Java 离线中文语音文字识别功能的实现代码
目录
- 1、pom文件如下:
- 2、工程结构:
- 3、语音识别工具类
- 4、前端交互
- 5、前端页面
- 6、运行效果
项目需要,要实现类似小爱同学的语音控制功能,并且要离线,不能花公司一分钱。第一步就是需要把音频文字化。经过各种资料搜集后,选择了vosk。这是vosk的官方介绍:
Vosk is a speech recognition toolkit. The best things in Vosk are:
- Supports 19+ languages and dialects - English, Indian English, German, French, Spanish, Portuguese, Chinese, Russian, Turkish, Vietnamese, Italian, Dutch, Catalan, Arabic, Greek, Farsi, Filipino, Ukrainian, Kazakh. More to come.
- Works offline, even on lightweight devices - Raspberry Pi, Android, iOS
- Installs with simple pip3 install vosk
- Portable per-language models are only 50Mb each, but there are much bigger server models available.
- Provides streaming API for the best user experience (unlike popular speech-recognition python packages)
- There are bindings for different programming languages, too - java/csharp/javascript etc.
- Allows quick reconfiguration of vocabulary for best accuracy.
- Supports speaker identification beside simple speech recognition.
选择它的理由,开源、可离线、可使用第三方的训练模型,本次使用的官方提供的中文训练模型,如果有需要可自行训练,不过成本太大。具体见官网:https://alphacephei.com/vosk/,官方demo:https://github.com/alphacep/vosk-api。
本次使用springboot +maven实现,官方demo为springboot+gradle。
1、pom文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>voice</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>voice-ai</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<repositories>
<repository>
<id>com.alphacephei</id>
<name>vosk</name>
<url>https://alphacephei.com/maven/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>5.7.0</version>
</dependency>
<dependency>
<groupId>com.alphacephei</groupId>
<artifactId>vosk</artifactId>
<version>0.3.30</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.8</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
特别说明一下,vosk的包在常见的maven仓库里面是没有的,所以需要指定下载地址。
2、工程结构:
3、语音识别工具类
public class VoiceUtil {
@Value("${leenleda.vosk.model}")
private String VOSKMODELPATH;
public String getWord(String filePath) throws IOException, UnsupportedAudioFileException {
Assert.isTrue(StringUtils.hasLength(VOSKMODELPATH), "无效的VOS模块!");
byte[] bytes = Files.readAllBytes(Paths.get(filePath));
// 转换为16KHZ
reSamplingAndSave(bytes, filePath);
File f = new File(filePath);
RandomAccessFile rdf = null;
rdf = new RandomAccessFile(f, "r");
log.info("声音尺寸:{}", toInt(read(rdf, 4, 4)));
log.info("音频格式:{}", toShort(read(rdf, 20, 2)));
short track=toShort(read(rdf, 22, 2));
log.info("1 单声道 2 双声道: {}", track);
