详解监听MySQL的binlog日志工具分析:Canal
Canal是阿里巴巴旗下的一款开源项目,利用Java开发。主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费,目前主要支持MySQL。
GitHub地址:https://github.com/alibaba/canal

在介绍Canal内部原理之前,首先来了解一下MySQL Master/Slave同步原理:
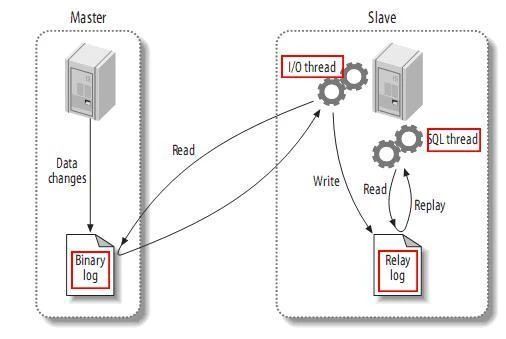
MySQL master启动binlog机制,将数据变更写入二进制日志(binary log, 其中记录叫做二进制日志事件binary log events,可以通过show binlog events进行查看)MySQL slave(I/O thread)将master的binary log events拷贝到它的中继日志(relay log)MySQL slave(SQL thread)重放relay log中事件,将数据变更反映它自己的数据中
Canal工作原理:
Canal模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议MySQL master收到dump请求,开始推送binary log给slave(也就是canal)Canal解析binary log对象(原始为byte流)
简而言之,Canal是通过模拟成为MySQL的slave,监听MySQL的binlog日志来获取数据。当把MySQL的binlog设置为row模式以后,可以获取到执行的每一个Insert/Update/Delete的脚本,以及修改前和修改后的数据,基于这个特性,Canal就能高效的获取到MySQL数据的变更。 Canal架构:

说明: server代表一个Canal运行实例,对应于一个jvm instance对应于一个数据队列(1个server对应1..n个instance)
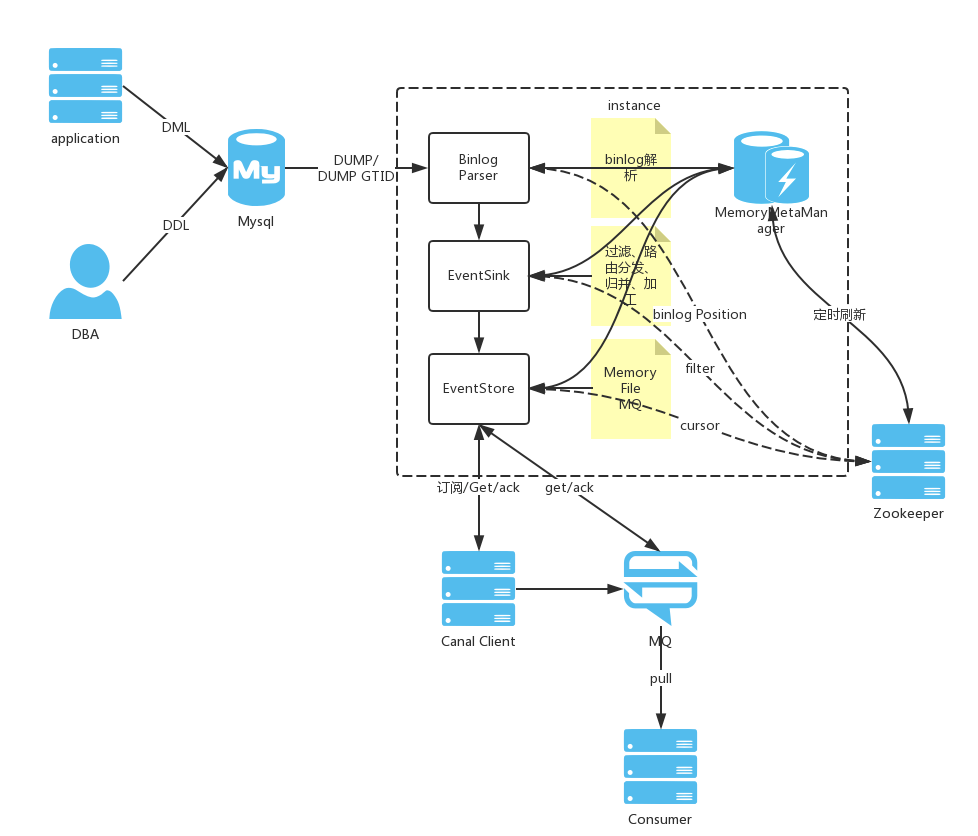
EventParser:数据源接入,模拟slave协议和master进行交互,协议解析
EventSink:Parser和Store连接器,主要进行数据过滤,加工,分发的工作
EventStore:负责存储
MemoryMetaManager:增量订阅和消费信息管理器
Event Parser设计:

整个parser过程大致可分为以下几步:
Connection获取上一次解析成功的log position(如果是第一次启动,则获取初始指定的位置或者是当前数据库的binlog log position)Connection建立连接,向MySQL master发送BINLOG_DUMP请求MySQL开始推送binary Log接收到的binary Log通过BinlogParser进行协议解析,补充一些特定信息。如补充字段名字、字段类型、主键信息、unsigned类型处理等将解析后的数据传入到EventSink组件进行数据存储(这是一个阻塞操作,直到存储成功)定时记录binary Log位置,以便重启后继续进行增量订阅
如果需要同步的master宕机,可以从它的其他slave节点继续同步binlog日志,避免单点故障。 Event Sink设计:
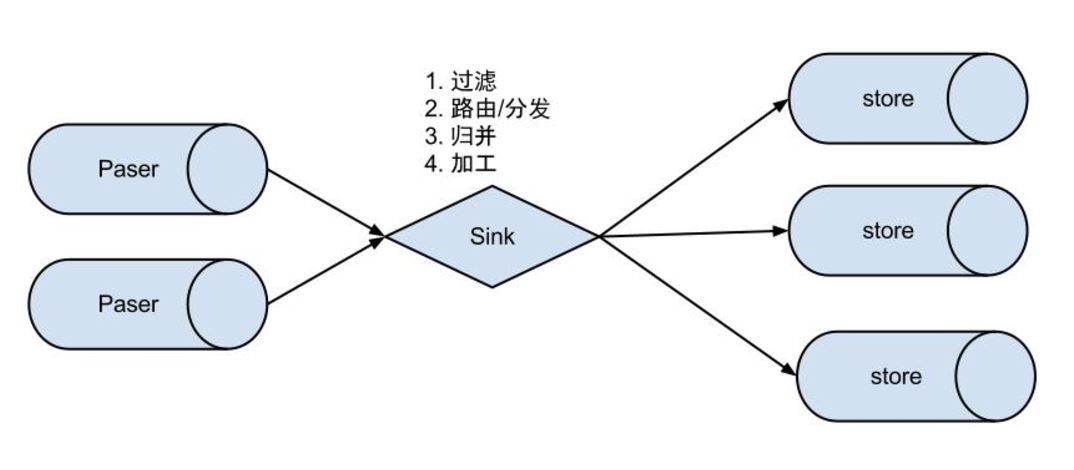
EventSink主要作用如下:
数据过滤:支持通配符的过滤模式,表名,字段内容等
数据路由/分发:解决1:n(1个parser对应多个store的模式)
数据归并:解决n:1(多个parser对应1个store)
数据加工:在进入store之前进行额外的处理,比如join 数据1:n业务
