- show processlist看到的几千个连接,是值并发连接,而当前正在执行的语句,才是并发查询。并发连接影响不大,只是会多占内存,而并发查询才是CPU杀手。
- 在线程进入锁等待以后,并发线程的计数会建议,也就是等行锁的线程是不算在并发查询里的。因为所等待已经不吃CPU了
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
基于mysql+mycat搭建稳定高可用集群负载均衡主备复制读写分离操作
数据库性能优化普遍采用集群方式,oracle集群软硬件投入昂贵,今天花了一天时间搭建基于mysql的集群环境. 主要思路 简单说,实现mysql主备复制-->利用mycat实现负载均衡. 比较了常用的读写分离方式,推荐mycat,社区活跃,性能稳定. 测试环境 MYSQL版本:Server version: 5.5.53,到官网可以下载WINDWOS安装包. 注意:确保mysql版本为5.5以后,以前版本主备同步配置方式不同. linux实现思路类似,修改my.cnf即可. A主mysql.19
-
springboot基于Mybatis mysql实现读写分离
近日工作任务较轻,有空学习学习技术,遂来研究如果实现读写分离.这里用博客记录下过程,一方面可备日后查看,同时也能分享给大家(网上的资料真的大都是抄来抄去,,还不带格式的,看的真心难受). 完整代码:https://github.com/FleyX/demo-project/tree/master/dxfl 1.背景 一个项目中数据库最基础同时也是最主流的是单机数据库,读写都在一个库中.当用户逐渐增多,单机数据库无法满足性能要求时,就会进行读写分离改造(适用于读多写少),写操作一个库,读操作多个库
-
PHP实现的mysql读写分离操作示例
本文实例讲述了PHP实现的mysql读写分离操作.分享给大家供大家参考,具体如下: 首先mysql主从需配置好,基本原理就是判断sql语句是否是select,是的话走master库,否则从slave查 <?php /** * mysql读写分离 */ class db{ public function __construct($sql){ $chestr = strtolower(trim($sql)); //判断sql语句有select关键字的话,就连接读的数据库,否则就连接写数据库 if(s
-
PHP+MYSQL实现读写分离简单实战
1.Introduction 之前写过2篇文章,分别是: Mysql主从同步的原理 Myql主从同步实战 基于此,我们再实现简单的PHP+Mysql读写分离,从而提高数据库的负载能力. 2.代码实战 <?php class Db { private $res; function __construct($sql) { $querystr = strtolower(trim(substr($sql,0,6))); //如果是select,就连接slave服务器 if($querystr == 's
-
Springboot + Mysql8实现读写分离功能
在实际的生产环境中,为了确保数据库的稳定性,我们一般会给数据库配置双机热备机制,这样在master数据库崩溃后,slave数据库可以立即切换成主数据库,通过主从复制的方式将数据从主库同步至从库,在业务代码中编写代码实现读写分离(让主数据库处理 事务性增.改.删操作,而从数据库处理查询操作)来提升数据库的并发负载能力. 下面我们使用最新版本的Mysql数据库(8.0.16)结合SpringBoot实现这一完整步骤(一主一从). 安装配置mysql 从 https://dev.mysql.com/d
-

利用mycat实现mysql数据库读写分离的示例
什么是MyCAT 一个彻底开源的,面向企业应用开发的大数据库集群 支持事务.ACID.可以替代MySQL的加强版数据库 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群 一个融合内存缓存技术.NoSQL技术.HDFS大数据的新型SQL Server 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品 一个新颖的数据库中间件产品 MyCAT关键特性 支持SQL92标准 支持MySQL.Oracle.DB2.SQL Server.PostgreSQL等DB的常见SQL
-
mysql主从复制读写分离的配置方法详解
一.说明 前面我们说了mysql的安装配置,mysql语句使用以及备份恢复mysql数据;本次要介绍的是mysql的主从复制,读写分离;及高可用MHA; 环境如下: master:CentOS7_x64 mysql5.721 172.16.3.175 db1 slave1:CentOS7_x64 mysql5.7.21 172.16.3.235 db2 slave2:CentOS7_x64 mysql5.7.21 172.16.3.235 db3 proxysql/MHA:CentOS7_x64
-
Mysql读写分离过期常用解决方案
mysql读写分离的坑 读写分离的主要目标是分摊主库的压力,由客户端选择后端数据库进行查询.还有种架构就是在MYSQL和客户端之间有一个中间代理层proxy,客户端之连接proxy,由proxy根据请求类型和上下文决定请求的分发路由. 客户端直连方案:因为少了一层proxy转发,所以查询性能稍微好一点儿,并且整体架构简单,排查问题更方便.但是这种方案,由于要了解后端部署细节,所以在出现主备切换.库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息. 带proxy架构:对客户端比较友好
-
Sharding-JDBC自动实现MySQL读写分离的示例代码
目录 一.ShardingSphere和Sharding-JDBC概述 1.1.ShardingSphere简介 1.2.Sharding-JDBC简介 1.3.Sharding-JDBC作用 1.4.ShardingSphere规划线路图 1.5.ShardingSphere三种产品的区别 二.数据库中间件 2.1.数据库中间件简介 2.2.Sharding-JDBC和MyCat区别 三.Sharding-JDBC+MyBatisPlus实现读写分离 3.0.项目代码结构和建表SQL语句 3.