log.info("采样率、音频采样级别 16000 = 16KHz: {}", toInt(read(rdf, 24, 4)));
log.info("每秒波形的数据量:{}", toShort(read(rdf, 22, 2)));
log.info("采样帧的大小:{}", toShort(read(rdf, 32, 2)));
log.info("采样位数:{}", toShort(read(rdf, 34, 2)));
rdf.close();
LibVosk.setLogLevel(LogLevel.WARNINGS);
try (Model model = new Model(VOSKMODELPATH);
InputStream ais = AudioSystem.getAudioInputStream(new BufferedInputStream(new FileInputStream(filePath)));
// 采样率为音频采样率的声道倍数
Recognizer recognizer = new Recognizer(model, 16000*track)) {
int nbytes;
byte[] b = new byte[4096];
int i = 0;
while ((nbytes = ais.read(b)) >= 0) {
i += 1;
if (recognizer.acceptWaveForm(b, nbytes)) {
// System.out.println(recognizer.getResult());
} else {
// System.out.println(recognizer.getPartialResult());
}
}
String result = recognizer.getFinalResult();
log.info("识别结果:{}", result);
if (StringUtils.hasLength(result)) {
JSONObject jsonObject = JSON.parseObject(result);
return jsonObject.getString("text").replace(" ", "");
}
return "";
}
}
public static int toInt(byte[] b) {
return (((b[3] & 0xff) << 24) + ((b[2] & 0xff) << 16) + ((b[1] & 0xff) << 8) + ((b[0] & 0xff) << 0));
}
public static short toShort(byte[] b) {
return (short) ((b[1] << 8) + (b[0] << 0));
}
public static byte[] read(RandomAccessFile rdf, int pos, int length) throws IOException {
rdf.seek(pos);
byte result[] = new byte[length];
for (int i = 0; i < length; i++) {
result[i] = rdf.readByte();
}
return result;
}
public static void reSamplingAndSave(byte[] data, String path) throws IOException, UnsupportedAudioFileException {
WaveFileReader reader = new WaveFileReader();
AudioInputStream audioIn = reader.getAudioInputStream(new ByteArrayInputStream(data));
AudioFormat srcFormat = audioIn.getFormat();
int targetSampleRate = 16000;
AudioFormat dstFormat = new AudioFormat(srcFormat.getEncoding(),
targetSampleRate,
srcFormat.getSampleSizeInBits(),
srcFormat.getChannels(),
srcFormat.getFrameSize(),
srcFormat.getFrameRate(),
srcFormat.isBigEndian());
AudioInputStream convertedIn = AudioSystem.getAudioInputStream(dstFormat, audioIn);
File file = new File(path);
WaveFileWriter writer = new WaveFileWriter();
writer.write(convertedIn, AudioFileFormat.Type.WAVE, file);
}
}
有几点需要说明一下,官方demo里面对采集率是写死了的,为16000。这是以16KHz来算的,所以我把所有拿到的音频都转成了16KHz。还有采集率的设置,需要设置为声道数的倍数。
4、前端交互
@RestController
public class VoiceAiController {
@Autowired
VoiceUtil voiceUtil;
@PostMapping("/getWord")
public String getWord(MultipartFile file) {
String path = "G:\\leenleda\\application\\voice-ai\\" + new Date().getTime() + ".wav";