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在MySQL上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注。
数据n:1业务
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并。 Event Store设计:
支持多种存储模式,比如Memory内存模式。采用内存环装的设计来保存消息,借鉴了Disruptor的RingBuffer的实现思路。 RingBuffer设计:

定义了3个cursor:
put:Sink模块进行数据存储的最后一次写入位置(同步写入数据的cursor)
get:数据订阅获取的最后一次提取位置(同步获取的数据的cursor)
ack:数据消费成功的最后一次消费位置
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:

实现说明:
put/get/ack cursor用于递增,采用long型存储。三者之间的关系为put>=get>=ackbuffer的get操作,通过取余或者&操作。(&操作:cusor & (size - 1) , size需要为2的指数,效率比较高)
Instance设计:
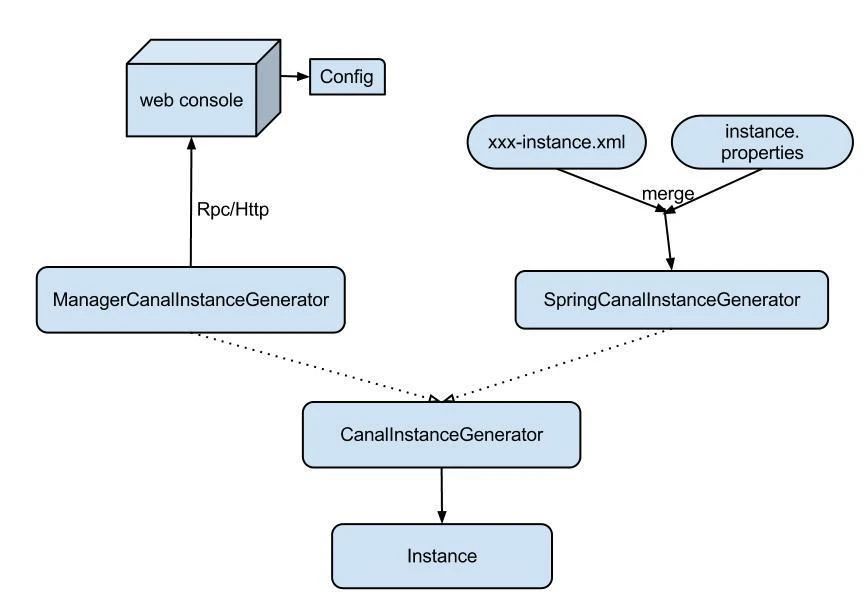
instance代表了一个实际运行的数据队列,包括了EventPaser、EventSink、EventStore等组件。抽象了CanalInstanceGenerator,主要是考虑配置的管理方式:
manager方式:和你自己的内部web console/manager系统进行对接。(目前主要是公司内部使用)
spring方式:基于spring xml + properties进行定义,构建spring配置。 Server设计:
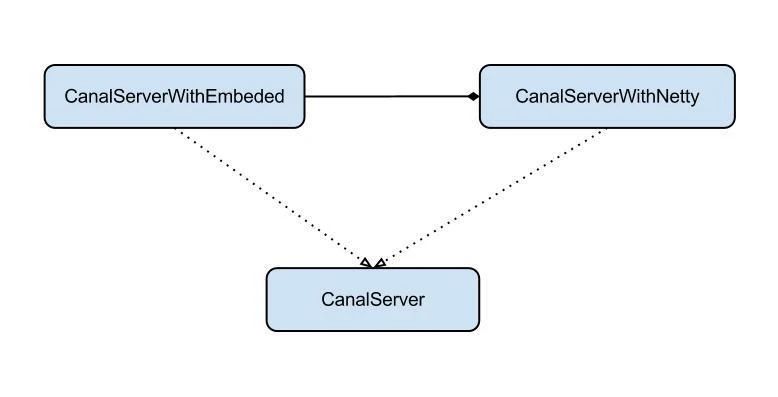
server代表了一个Canal运行实例,为了方便组件化使用,特意抽象了Embeded(嵌入式)/Netty(网络访问)的两种实现。
增量订阅/消费设计:
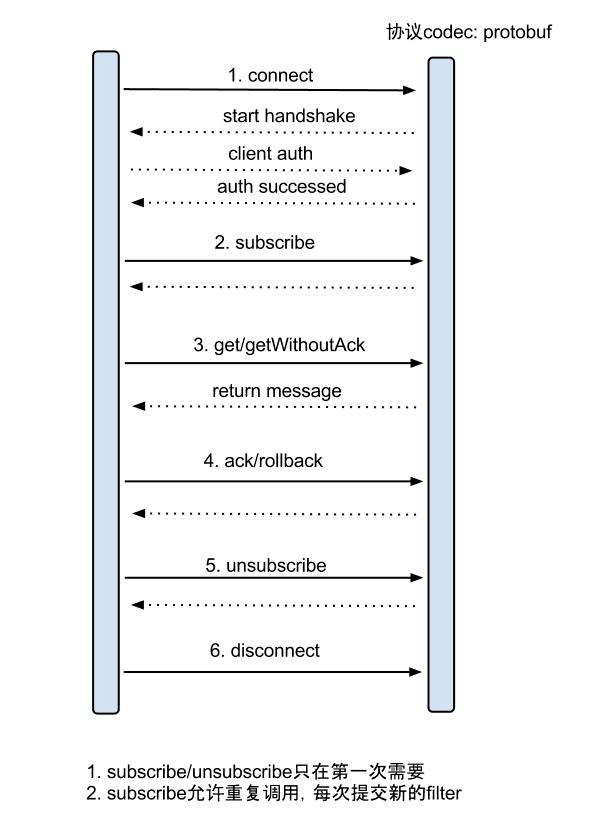
具体的协议格式,可参见:CanalProtocol.proto。数据对象格式:EntryProtocol.proto
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳]
schemaName [数据库实例]
tableName [表名]
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组]
afterColumns [Column类型的数组]
Column
index [column序号]
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为文本]
针对上述的补充说明:
1.可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name、isKey等信息进行补全
2.可以提供ddl的变更语句
Canal HA机制:
Canal的HA实现机制是依赖zookeeper实现的,主要分为Canal server和Canal client的HA。 Canal server:为了减少对MySQL dump的请求,不同server上的instance要求同一时间只能有一个处于running状态,其他的处于standby状态。