-
基于 SpringBoot 实现 MySQL 读写分离的问题
- 前言 - 首先思考一个问题: 在高并发的场景中,关于数据库都有哪些优化的手段? 常用的实现方法有以下几种:读写分离.加缓存.主从架构集群.分库分表等,在互联网应用中,大部分都是读多写少的场景,设置两个库,主库和读库. 主库的职能是负责写,从库主要是负责读 , 可以建立读库集群 , 通过读写职能在数据源上的隔离达到减少读写冲突. 释压数据库负载.保护数据库的目的.在实际的使用中,凡是涉及到写的部分直接切换到主库,读的部分直接切换到读库,这就是典型的读写分离技术.本文将聚焦读写分
-
使用PHP实现Mysql读写分离
本代码是从uchome的代码修改的,是因为要解决uchome的效率而处理的.这个思维其实很久就有了,只是一直没有去做,相信也有人有同样的想法,如果有类似的,那真的希望提出相关的建议. 封装的方式比较简单,增加了只读数据库连接的接口扩展,不使用只读数据库也不影响原代码使用.有待以后不断完善..为了方便,试试建立了google的一个项目:http://code.google.com/p/mysql-rw-php/希望给有需要的朋友带来帮助. PHP实现的Mysql读写分离主要特性:1.简单的读写分离
-
MySQL 读写分离实例详解
MySQL 读写分离 MySQL读写分离又一好办法 使用 com.mysql.jdbc.ReplicationDriver 在用过Amoeba 和 Cobar,还有dbware 等读写分离组件后,今天我的一个好朋友跟我讲,MySQL自身的也是可以读写分离的,因为他们提供了一个新的驱动,叫 com.mysql.jdbc.ReplicationDriver 说明文档:http://dev.mysql.com/doc/refman/5.1/en/connector-j-reference-replic
-
解决MySQL读写分离导致insert后select不到数据的问题
MySQL设置独写分离,在代码中按照如下写法,可能会出现问题 // 先录入 this.insert(obj); // 再查询 Object res = this.selectById(obj.getId()); res: null; 线上的一个坑,做了读写分离以后,有一个场景因为想方法复用,只传入一个ID就好,直接去库里查出一个对象再做后续处理,结果查不出来,事务隔离级别各种也都排查了,最后发现是读写分离的问题,所以换个思路去实现吧. 补充知识:MySQL INSERT插入条件判断:如果不存在则
-
SpringBoot+Mybatis-Plus实现mysql读写分离方案的示例代码
1. 引入mybatis-plus相关包,pom.xml文件 2. 配置文件application.property增加多库配置 mysql 数据源配置 spring.datasource.primary.jdbc-url=jdbc:mysql://xx.xx.xx.xx:3306/portal?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=
-
SpringBoot项目中如何实现MySQL读写分离详解
目录 1.MySQL主从复制 1.1.介绍 二进制日志: MySQL复制过程分成三步: 1.2.主从库搭建 1.2.1.主库配置 1.2.2.从库配置 1.3.坑位介绍 1.3.1.UUID报错 1.3.2.server_id报错 1.3.3.同步异常解决 操作不规范,亲人两行泪…… 2.项目中实现 2.1.ShardingJDBC 2.2.依赖导入 2.3.配置文件 2.4.测试跑路 总结 1.MySQL主从复制 但我们仔细观察我们会发现,当我们的项目都是用的单体数据库时,那么就可能会存在如下
-
mysql 读写分离(实战篇)
MySQL Proxy最强大的一项功能是实现"读写分离(Read/Write Splitting)".基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询.数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库. Jan Kneschke在<MySQL Proxy learns R/W Splitting>中详细的介绍了这种技巧以及连接池问题: 为了实现读写分离我们需要连接池.我们仅在已打开了到一个后端的一条经过认证的连接的情况下,才切换到该后端.My