File localFile = new File(path);
try {
file.transferTo(localFile); //把上传的文件保存至本地
System.out.println(file.getOriginalFilename() + " 上传成功");
// 上传成功,开始解析
String text = voiceUtil.getWord(path);
localFile.delete();
return text;
} catch (IOException | UnsupportedAudioFileException e) {
e.printStackTrace();
localFile.delete();
return "上传失败";
}
}
}
5、前端页面
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>声音转换</title>
</head>
<body>
<div>
<audio controls autoplay></audio>
<input id="start" type="button" value="录音" />
<input id="stop" type="button" value="停止" />
<input id="play" type="button" value="播放" />
<input id="upload" type="button" value="提交" />
<div id="text">
</div>
</div>
<script src="http://libs.baidu.com/jquery/2.1.4/jquery.min.js"></script>
<script type="text/javascript" src="HZRecorder.js"></script>
<script>
var recorder;
var audio = document.querySelector('audio');
$("#start").click(function () {
HZRecorder.get(function (rec) {
recorder = rec;
recorder.start();
});
})
$("#stop").click(function () {
recorder.stop();
})
$("#play").click(function () {
recorder.play(audio);
})
$("#upload").click(function () {
recorder.upload("/admin/getWord", function (state, e) {
switch (state) {
case 'uploading':
//var percentComplete = Math.round(e.loaded * 100 / e.total) + '%';
break;
case 'ok':
//alert(e.target.responseText);
// alert("上传成功");
break;
case 'error':
alert("上传失败");
break;
case 'cancel':
alert("上传被取消");
break;
}
});
})
</script>
</body>
</html>
(function (window) {
//兼容
window.URL = window.URL || window.webkitURL;
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
var HZRecorder = function (stream, config) {
config = config || {};
config.sampleBits = 16; //采样数位 8, 16
config.sampleRate = 16000; //采样率(1/6 44100)
var context = new AudioContext();
var audioInput = context.createMediaStreamSource(stream);
var recorder = context.createScriptProcessor(4096, 1, 1);
var audioData = {
size: 0 //录音文件长度
, buffer: [] //录音缓存
, inputSampleRate: context.sampleRate //输入采样率
, inputSampleBits: 16 //输入采样数位 8, 16
, outputSampleRate: config.sampleRate //输出采样率
, oututSampleBits: config.sampleBits //输出采样数位 8, 16
, input: function (data) {
this.buffer.push(new Float32Array(data));
this.size += data.length;
}
, compress: function () { //合并压缩
//合并
var data = new Float32Array(this.size);
var offset = 0;
for (var i = 0; i < this.buffer.length; i++) {
data.set(this.buffer[i], offset);
offset += this.buffer[i].length;
}
//压缩
