java获取IP归属地全网显示开源库使用
目录
- 引言
- Java如何获取IP属地
- Ip2region开源项目
- 99.9%准确率:
- 多查询客户端的支持
- Ip2region V2.0 特性
- ip2region xdb java 查询客户端实现
- IDEA中做个测试
- 编译测试程序
- 查询测试
- bench 测试

引言
细心的朋友应该会发现,最近,继新浪微博之后,头条、腾讯、抖音、知乎、快手、小红书等各大平台陆陆续续都上线了“网络用户IP地址显示功能”,境外用户显示的是国家,国内的用户显示的省份,而且此项显示无法关闭,归属地强制显示。
作为技术人,那!这个功能要怎么实现呢?
Java如何获取IP属地
主要分为以下几步:
- 通过 HttpServletRequest 对象,获取用户的 IP 地址
- 通过 IP 地址,获取对应的省份、城市
首先需要写一个 IP 获取的工具类,因为每一次用户的 Request 请求,都会携带上请求的 IP 地址放到请求头中

通过此方法,从请求Header中获取到用户的IP地址
目前本人在做的项目中,也有获取IP地址归属地省份、城市的需求,用的是:淘宝IP库


原来的请求源码如下:


可以看到日志log文件中,大量的the request over max qps for user问题
Ip2region开源项目
Ip2region开源项目,github地址:github.com/lionsoul201…
目前最新已更新到了v2.0版本,ip2region v2.0是一个离线IP地址定位库和IP定位数据管理框架,10微秒级别的查询效率,准提供了众多主流编程语言的 xdb 数据生成和查询客户端实现。
99.9%准确率:
数据聚合了一些知名ip到地名查询提供商的数据,这些是他们官方的的准确率,经测试着实比经典的纯真IP定位准确一些。
ip2region的数据聚合自以下服务商的开放API或者数据(升级程序每秒请求次数2到4次):
01, >80%, 淘宝IP地址库, ip.taobao.com/\ 02, ≈10%, GeoIP, geoip.com/\ 03, ≈2%, 纯真IP库, www.cz88.net/\ 备注:如果上述开放API或者数据都不给开放数据时ip2region将停止数据的更新服务。
多查询客户端的支持
已经集成的客户端有:java、C#、php、c、python、nodejs、php扩展(php5和php7)、golang、rust、lua、lua_c, nginx。
| binding | 描述 | 开发状态 | binary查询耗时 | b-tree查询耗时 | memory查询耗时 |
|---|---|---|---|---|---|
| c | ANSC c binding | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| c# | c# binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| golang | golang binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| java | java binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| lua | lua实现的binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
| lua_c | lua的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| nginx | nginx的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| nodejs | nodejs | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.1x毫秒 |
| php | php实现的binding | 已完成 | 0.x毫秒 | 0.1x毫秒 | 0.1x毫秒 |
| php5_ext | php5的c扩展 | 已完成 | 0.0x毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| php7_ext | php7的c扩展 | 已完成 | 0.0毫秒 | 0.0x毫秒 | 0.00x毫秒 |
| python | python bindng | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
| rust | rust binding | 已完成 | 0.x毫秒 | 0.x毫秒 | 0.x毫秒 |
Ip2region V2.0 特性
1、标准化的数据格式
每个 ip 数据段的 region 信息都固定了格式:国家|区域|省份|城市|ISP,只有中国的数据绝大部分精确到了城市,其他国家部分数据只能定位到国家,后前的选项全部是0。
