python sklearn 画出决策树并保存为PDF的实现过程
目录
- 利用sklearn画出决策树并保存为PDF
- 下载Graphviz
- python sklearn 决策树运用
- 数据形式(tree.csv)
利用sklearn画出决策树并保存为PDF
下载Graphviz
进入官网下载并安装:
https://graphviz.gitlab.io/_pages/Download/Download_windows.html
并将下列路径配置为环境变量:
- D:\software\Graphviz\bin
在cmd中测试:
dot -version
python代码
import numpy as np import pandas as pd from sklearn import tree import graphviz # x,y是sklearn中需要拟合的数据 x = np.array(exam_train) y = np.array(classes_train) clf = tree.DecisionTreeClassifier(criterion='entropy', class_weight='balanced', max_depth=25) clf = clf.fit(x, y) dot_data = tree.export_graphviz(clf, out_file=None, feature_names=None, filled=True, rounded=True) # 重要参数可定制 graph = graphviz.Source(dot_data) graph.render(view=True, format="pdf", filename="decisiontree_pdf")
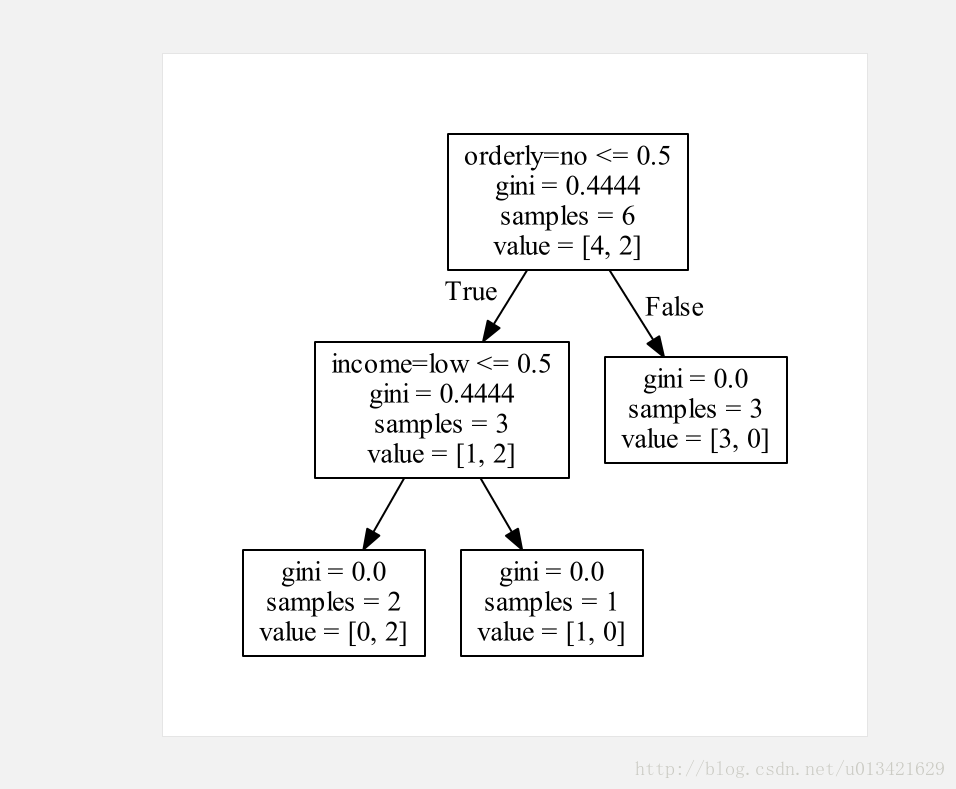
可以生成一张贼帅的决策树PDF:

python sklearn 决策树运用
数据形式(tree.csv)
age look income orderly target older ugly low yes no young ugly high no no young handsome low no no young handsome high yes yes young handsome medium yes yes young handsome medium no no
python源代码:
# -*- coding:utf-8*-
# 将字典 转化为 sklearn 用的数据形式 数据型 矩阵
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree
allElectronicsData = open('c:/pic/data/tree.csv','rb')
reader = csv.reader(allElectronicsData)
header = reader.next()
# print header
## 数据预处理
featureList = []
labelList = []
for row in reader:
# print row[-1]
labelList.append(row[-1])
# 下面这几步的目的是为了让特征值转化成一种字典的形式,就可以调用sk-learn里面的DictVectorizer,直接将特征的类别值转化成0,1值
rowDict = {}
for i in range(1, len(row) - 1):
rowDict[header[i]] = row[i]
featureList.append(rowDict)
for each in featureList:
print each
# Vectorize features
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX:"+str(dummyX))
print(vec.get_feature_names())
# label的转化,直接用preprocessing的LabelBinarizer方法
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:"+str(dummyY))
print("labelList:"+str(labelList))
#criterion是选择决策树节点的 标准 ,这里是按照“熵”为标准,即ID3算法;默认标准是gini index,即CART算法。
clf = tree.DecisionTreeClassifier()
clf = clf.fit(dummyX,dummyY)
print("clf:"+str(clf))
# 导入相关函数,可视化决策树
# 导出的结果是一个dot文件(在系统默认路劲),需要安装Graphviz才能将它住哪华为PDF或png格式
# 输出的dot文件可以使用graphvize软件转为PDF,graphvize安装目录中的bin目录放入到环境变量的Path中
# 使用如下命令
#cmd
# dot -Tpdf c:/tree.dot -o c:/tree.pdf
#下载地址:http://www.graphviz.org/Download_windows.php
#生成dot文件
with open("c:/tree.dot",'w') as f:
f = tree.export_graphviz(clf, feature_names= vec.get_feature_names(),out_file= f)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python决策树和随机森林算法实例详解
本文实例讲述了Python决策树和随机森林算法.分享给大家供大家参考,具体如下: 决策树和随机森林都是常用的分类算法,它们的判断逻辑和人的思维方式非常类似,人们常常在遇到多个条件组合问题的时候,也通常可以画出一颗决策树来帮助决策判断.本文简要介绍了决策树和随机森林的算法以及实现,并使用随机森林算法和决策树算法来检测FTP暴力破解和POP3暴力破解,详细代码可以参考: https://github.com/traviszeng/MLWithWebSecurity 决策树算法 决策树表现了对象属性和
-
python使用sklearn实现决策树的方法示例
