基于Python爬取京东双十一商品价格曲线
一年一度的双十一就快到了,各种砍价、盖楼、挖现金的口令将在未来一个月内充斥朋友圈、微信群中。玩过多次双十一活动的小编表示一顿操作猛如虎,一看结果2毛5。浪费时间不说而且未必得到真正的优惠,双十一电商的“明降暗升”已经是默认的潜规则了。打破这种规则很简单,可以用 Python 写一个定时监控商品价格的小工具。
思路第一步抓取商品的价格存入 Python 自带的 SQLite 数据库每天定时抓取商品价格使用 pyecharts 模块绘制价格折线图,让低价一目了然
抓取京东价格
从商品详情的页面中打开 F12 控制面板,找到包含 p.3 的链接,在旁边的 preview 面板中可以看到当前商品价格

defget_jd_price(skuId):
sku_detail_url = 'http://item.jd.com/{}.html'
sku_price_url = 'https://p.3.cn/prices/get?type=1&skuid=J_{}'
r = requests.get(sku_detail_url.format(skuId)).content
soup = BeautifulSoup(r, 'html.parser', from_encoding='utf-8')
sku_name_div = soup.find('div', class_="sku-name")
if not sku_name_div:
print('您输入的商品ID有误!')
return
else:
sku_name = sku_name_div.text.strip()
r = requests.get(sku_price_url.format(skuId))
price = json.loads(r.text)[0]['p']
data = {
'sku_id': skuId,
'sku_name': sku_name,
'price': price
}
return data
把抓取的价格存入 sqlite 数据库,使用 PyCharm 的 Database 功能创建一个 sqlite 数据库
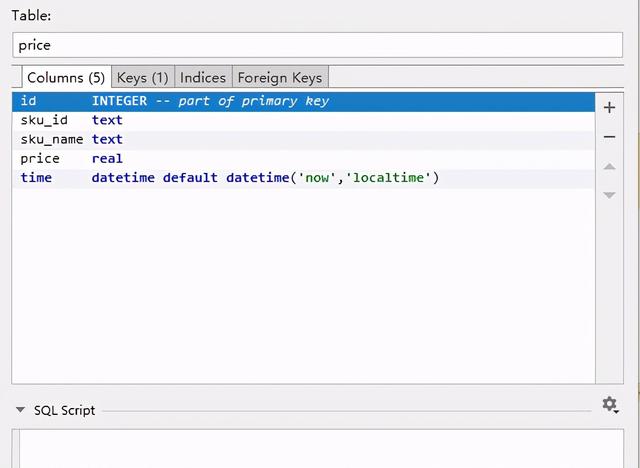
最终将数据插入到数据库
# 新增
def insert(data):
conn = sqlite3.connect('price.db')
c = conn.cursor()
sql = 'INSERT INTO price (sku_id,sku_name,price) VALUES ("{}", "{}", "{}")'.format(data.get("sku_id"), data.get("sku_name"), data.get('price') )
c.execute(sql)
conn.commit()
conn.close()
# 查询
def select(sku_id):
conn = sqlite3.connect('price.db')
c = conn.cursor()
sql = 'select sku_id, sku_name, price, time from price where sku_id = "{}" order by time asc'.format(sku_id)
cursor = c.execute(sql)
datas = []
for row in cursor:
data = {
'sku_id': row[0],
'sku_name': row[1],
'price': row[2],
'time': row[3]
}
datas.append(data)
conn.close()
return datas
示例结果

计划任务
使用轻量级的 schedule 模块每天早上 10 点抓取京东价格这一步骤
安装 schedule 模块
pip install schedule
def run_price_job(skuId):
# 使用不占主线程的方式启动 计划任务
def run_continuously(interval=1):
cease_continuous_run = threading.Event()
class ScheduleThread(threading.Thread):
@classmethod
def run(cls):
while not cease_continuous_run.is_set():
schedule.run_pending()
time.sleep(interval)
continuous_thread = ScheduleThread()
continuous_thread.start()
return cease_continuous_run
# 每天10点运行,get_jd_price:任务方法,skuId:任务方法的参数
schedule.every().day.at("10:00").do(get_jd_price, skuId=skuId)
run_continuously()
查看历史价格
使用 pytharts 模块绘制折线图,直观的查看每一天的价格差异
datas = select(skuId)
def line(datas):
x_data = []
y_data = []
for data in datas:
x_data.append(data.get('time'))