Canal client:为了保证有序性,一份instance同一时间只能由一个Canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。 Canal Server HA架构图:

大致步骤:
- Canal server要启动某个Canal instance时都先向Zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建Zookeeper节点成功后,对应的Canal server就启动对应的Canal instance,没有创建成功的Canal instance就会处于standby状态
- 一旦Zookeeper发现Canal server A创建的节点消失后,立即通知其他的Canal server再次进行步骤1的操作,重新选出一个Canal server启动instance
- Canal client每次进行connect时,会首先向Zookeeper询问当前是谁启动了Canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect
Canal Client的方式和Canal server方式类似,也是利用Zookeeper的抢占EPHEMERAL节点的方式进行控制。
到此这篇关于详解监听MySQL的binlog日志工具分析:Canal的文章就介绍到这了,更多相关MySQL的binlog日志内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Mysql数据库之Binlog日志使用总结(必看篇)
binlog二进制日志对于mysql数据库的重要性有多大,在此就不多说了.下面根据本人的日常操作经历,并结合网上参考资料,对binlog日志使用做一梳理: 一.binlog日志介绍 1)什么是binlog binlog日志用于记录所有更新了数据或者已经潜在更新了数据(例如,没有匹配任何行的一个DELETE)的所有语句.语句以"事件"的形式保存,它描述数据更改. 2)binlog作用 因为有了数据更新的binlog,所以可以用于实时备份,与master/slave主从复制结合. 3)和b
-
mysql 正确清理binlog日志的两种方法
mysq 正确清理binlog日志 前言: MySQL中的binlog日志记录了数据库中数据的变动,便于对数据的基于时间点和基于位置的恢复,但是binlog也会日渐增大,占用很大的磁盘空间,因此,要对binlog使用正确安全的方法清理掉一部分没用的日志. [方法一]手动清理binlog 清理前的准备: ① 查看主库和从库正在使用的binlog是哪个文件 show master status\G show slave status\G ② 在删除binlog日志之前,首先对binlog日志备份,以
-
mysql binlog二进制日志详解
基本概念 定义: 二进制日志包含了所有更新了数据或者已经潜在更新了数据(例如,没有匹配任何行的一个DELETE)的所有语句. 作用: 1.二进制日志的主要目的是在恢复使能够最大可能地更新数据库,因为二进制日志包含备份后进行的所有更新. 2.二进制日志还用于在主复制服务器上记录所有将发送给从服务器的语句. 不良影响: 运行服务器时若启用二进制日志则性能大约慢1%. 如何启动: 通过 –log-bin=file选项可以启用 (更改my.ini文件) 日志位置 >>如果没有指定文件名,则Mysql使
-
MySQL 自动清理binlog日志的方法