var compression = parseInt(this.inputSampleRate / this.outputSampleRate);
var length = data.length / compression;
var result = new Float32Array(length);
var index = 0, j = 0;
while (index < length) {
result[index] = data[j];
j += compression;
index++;
}
return result;
}
, encodeWAV: function () {
var sampleRate = Math.min(this.inputSampleRate, this.outputSampleRate);
var sampleBits = Math.min(this.inputSampleBits, this.oututSampleBits);
var bytes = this.compress();
var dataLength = bytes.length * (sampleBits / 8);
var buffer = new ArrayBuffer(44 + dataLength);
var data = new DataView(buffer);
var channelCount = 1;//单声道
var offset = 0;
var writeString = function (str) {
for (var i = 0; i < str.length; i++) {
data.setUint8(offset + i, str.charCodeAt(i));
}
}
// 资源交换文件标识符
writeString('RIFF'); offset += 4;
// 下个地址开始到文件尾总字节数,即文件大小-8
data.setUint32(offset, 36 + dataLength, true); offset += 4;
// WAV文件标志
writeString('WAVE'); offset += 4;
// 波形格式标志
writeString('fmt '); offset += 4;
// 过滤字节,一般为 0x10 = 16
data.setUint32(offset, 16, true); offset += 4;
// 格式类别 (PCM形式采样数据)
data.setUint16(offset, 1, true); offset += 2;
// 通道数
data.setUint16(offset, channelCount, true); offset += 2;
// 采样率,每秒样本数,表示每个通道的播放速度
data.setUint32(offset, sampleRate, true); offset += 4;
// 波形数据传输率 (每秒平均字节数) 单声道×每秒数据位数×每样本数据位/8
data.setUint32(offset, channelCount * sampleRate * (sampleBits / 8), true); offset += 4;
// 快数据调整数 采样一次占用字节数 单声道×每样本的数据位数/8
data.setUint16(offset, channelCount * (sampleBits / 8), true); offset += 2;
// 每样本数据位数
data.setUint16(offset, sampleBits, true); offset += 2;
// 数据标识符
writeString('data'); offset += 4;
// 采样数据总数,即数据总大小-44
data.setUint32(offset, dataLength, true); offset += 4;
// 写入采样数据
if (sampleBits === 8) {
for (var i = 0; i < bytes.length; i++, offset++) {
var s = Math.max(-1, Math.min(1, bytes[i]));
var val = s < 0 ? s * 0x8000 : s * 0x7FFF;
val = parseInt(255 / (65535 / (val + 32768)));
data.setInt8(offset, val, true);
}
} else {
for (var i = 0; i < bytes.length; i++, offset += 2) {
var s = Math.max(-1, Math.min(1, bytes[i]));
data.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}
}
return new Blob([data], { type: 'audio/wav' });
}
};
//开始录音
this.start = function () {
audioInput.connect(recorder);
recorder.connect(context.destination);
}
//停止
this.stop = function () {
recorder.disconnect();
}
//获取音频文件
this.getBlob = function () {
this.stop();
return audioData.encodeWAV();
}
//回放
this.play = function (audio) {
audio.src = window.URL.createObjectURL(this.getBlob());
}
//上传