y_data.append(data.get('price'))
(
Line()
.add_xaxis(x_data)
.add_yaxis(datas[0].get('sku_name'), y_data, is_connect_nones=True)
.render("商品历史价格.html")
)
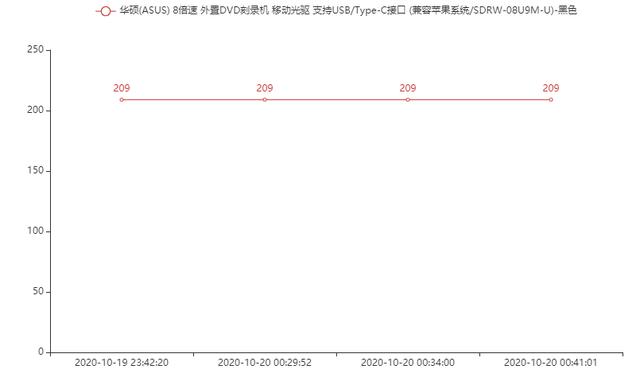
总结
本文抓取了京东商城的价格,小伙伴们也可以修个脚本抓取淘宝的价格。使用 Python 解决生活中的小小痛点,让钱包不再干瘪。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python 制作查询商品历史价格的小工具
一年一度的双十一就快到了,各种砍价.盖楼.挖现金的口令将在未来一个月内充斥朋友圈.微信群中.玩过多次双十一活动的小编表示一顿操作猛如虎,一看结果2毛5.浪费时间不说而且未必得到真正的优惠,双十一电商的"明降暗升"已经是默认的潜规则了.打破这种规则很简单,可以用 Python 写一个定时监控商品价格的小工具. 思路 第一步抓取商品的价格存入 Python 自带的 SQLite 数据库 每天定时抓取商品价格 使用 pyecharts 模块绘制价格折线图,让低价一目了然 抓取京东价格 从商品
-
python抓取京东价格分析京东商品价格走势
复制代码 代码如下: from creepy import Crawlerfrom BeautifulSoup import BeautifulSoupimport urllib2import json class MyCrawler(Crawler): def process_document(self, doc): if doc.status == 200: print '[%d] %s' % (doc.status, doc.url)
-
python定向爬取淘宝商品价格
python爬虫学习之定向爬取淘宝商品价格,供大家参考,具体内容如下 import requests import re def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() #如果发送了一个失败请求(非200响应),#我们可以通过 Response.raise_for_status() 来抛出异常: r.encoding= r.apparent_encoding return r.te
-

使用python爬虫获取黄金价格的核心代码
继续练手,根据之前获取汽油价格的方式获取了金价,暂时没钱投资,看看而已 #!/usr/bin/env python # -*- coding: utf-8 -*- """ 获取每天黄金价格 @author: yufei @site: http://www.antuan.com 2017-05-11 """ import re import urllib2,urllib import random import threading import t
-
python根据京东商品url获取产品价格
京东商品详细的请求处理,是先显示html,然后再ajax请求处理显示价格. 1.可以运行js,并解析之后得到的html 2.模拟js请求,得到价格 # -*- coding: utf-8 -*- """ 根据京东url地址,获取商品价格 京东请求处理过程,先显示html页面,然后通过ajax get请求获取相应的商品价格 1.商品的具体数据在html中的格式,如下(示例) # product: { # skuid: 1310118868, # name: '\u9999\u5
-
python实现快递价格查询系统
本文实例为大家分享了python实现快递价格查询系统的具体代码,供大家参考,具体内容如下 一.代码 #--author--张俊杰@Nick #系统提示 print("欢迎来到快递系统!") #死循环 while 1==1: #简单交互,键入值 weight=int(input("请输入重量(千克): ")) num=input("请输入地点编号(1.其它 2.东三省/宁夏/青海/海南 3.新疆/西藏 4.港澳台/国外):") #定义参数 p=0
-
python用线性回归预测股票价格的实现代码
线性回归在整个财务中广泛应用于众多应用程序中.在之前的教程中,我们使用普通最小二乘法(OLS)计算了公司的beta与相对索引的比较.现在,我们将使用线性回归来估计股票价格. 线性回归是一种用于模拟因变量(y)和自变量(x)之间关系的方法.通过简单的线性回归,只有一个自变量x.可能有许多独立变量属于多元线性回归的范畴.在这种情况下,我们只有一个自变量即日期.对于第一个日期上升到日期向量长度的整数,该日期将由1开始的整数表示,该日期可以根据时间序列数据而变化.当然,我们的因变量将是股票的价格.为了理
-
基于Python爬取京东双十一商品价格曲线
一年一度的双十一就快到了,各种砍价.盖楼.挖现金的口令将在未来一个月内充斥朋友圈.微信群中.玩过多次双十一活动的小编表示一顿操作猛如虎,一看结果2毛5.浪费时间不说而且未必得到真正的优惠,双十一电商的"明降暗升"已经是默认的潜规则了.打破这种规则很简单,可以用 Python 写一个定时监控商品价格的小工具. 思路第一步抓取商品的价格存入 Python 自带的 SQLite 数据库每天定时抓取商品价格使用 pyecharts 模块绘制价格折线图,让低价一目了然 抓取京东价格 从商品详情的