说明: 开启MySQL binlog日志的服务器,如果不设置自动清理日志,默认binlog日志一直保留着,时间一长,服务器磁盘空间被binlog日志占满,导致MySQL数据库出错. 使用下面方法可以安全清理binlog日志 一.没有主从同步的情况下清理日志 mysql -uroot -p123456 -e 'PURGE MASTER LOGS BEFORE DATE_SUB( NOW( ),INTERVAL 5 DAY)'; #mysql 定时清理5天前的binlog mysql -u root
-
[MySQL binlog]mysql如何彻底解析Mixed日志格式的binlog
mysql binlog3种格式,row,mixed,statement. 解析工作 mysqlbinlog --base64-output=DECODE-ROWS -v mysql-bin.000144 |more --base64-output=DECODE-ROWS: 会显示出row模式带来的sql变更. -v :显示statement模式带来的sql语句 复制代码 代码如下: [mysql@002tmp]$ mysqlbinlog --base64-output=DECODE-ROWS
-
详解监听MySQL的binlog日志工具分析:Canal
Canal是阿里巴巴旗下的一款开源项目,利用Java开发.主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费,目前主要支持MySQL. GitHub地址:https://github.com/alibaba/canal 在介绍Canal内部原理之前,首先来了解一下MySQL Master/Slave同步原理: MySQL master启动binlog机制,将数据变更写入二进制日志(binary log, 其中记录叫做二进制日志事件binary log events,可以通过sho
-

详解如何通过Mysql的二进制日志恢复数据库数据
经常有网站管理员因为各种原因和操作,导致网站数据误删,而且又没有做网站备份,结果不知所措,甚至给网站运营和盈利带来负面影响.所以本文我们将和大家一起分享学习下如何通过Mysql的二机制日志(binlog)来恢复数据. 系统环境: 操作系统:CentOS 6.5 X64 (虚拟机): WEB服务:PHP+Mysql+apache: 网站:为方便,直接在本地用蝉知系统搭建一个DEMO站点: 操作步骤: 1.开启binlog功能及基本操作: 2.往站点添加数据: 3.刷新binlog日志: 4.删除
-
docker开启mysql的binlog日志解决数据卷问题
目录 前言 1.通过数据卷的方式开启一个mysql镜像 2.连接mysql并进行测试 3.开启bin_log 4.重启mysql镜像 5.创建一个数据库并在里面创建一个表加一条数据 结语 前言 在开发中,需要通过监听mysql的binlog日志文件做到对数据表的监控,由于mysql是部署在docker容器中,还需要解决数据卷的问题 1.通过数据卷的方式开启一个mysql镜像 docker run -p 3307:3306 --name myMysql -v /usr/docker/mysql/d
-
MySQL的binlog日志使用详解
binlog 就是binary log,二进制日志文件,这个文件记录了MySQL所有的DML操作.通过binlog日志我们可以做数据恢复,增量备份,主主复制和主从复制等等.对于开发者可能对binlog并不怎么关注,但是对于运维或者架构人员来讲是非常重要的. MySQL 5.7这个版本默认是不开启binlog日志的,具体的开启方式可以查看https://www.jb51.net/article/207953.htm binlog开启成功之后,binlog文件的位置可以在my.inf配置文件中查看.
-
开启MySQL的binlog日志的方法步骤