2、数据去重和压缩
xdb 格式生成程序会自动去重和压缩部分数据,默认的全部 IP 数据,生成的 ip2region.xdb 数据库是 11MiB,随着数据的详细度增加数据库的大小也慢慢增大。
3、极速查询响应
即使是完全基于 xdb 文件的查询,单次查询响应时间在十微秒级别,可通过如下两种方式开启内存加速查询:
- vIndex 索引缓存 :使用固定的 512KiB 的内存空间缓存 vector index 数据,减少一次 IO 磁盘操作,保持平均查询效率稳定在10-20微秒之间。
- xdb 整个文件缓存:将整个 xdb 文件全部加载到内存,内存占用等同于 xdb 文件大小,无磁盘 IO 操作,保持微秒级别的查询效率。
4、极速查询响应
v2.0 格式的 xdb 支持亿级别的 IP 数据段行数,region 信息也可以完全自定义,例如:你可以在 region 中追加特定业务需求的数据,例如:GPS信息/国际统一地域信息编码/邮编等。也就是你完全可以使用 ip2region 来管理你自己的 IP 定位数据。
ip2region xdb java 查询客户端实现
- 使用方式
引入maven仓库:
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>2.6.4</version>
</dependency>
- 完全基于文件的查询
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
// 1、创建 searcher 对象
String dbPath = "ip2region.xdb file path";
Searcher searcher = null;
try {
searcher = Searcher.newWithFileOnly(dbPath);
} catch (IOException e) {
System.out.printf("failed to create searcher with `%s`: %s\n", dbPath, e);
return;
}
// 2、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 3、备注:并发使用,每个线程需要创建一个独立的 searcher 对象单独使用。
}
}
- 缓存VectorIndex索引
我们可以提前从 xdb 文件中加载出来 VectorIndex 数据,然后全局缓存,每次创建 Searcher 对象的时候使用全局的 VectorIndex 缓存可以减少一次固定的 IO 操作,从而加速查询,减少 IO 压力。
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "ip2region.xdb file path";
// 1、从 dbPath 中预先加载 VectorIndex 缓存,并且把这个得到的数据作为全局变量,后续反复使用。
byte[] vIndex;
try {
vIndex = Searcher.loadVectorIndexFromFile(dbPath);
} catch (Exception e) {
System.out.printf("failed to load vector index from `%s`: %s\n", dbPath, e);
return;
}
// 2、使用全局的 vIndex 创建带 VectorIndex 缓存的查询对象。
Searcher searcher;
try {
searcher = Searcher.newWithVectorIndex(dbPath, vIndex);
} catch (Exception e) {
System.out.printf("failed to create vectorIndex cached searcher with `%s`: %s\n", dbPath, e);
return;
}
// 3、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 备注:每个线程需要单独创建一个独立的 Searcher 对象,但是都共享全局的制度 vIndex 缓存。
}
}
- 缓存整个xdb数据
我们也可以预先加载整个 ip2region.xdb 的数据到内存,然后基于这个数据创建查询对象来实现完全基于文件的查询,类似之前的 memory search。
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "ip2region.xdb file path";
// 1、从 dbPath 加载整个 xdb 到内存。
byte[] cBuff;
try {
cBuff = Searcher.loadContentFromFile(dbPath);
} catch (Exception e) {
System.out.printf("failed to load content from `%s`: %s\n", dbPath, e);