1. 基本环境 安装 anaconda 环境, 由于国内登陆不了他的官网 https://www.continuum.io/downloads, 不过可以使用国内的镜像站点: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 添加绘图工具 Graphviz http://www.graphviz.org/Download_windows.php 安装后, 将bin 目录内容添加到环境变量path 即可 参考blog : https://
-
python利用sklearn包编写决策树源代码
本文实例为大家分享了python编写决策树源代码,供大家参考,具体内容如下 因为最近实习的需要,所以用python里的sklearn包重新写了一次决策树. 工具:sklearn,将dot文件转化为pdf格式(是为了将形成的决策树可视化)graphviz-2.38,下载解压之后将其中的bin文件的目录添加进环境变量 源代码如下: from sklearn.feature_extraction import DictVectorizer import csv from sklearn import
-
python sklearn 画出决策树并保存为PDF的实现过程
目录 利用sklearn画出决策树并保存为PDF 下载Graphviz python sklearn 决策树运用 数据形式(tree.csv) 利用sklearn画出决策树并保存为PDF 下载Graphviz 进入官网下载并安装: https://graphviz.gitlab.io/_pages/Download/Download_windows.html 并将下列路径配置为环境变量: D:\software\Graphviz\bin 在cmd中测试: dot -version python代
-
python basemap 画出经纬度并标定的实例
如下所示: 两个函数:Basemap.drawparallels ##纬度 Basemap.drawmeridians ##经度 from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import numpy as np # setup Lambert Conformal basemap. m = Basemap(width=12000000,height=9000000,projection='lcc'
-
python实现画出e指数函数的图像
这里用Python逼近函数y = exp(x);同样使用泰勒函数去逼近: exp(x) = 1 + x + (x)^2/(2!) + .. + (x)^n/(n!) + ... #!/usr/bin/python # -*- coding:utf-8 -*- import numpy as np import math import matplotlib as mpl import matplotlib.pyplot as plt def calc_e_small(x): n = 10 f =
-
用Python字符画出了一个谷爱凌
目录 怎么实现的? 运行方法 原理分析 完整代码 之前经常在网上看到那种由一个个字符构成的视频,非常炫酷.一直不懂是怎么做的,这两天研究了一下,发现并不难. 先来看一个最终效果(如果模糊的话,点击下方链接看高清版): https://pan.baidu.com/s/1DvedXlDZ4dgHKLogdULogg 提取码:1234 怎么实现的? 简单来说,要将一个彩色的视频变成字符画出来的黑白视频,用下面几步就能搞定: 对原视频进行抽帧,对每一帧黑白化,并将像素点用对应的字符表示. 将表示出来的字
-
python目标检测给图画框,bbox画到图上并保存案例
我就废话不多说了,还是直接上代码吧! import os import xml.dom.minidom import cv2 as cv ImgPath = 'C:/Users/49691/Desktop/gangjin/gangjin_test/JPEGImages/' AnnoPath = 'C:/Users/49691/Desktop/gangjin/gangjin_test/Annotations/' #xml文件地址 save_path = '' def draw_anchor(Img
-
利用python画出AUC曲线的实例
以load_breast_cancer数据集为例,模型细节不重要,重点是画AUC的代码. 直接上代码: from sklearn.datasets import load_breast_cancer from sklearn import metrics from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split import pylab as p
-
用Python在Excel里画出蒙娜丽莎的方法示例
之前看到过很多头条,说哪国某人坚持了多少年自学使用excel画画,效果十分惊艳. 对于他们的耐心我十分敬佩. 但是作为一个程序员,自然也得挑战一下自己. 这种需求,我们十分钟就可以完成! 基本思路 实现这个需求的基本思路是读取这张图片每一个像素的色彩值,然后给excel里的每一个单元格填充上颜色.所以主要用到的是PIL.openpyxl这两个库. PIL使用 PIL是Python里面做图像处理的时候十分常用的一个库,功能也是十分的强大,这里只需要用到PIL里一小部分的功能. from PIL i
-
python使用插值法画出平滑曲线
本文实例为大家分享了python使用插值法画出平滑曲线的具体代码,供大家参考,具体内容如下 实现所需的库 numpy.scipy.matplotlib 实现所需的方法 插值 nearest:最邻近插值法 zero:阶梯插值 slinear:线性插值 quadratic.cubic:2.3阶B样条曲线插值 拟合和插值的区别 简单来说,插值就是根据原有数据进行填充,最后生成的曲线一定过原有点. 拟合是通过原有数据,调整曲线系数,使得曲线与已知点集的差别(最小二乘)最小,最后生成的曲线不一定经过原有点
-
python 画出使用分类器得到的决策边界
获取数据集,并画图代码如下: import numpy as np from sklearn.datasets import make_moons import matplotlib.pyplot as plt # 手动生成一个随机的平面点分布,并画出来 np.random.seed(0) X, y = make_moons(200, noise=0.20) plt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.Spectral) plt.show