-
python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
基于Python+Appium实现京东双十一自动领金币功能
背景:做任务领金币的过程很无聊,而且每天都是重复同样的工作,非常符合自动化的定义: 工具:python,appium,Android 手机(我使用的是安卓6.0的),数据线一根: 开搞前先让手机和电脑连上同一个无线网: 1.抓取京东APP的包名和Activity 先连接手机 windows+r输入cmd进入命令行页面 输入:adb devices查看设备是否链接: 输入:adb shell pm list package -3查看手机里面的第三方安装包: 很明显可以看出来京东的package是:
-
python 爬取京东指定商品评论并进行情感分析
项目地址 https://github.com/DA1YAYUAN/JD-comments-sentiment-analysis 爬取京东商城中指定商品下的用户评论,对数据预处理后基于SnowNLP的sentiment模块对文本进行情感分析. 运行环境 Mac OS X Python3.7 requirements.txt Pycharm 运行方法 数据爬取(jd.comment.py) 启动jd_comment.py,建议修改jd_comment.py中变量user-agent为自己浏览器用户
-
Python爬取京东的商品分类与链接
前言 本文主要的知识点是使用Python的BeautifulSoup进行多层的遍历. 如图所示.只是一个简单的哈,不是爬取里面的隐藏的东西. 示例代码 from bs4 import BeautifulSoup as bs import requests headers = { "host": "www.jd.com", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWe
-
Python爬取京东商品信息评论存并进MySQL
目录 构建mysql数据表 第一版: 第二版 : 第三版: 构建mysql数据表 问题:使用SQL alchemy时,非主键不能设置为自增长,但是我想让这个非主键仅仅是为了作为索引,autoincrement=True无效,该怎么实现让它自增长呢? from sqlalchemy import String,Integer,Text,Column from sqlalchemy import create_engine from sqlalchemy.orm import sessionmake
-
基于Python爬取51cto博客页面信息过程解析
介绍 提到爬虫,互联网的朋友应该都不陌生,现在使用Python爬取网站数据是非常常见的手段,好多朋友都是爬取豆瓣信息为案例,我不想重复,就使用了爬取51cto博客网站信息为案例,这里以我的博客页面为教程,编写的Python代码! 实验环境 1.安装Python 3.7 2.安装requests, bs4模块 实验步骤 1.安装Python3.7环境 2.安装requests,bs4 模块 打开cmd,输入:pip install requests -i https://pypi.tuna.tsi
-
Python基于BeautifulSoup爬取京东商品信息
今天小编利用美丽的汤来为大家演示一下如何实现京东商品信息的精准匹配~~ HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树:因此可以说Beautiful Soup库是解析.遍历.维护"标签树"的功能库. 如何利用BeautifulSoup抓取京东网商品信息 首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求.在这里小编仍以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://se
-
基于Python爬取fofa网页端数据过程解析
FOFA-网络空间安全搜索引擎是网络空间资产检索系统(FOFA)是世界上数据覆盖更完整的IT设备搜索引擎,拥有全球联网IT设备更全的DNA信息.探索全球互联网的资产信息,进行资产及漏洞影响范围分析.应用分布统计.应用流行度态势感知等. 安装环境: pip install requests pip install lxml pip install fire 使用命令: python fofa.py -s=title="你的关键字" -o="结果输出文件" -c=&qu
-
基于Python爬取搜狐证券股票过程解析
数据的爬取 我们以上证50的股票为例,首先需要找到一个网站包含这五十只股票的股票代码,例如这里我们使用搜狐证券提供的列表. https://q.stock.sohu.com/cn/bk_4272.shtml 可以看到,在这个网站中有上证50的所有股票代码,我们希望爬取的就是这个包含股票代码的表,并获取这个表的第一列. 爬取网站的数据我们使用Beautiful Soup这个工具包,需要注意的是,一般只能爬取到静态网页中的信息. 简单来说,Beautiful Soup是Python的一个库,最主要的