return;
}
// 2、使用上述的 cBuff 创建一个完全基于内存的查询对象。
Searcher searcher;
try {
searcher = Searcher.newWithBuffer(cBuff);
} catch (Exception e) {
System.out.printf("failed to create content cached searcher: %s\n", e);
return;
}
// 3、查询
try {
String ip = "1.2.3.4";
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 备注:并发使用,用整个 xdb 数据缓存创建的查询对象可以安全的用于并发,也就是你可以把这个 searcher 对象做成全局对象去跨线程访问。
}
}
IDEA中做个测试
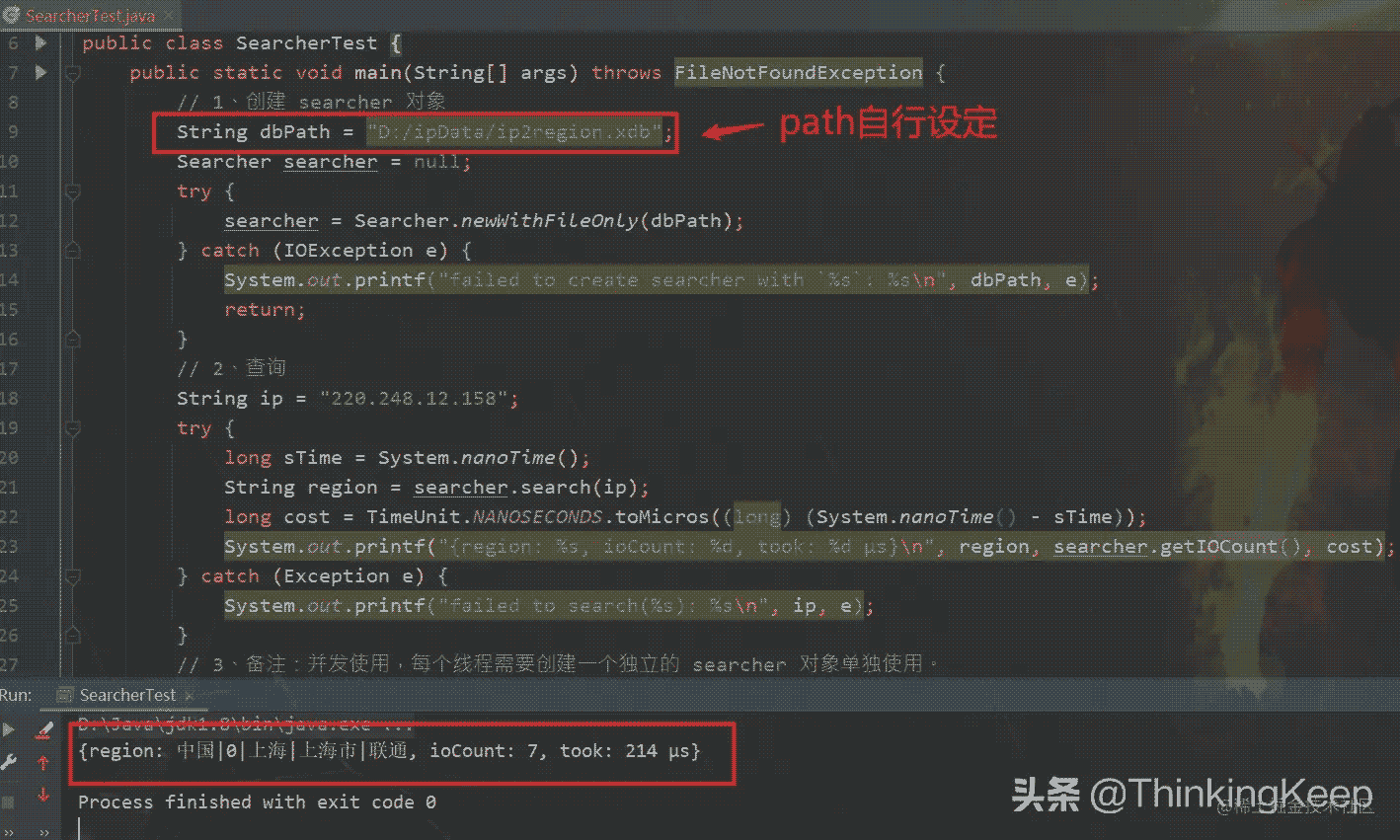
完全基于文件的查询
ip属地国内的话,会展示省份,国外的话,只会展示国家。可以通过如下图这个方法进行进一步封装,得到获取IP属地的信息。

下面是官网给出的命令运行jar方式给出的测试demo,可以理解下
编译测试程序
通过 maven 来编译测试程序。
# cd 到 java binding 的根目录 cd binding/java/ mvn compile package
然后会在当前目录的 target 目录下得到一个 ip2region-{version}.jar 的打包文件。
查询测试
可以通过 java -jar ip2region-{version}.jar search 命令来测试查询:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar search
java -jar ip2region-{version}.jar search [command options]
options:
--db string ip2region binary xdb file path
--cache-policy string cache policy: file/vectorIndex/content
例如:使用默认的 data/ip2region.xdb 文件进行查询测试:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar search --db=../../data/ip2region.xdb
ip2region xdb searcher test program, cachePolicy: vectorIndex
type 'quit' to exit
ip2region>> 1.2.3.4
{region: 美国|0|华盛顿|0|谷歌, ioCount: 7, took: 82 μs}
ip2region>>
输入 ip 即可进行查询测试,也可以分别设置 cache-policy 为 file/vectorIndex/content 来测试三种不同缓存实现的查询效果。
bench 测试
可以通过 java -jar ip2region-{version}.jar bench 命令来进行 bench 测试,一方面确保 xdb 文件没有错误,一方面可以评估查询性能:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar bench
java -jar ip2region-{version}.jar bench [command options]
options:
--db string ip2region binary xdb file path
--src string source ip text file path
--cache-policy string cache policy: file/vectorIndex/content
例如:通过默认的 data/ip2region.xdb 和 data/ip.merge.txt 文件进行 bench 测试:
➜ java git:(v2.0_xdb) ✗ java -jar target/ip2region-2.6.0.jar bench --db=../../data/ip2region.xdb --src=../../data/ip.merge.txt
Bench finished, {cachePolicy: vectorIndex, total: 3417955, took: 8s, cost: 2 μs/op}
可以通过分别设置 cache-policy 为 file/vectorIndex/content 来测试三种不同缓存实现的效果。 @Note: 注意 bench 使用的 src 文件要是生成对应 xdb 文件相同的源文件。
到这里获取用户IP属地已经完成啦,这篇文章介绍的v2.0版本,有兴趣的小伙伴可以登录上门的github地址了解下v1.0版本
更多关于java获取IP归属地全网显示的资料请关注我们其它相关文章!