this.upload = function (url, callback) {
var fd = new FormData();
fd.append("file", this.getBlob());
var xhr = new XMLHttpRequest();
if (callback) {
xhr.upload.addEventListener("progress", function (e) {
callback('uploading', e);
}, false);
xhr.addEventListener("load", function (e) {
callback('ok', e);
}, false);
xhr.addEventListener("error", function (e) {
callback('error', e);
}, false);
xhr.addEventListener("abort", function (e) {
callback('cancel', e);
}, false);
}
xhr.open("POST", url);
xhr.send(fd);
xhr.onreadystatechange = function () {
console.log("语音识别结果:"+xhr.responseText)
$("#text").append('<h2>'+xhr.responseText+'</h2>');
}
}
//音频采集
recorder.onaudioprocess = function (e) {
audioData.input(e.inputBuffer.getChannelData(0));
//record(e.inputBuffer.getChannelData(0));
}
};
//抛出异常
HZRecorder.throwError = function (message) {
alert(message);
throw new function () { this.toString = function () { return message; } }
}
//是否支持录音
HZRecorder.canRecording = (navigator.getUserMedia != null);
//获取录音机
HZRecorder.get = function (callback, config) {
if (callback) {
if (navigator.getUserMedia) {
navigator.getUserMedia(
{ audio: true } //只启用音频
, function (stream) {
var rec = new HZRecorder(stream, config);
callback(rec);
}
, function (error) {
switch (error.code || error.name) {
case 'PERMISSION_DENIED':
case 'PermissionDeniedError':
HZRecorder.throwError('用户拒绝提供信息。');
break;
case 'NOT_SUPPORTED_ERROR':
case 'NotSupportedError':
HZRecorder.throwError('浏览器不支持硬件设备。');
break;
case 'MANDATORY_UNSATISFIED_ERROR':
case 'MandatoryUnsatisfiedError':
HZRecorder.throwError('无法发现指定的硬件设备。');
break;
default:
HZRecorder.throwError('无法打开麦克风。异常信息:' + (error.code || error.name));
break;
}
});
} else {
HZRecorder.throwErr('当前浏览器不支持录音功能。'); return;
}
}
}
window.HZRecorder = HZRecorder;
})(window);
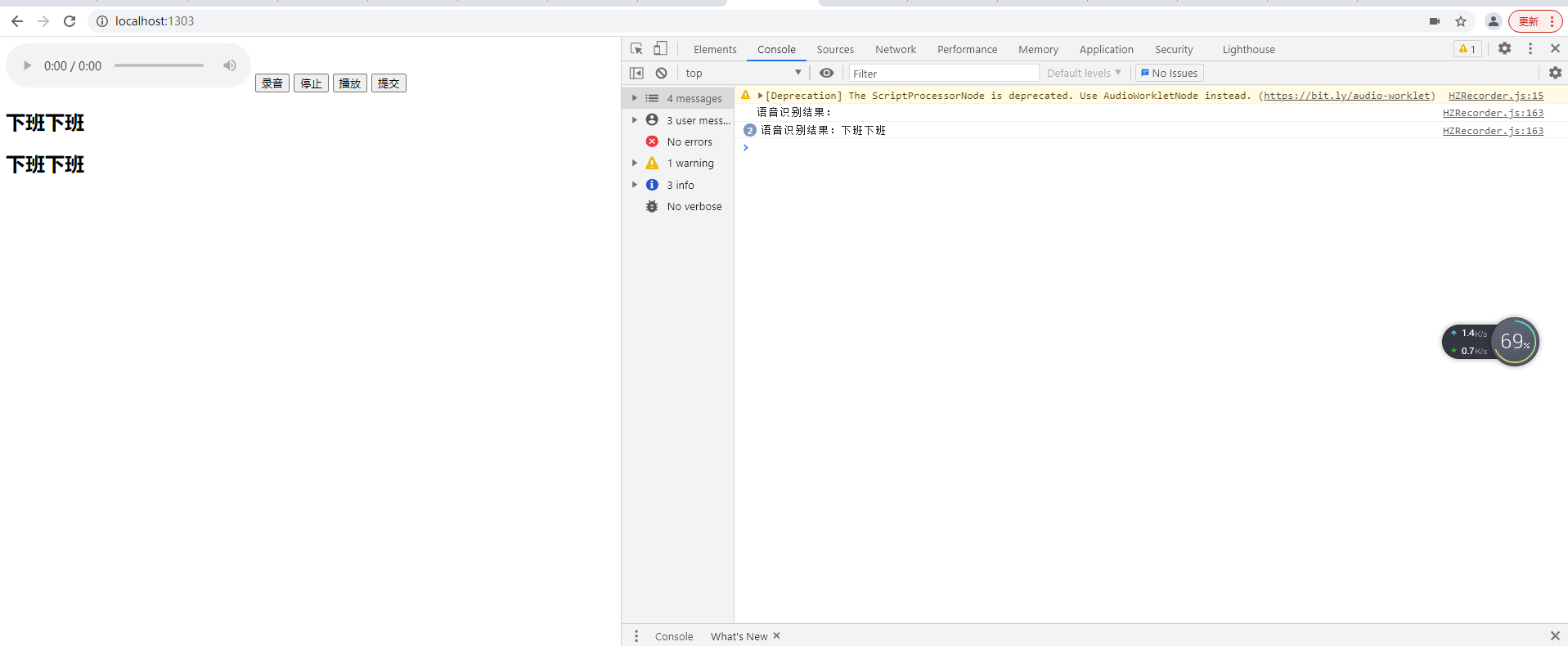
6、运行效果
到此这篇关于Java 离线中文语音文字识别 的文章就介绍到这了,更多相关java 离线语音文字识别 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java实现在线语音识别
本文为大家分享了Java实现在线语音识别的具体方法,供大家参考,具体内容如下 利用讯飞开发平台作为第三方库 首先需要在讯飞开发平台下载SDK,网址为,讯飞开发平台,这些SDK 下载都是免费的,当然你需要先注册.在SDK 中不仅包含相应的jar包,还有一些相应的demo,可以供你参考学习 在我们下载下来第一个SDK 之后就可以进行开发了,讯飞的SDK 给我们提供了详尽而强大的函数支持,下面我就从代码的角度来进行一些解释. 代码 package myVoice; import java.awt.Bu
-
Java实现的百度语音识别功能示例
本文实例讲述了Java实现的百度语音识别功能.分享给大家供大家参考,具体如下: SDK以及示例代码下载地址: http://yuyin.baidu.com/sdk 最近一直在搞java,就选择了java工程.将代码拷过去.同时复制文件"test.pcm"到工程目录下.就基本上可以了. 注:test.pcm是语音文件,可以用audacity软件打开,选择 文件->导入->裸数据. 设置采样率为8000Hz.点击播放就能听见声音了. 这个时候程序跑起来还有问题,需要将apiKe
-
Java 离线中文语音文字识别功能的实现代码