binlog 就是binary log,二进制日志文件,这个文件记录了mysql所有的dml操作.通过binlog日志我们可以做数据恢复,做主住复制和主从复制等等.对于开发者可能对binlog并不怎么关注,但是对于运维或者架构人员来讲是非常重要的. 如何开启mysql的binlog日志呢? 在my.inf主配置文件中直接添加三行 log_bin=ON log_bin_basename=/var/lib/mysql/mysql-bin log_bin_index=/var/lib/mysql/my
-
Canal监听MySQL的实现步骤
目录 1.Mysql数据库开启binlog模式 2.Docker下Canal容器安装 3.Canal Client项目搭建 1.Mysql数据库开启binlog模式 注意:Mysql容器,此处Mysql版本为5.7 #进入容器 docker exec -it mysql /bin/bash #进入配置目录 cd /etc/mysql/mysql.conf.d #修改配置文件 vi mysqld.cnf (1) 修改mysqld.cnf配置文件,添加如下配置: log-bin=mysql-bin
-
详解GaussDB for MySQL性能优化
背景 我们先来看看MySQL 8.0的事务提交的大致流程 以上流程,是MySQL8.0对WAL原则的一种实现,这个流程意味着,任何一个事务的提交,一定要完成write buffer和flush to disk流程. 然而那么这个流程中,有一个问题:每个服务器的CPU是有限的,服务器能处理的Thread也是有上限的,那么当我们的业务的并发数量,远远大于我们服务器能并行处理的数量时,那么后来的事务,只能等待前面的事务提交后才能被处理.在这之前,他们什么也做不了.因此,在大并发场景下,如何进一步提升线
-
解说mysql之binlog日志以及利用binlog日志恢复数据的方法
众所周知,binlog日志对于mysql数据库来说是十分重要的.在数据丢失的紧急情况下,我们往往会想到用binlog日志功能进行数据恢复(定时全备份+binlog日志恢复增量数据部分),化险为夷! 废话不多说,下面是梳理的binlog日志操作解说: 一.初步了解binlog MySQL的二进制日志binlog可以说是MySQL最重要的日志,它记录了所有的DDL和DML语句(除了数据查询语句select),以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的. ---
-
Laravel给生产环境添加监听事件(SQL日志监听)
本文主要给大家介绍的是关于Laravel给生产环境添加监听事件(SQL日志监听)的相关内容,分享出来供大家参考学习,下面来一起看看详细的介绍: laravel版本:5.2.* 一.创建监听器 php artisan make:listener QueryListener --event=Illuminate\\Database\\Events\\QueryExecuted or sudo /usr/local/bin/php artisan make:listener QueryListener
-
MySQL读取Binlog日志常见的3种错误
1. mysqlbinlog: [ERROR] unknown variable 'default-character-set=utf8mb4' 当我们在my.cnf中添加default-character-set=utf8mb4选项,那么在mysqlbinlog查看binlog时就会报错. 解决方案:.mysqlbinlog 后面添加 --no-defaults 选项 例如: mysql bin可执行文件所在路径/bin/mysqlbinlog --no-defaults binlog所在目录