相关推荐
-

java IP归属地功能实现详解
目录 第一步:如何拿到用户的真实IP 1.1内网IP和外网IP 1.2.为什么有时候获取到的客户端IP有问题? 第二步:如何解析IP 第一步:如何拿到用户的真实IP 大家都知道,我们一般想访问公网,一般必须具备上网环境,那么我们开通宽带之后,运营商会给我们分配一个IP地址.一般IP地址我们都是自动分配的.所以我们不知道本机地址是什么?想知道自己的ip公网地址,可以通过百度搜索IP查看自己的ip位置 那么问题来了.百度是怎么知道我的公网IP的? 一般情况,用户访问我们的服务网络拓扑如下: 用户通过
-
易语言调用百度API获取IP归属地的代码
常量据表 .版本 2 .常量 查ip地址, "<文本长度: 17>", , {"code":0,"data": 调用百度api获取ip归属地的代码 此功能需要加载精易模块5.6 .版本 2 .程序集 窗口程序集_启动窗口 .子程序 取IP归属地_百度API, 文本型, 公开 .参数 IP地址, 文本型 .局部变量 Json, 类_json .局部变量 返回数据, 文本型 .局部变量 地区, 文本型 CoInitialize (0) 返
-
使用Redis有序集合实现IP归属地查询详解
工作中经常遇到一类需求,根据 IP 地址段来查找 IP 对应的归属地信息.如果把查询过程放到关系型数据库中,会带来很大的 IO 消耗,速度也不能满足,显然是不合适的. 那有哪些更好的办法呢?为此做了一些尝试,下面来详细说明. 构建索引文件 在 GitHub 上看到一个ip2region 项目,作者通过生成一个包含有二级索引的文件来实现快速查询,查询速度足够快,毫秒级别.但如果想更新地址段或归属地信息,每次都要重新生成文件,并不是很方便. 不过还是推荐大家看看这个项目,其中建索引的思想还是很值得学
-
java调用淘宝api联网查询ip归属地
淘宝返回的数据为:{"code":0,"data":{"country":"\u4e2d\u56fd","country_id":"CN","area":"\u534e\u4e1c","area_id":"300000","region":"\u5c71\u4e1c\u7701&
-
python 实现全球IP归属地查询工具
# 写在前面,这篇文章的原创作者是Charles我只是在他这个程序的基础上边进行加工,另外有一些自己的改造 # 并都附上了注释和我自己的理解,这也是我一个学习的过程. # 附上大佬的GitHub地址:https://github.com/CharlesPikachu/Tools ''' Function: 根据IP地址查其对应的地理信息 Author: Charles 微信公众号: Charles的皮卡丘 ''' import IPy import time import random impo
-
Shell调用curl实现IP归属地查询的脚本
可用于shell环境进行IP归属地查询 #!/bin/bash #传入IP参数 IP=$1 #使用百度开放地址库 url="http://opendata.baidu.com/api.php?query=${IP}&co=&resource_id=6006&t=1412300361645&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb=jQuery1
-
java获取IP归属地全网显示开源库使用
目录 引言 Java如何获取IP属地 Ip2region开源项目 99.9%准确率: 多查询客户端的支持 Ip2region V2.0 特性 ip2region xdb java 查询客户端实现 IDEA中做个测试 编译测试程序 查询测试 bench 测试 引言 细心的朋友应该会发现,最近,继新浪微博之后,头条.腾讯.抖音.知乎.快手.小红书等各大平台陆陆续续都上线了“网络用户IP地址显示功能”,境外用户显示的是国家,国内的用户显示的省份,而且此项显示无法关闭,归属地强制显示. 作为技术人,那!