目录 1.pom文件如下: 2.工程结构: 3.语音识别工具类 4.前端交互 5.前端页面 6.运行效果 项目需要,要实现类似小爱同学的语音控制功能,并且要离线,不能花公司一分钱.第一步就是需要把音频文字化.经过各种资料搜集后,选择了vosk.这是vosk的官方介绍: Vosk is a speech recognition toolkit. The best things in Vosk are: Supports 19+ languages and dialects - English, I
-
java实现百度云文字识别接口代码
本文实例为大家分享了java实现百度云文字识别的接口具体代码,供大家参考,具体内容如下 public class Images { public static String getResult() { String otherHost = "https://aip.baidubce.com/rest/2.0/ocr/v1/general"; // 本地图片路径 String str="你的本地图片路径" String filePath = "str&quo
-
C# SDK实现百度云OCR的文字识别功能
最近项目要用到文字识别功能,所以花了几天时间整理了一下.今天就记录一下用C#实现文字识别的过程. 一.登录百度云进入控制台界面,创建应用获取秘钥 1.在百度云的产品里找到文字识别 2.找到通用文字识别点击立即使用.然后进入控制台.(这里可能会进入购买页面,可以直接购买免费版) 3.在控制台点击创建应用.然后填写相关内容就可以获得应用秘钥. 二.获得C#SDK 1.百度云C#SDK下载:下载地址 2.可以到官网直接下载:下载链接 三.将C#SDK导入VS 找到解决方案里的引用目录,右键,选择第一个
-
python使用百度文字识别功能方法详解
介绍python使用百度智能去的文字识别功能,可以识别截图中的文,登陆路验证码等等., 登陆百度智能云,选择产品服务. 选择"人工智能"---文字识别. 点击创建应用. 如图下面有关于"文字识别"的各类信息,如通用文字识别每天可以名费使用50000次,文字识别高精度版本免费使用500次每天.对于一般应用应该还足够. 在创建应用界面填入必要的信息,点击"立即创建"按纽.返回后点击"管理应用"按纽. 管理应用界面主要是能看到调用接
-
Python图像处理之图片文字识别功能(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制. Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司).Tesseract 是目前公认最优秀.最精确的开源OCR 系统. 除 了极高的精确度,Tesseract 也具有很高的灵活性.它可
-
python利用百度AI实现文字识别功能
本文为大家分享了python实现文字识别功能大全,供大家参考,具体内容如下 1.通用文字识别 # -*- coding: UTF-8 -*- from aip import AipOcr # 定义常量 APP_ID = '11352343' API_KEY = 'Nd5Z1NkGoLDvHwBnD2bFLpCE' SECRET_KEY = 'A9FsnnPj1Ys2Gof70SNgYo23hKOIK8Os' # 初始化AipFace对象 aipOcr = AipOcr(APP_ID, API_K
-
Python调用百度AI实现图片上文字识别功能实例
目录 简介 步骤 安装百度AI库 注册百度AI开放平台 调用glob库 调用AipOcr库识别文字 可能会遇到的问题 批量操作 总结 简介 Python免费调用百度AI实现图片上面的文字识别 步骤 安装百度AI库 !pip install baidu-aip 注册百度AI开放平台 先注册百度AI,获得ID和密钥.注册方法可参考:注册方法 只需走到 "1.6 获取密钥" 即可.然后记录下自己的APP_ID.API_KEY.SECRET_KEY,就可以开始了. 调用glob库 glob库用
-
Unity实现OCR文字识别功能
首先登陆百度开发者中心,搜索文字识别服务: 创建一个应用,获取AppID.APIKey.SecretKey秘钥信息: 下载C# SDK,将AipSdk.dll动态库导入Unity: 本文以通用文字识别为例,查阅官方文档,以下是通用文字识别的返回数据结构: 在Unity中定义相应的数据结构: using System; /// <summary> /// 通用文字识别 /// </summary> [Serializable] public class GeneralOcr { //
-
java 百度手写文字识别接口配置代码
代码如下所示: package org.fh.util; import org.json.JSONObject; import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.List; import java.util.Map; /** * 说明:获取文字识别token类 * 作者:
-
十行Python代码实现文字识别功能
目录 1.环境和配置要求 百度接口 2.具体实现步骤 获取截图 调用Baidu aip识别并打印文字 调用打包程序生成专属识别文字小程序 今天给大家分享的主题是用百度的接口实现图片的文字识别. 1.环境和配置要求 整体是用Python实现,所需要使用的第三方库包括aip.PIL.keyboard.pyinstaller,如未安装,可在CMD中使用pip install Baidu-AIP/pillow/keyboard/pyinstaller指令安装. 百度接口 打开网址,如未注册请先注册,然后