-
python实现获取Ip归属地等信息
如果你有一批IP地址想要获得这些IP具体的信息,比如归属国家,城市等,最好的办法当时是调用现有的api接口来获取,我在之前就写过一篇文章,是关于我的博客被莫名攻击的时,就有获取过一批IP,攻击的时候当时是恢复业务重要,IP该封的就要封,攻击过后这个攻击者的IP信息,自己就可以分析下都来自哪里,有没有什么特征,帮助提示自己网站的安全性,今天这个脚本就是根据提供的IP获得IP归属的具体信息,脚本如下: #!/usr/bin/env python import requests import csv
-
java获取ip地址与网络接口的方法示例
java.net包 大家应该都知道,网络相关对象在java.net包中,Java net包下的类如下: 1.获取主机对象InetAddress //获取本地主机对象 InetAddress host = InetAddress.getLocalHost(); //根据ip地址或主机名获取主机对象,以主机名获取主机时需要DNS解析 InetAddress host = InetAddress.getByName("192.168.100.124"); InetAddress host =
-
java获取ip地址示例
如果使用了反向代理软件,将http://192.168.1.110:2046/ 的URL反向代理为http://www.xxx.com/ 的URL时,用request.getRemoteAddr()方法获取的IP地址是:127.0.0.1 或 192.168.1.110,而并不是客户端的真实IP. 经过代理以后,由于在客户端和服务之间增加了中间层,因此服务器无法直接拿到客户端的IP,服务器端应用也无法直接通过转发请求的地址返回给客户端.但是在转发请求的HTTP头信息中,增加了X-FORWARDE
-
Java获取手机号码归属地的实现
遇到一个需求, 需要发送短信给全球各地的用户, 但是各大运营商的API都是 区分 国内 和 国际, 但是我们只有电话号码, 只能自己添加一个方法, 判断号码的归属地, 然后再分别调用相应区域的API. 引入依赖包 <!-- 电话号码工具类 --> <dependency> <groupId>com.googlecode.libphonenumber</groupId> <artifactId>libphonenumber</artifact
-
JAVA使用Ip2region获取IP定位信息的操作方法
目录 先安装依赖 下载离线IP定位库 下面我们定义类封装ip2region 测试输出 实际使用 ip2region - 准确率99.9%的离线IP地址定位库,0.0x毫秒级查询 ip2region - 是国内开发者开发的离线IP地址定位库,针对国内IP效果较好,国外的部分IP只能显示国家. 项目gitee地址: https://gitee.com/lionsoul/ip2region.git 先安装依赖 <dependency> <groupId>org.lionsoul</
-
Java获取电脑真实IP地址的示例代码
/** * @author yins * @date 2018年8月12日下午9:53:58 */ import java.net.Inet4Address; import java.net.InetAddress; import java.net.NetworkInterface; import java.net.SocketException; import java.util.Enumeration; /** * 获取本地真正的IP地址,即获得有线或者无线WiFi地址. * 过滤虚拟机.蓝
-
Java根据ip地址获取归属地实例详解
目录 引言 Java 中是如何获取 IP 属地的 首先需要写一个 IP 获取的工具类 内置的三种查询算法 使用方法 项目用到的全部依赖 引言 最近,各大平台都新增了评论区显示发言者ip归属地的功能,例如哔哩哔哩,微博,知乎等等. Java 中是如何获取 IP 属地的 主要分为以下几步 通过 HttpServletRequest 对象,获取用户的 IP 地址 通过 IP 地址,获取对应的省份.城市 首先需要写一个 IP 获取的工具类 因为每一次用户的 Request 请求,都会携带上请求的 IP
-
Java利用Request请求如何获取IP地址对应的省份、城市详解
前言 最近的一个项目中需要将不同省份的用户,展示不同内容,所以需要通过Request请求获取IP地址, 然后通过IP获取IP对应省份. 这里的操作步骤一共有步: 1. 通过Request获取IP 2. 通过IP获取对应省份.城市 3. 通过设置的省份和IP对应省份进行比对,展示内容 通过Request获取IP 可以参考我的另外一篇文章[Java 通过Request请求获取IP地址]下面是代码: public class IpAdrressUtil { /** * 获取Ip地址 * @param