如何在scrapy中集成selenium爬取网页的方法
1.背景
- 我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。
- 在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。 尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面后台发生了怎样的请求,也不需要分析整个页面的渲染过程,我们只需要关心页面最终结果即可,可见即可爬,但是selenium的效率又太低。
- 所以,如果可以在scrapy中,集成selenium,让selenium负责复杂页面的爬取,那么这样的爬虫就无敌了,可以爬取任何网站了。
2. 环境
- python 3.6.1
- 系统:win7
- IDE:pycharm
- 安装过chrome浏览器
- 配置好chromedriver(设置好环境变量)
- selenium 3.7.0
- scrapy 1.4.0
3.原理分析
3.1. 分析request请求的流程
首先看一下scrapy最新的架构图:
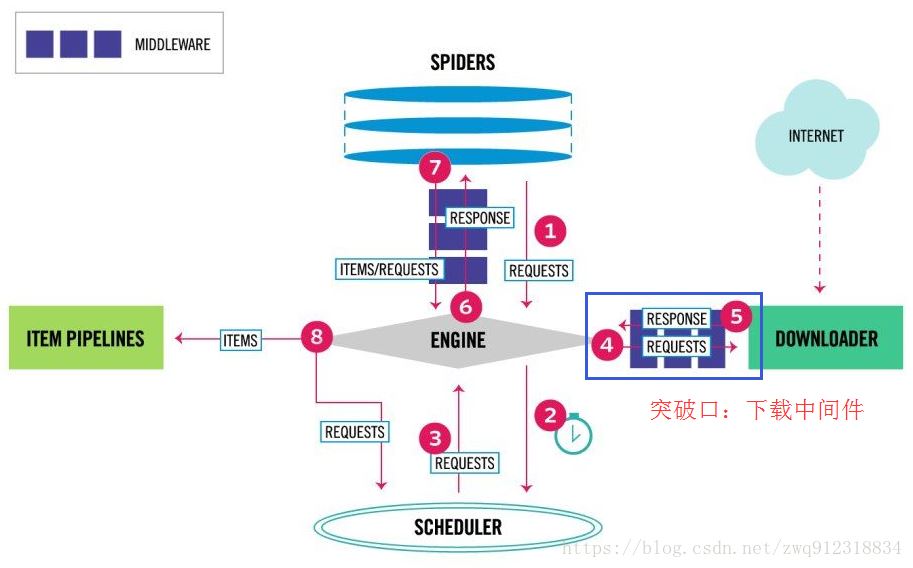
部分流程:
第一:爬虫引擎生成requests请求,送往scheduler调度模块,进入等待队列,等待调度。
第二:scheduler模块开始调度这些requests,出队,发往爬虫引擎。
第三:爬虫引擎将这些requests送到下载中间件(多个,例如加header,代理,自定义等等)进行处理。
第四:处理完之后,送往Downloader模块进行下载。从这个处理过程来看,突破口就在下载中间件部分,用selenium直接处理掉request请求。
3.2. requests和response中间处理件源码分析
相关代码位置:
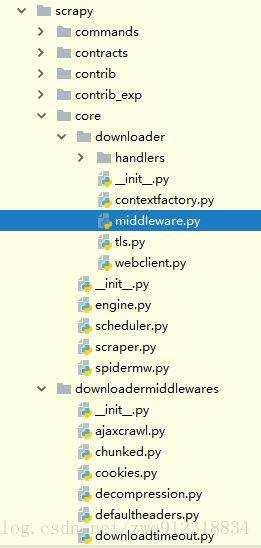
源码解析:
# 文件:E:\Miniconda\Lib\site-packages\scrapy\core\downloader\middleware.py
"""
Downloader Middleware manager
See documentation in docs/topics/downloader-middleware.rst
"""
import six
from twisted.internet import defer
from scrapy.http import Request, Response
from scrapy.middleware import MiddlewareManager
from scrapy.utils.defer import mustbe_deferred
from scrapy.utils.conf import build_component_list
class DownloaderMiddlewareManager(MiddlewareManager):
component_name = 'downloader middleware'
@classmethod
def _get_mwlist_from_settings(cls, settings):
# 从settings.py或这custom_setting中拿到自定义的Middleware中间件
'''
'DOWNLOADER_MIDDLEWARES': {
'mySpider.middlewares.ProxiesMiddleware': 400,
# SeleniumMiddleware
'mySpider.middlewares.SeleniumMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
'''
return build_component_list(
settings.getwithbase('DOWNLOADER_MIDDLEWARES'))
# 将所有自定义Middleware中间件的处理函数添加到对应的methods列表中
def _add_middleware(self, mw):
if hasattr(mw, 'process_request'):
self.methods['process_request'].append(mw.process_request)
if hasattr(mw, 'process_response'):
self.methods['process_response'].insert(0, mw.process_response)
if hasattr(mw, 'process_exception'):
self.methods['process_exception'].insert(0, mw.process_exception)
# 整个下载流程
def download(self, download_func, request, spider):
@defer.inlineCallbacks
def process_request(request):
# 处理request请求,依次经过各个自定义Middleware中间件的process_request方法,前面有加入到list中
for method in self.methods['process_request']:
response = yield method(request=request, spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_request must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, response.__class__.__name__)
# 这是关键地方
# 如果在某个Middleware中间件的process_request中处理完之后,生成了一个response对象
# 那么会直接将这个response return 出去,跳出循环,不再处理其他的process_request
# 之前我们的header,proxy中间件,都只是加个user-agent,加个proxy,并不做任何return值
# 还需要注意一点:就是这个return的必须是Response对象
# 后面我们构造的HtmlResponse正是Response的子类对象
if response:
defer.returnValue(response)
# 如果在上面的所有process_request中,都没有返回任何Response对象的话
# 最后,会将这个加工过的Request送往download_func,进行下载,返回的就是一个Response对象
# 然后依次经过各个Middleware中间件的process_response方法进行加工,如下
defer.returnValue((yield download_func(request=request,spider=spider)))
@defer.inlineCallbacks
def process_response(response):
assert response is not None, 'Received None in process_response'
if isinstance(response, Request):
defer.returnValue(response)
for method in self.methods['process_response']:
response = yield method(request=request, response=response,
spider=spider)
assert isinstance(response, (Response, Request)), \
'Middleware %s.process_response must return Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, type(response))
if isinstance(response, Request):
defer.returnValue(response)
defer.returnValue(response)
@defer.inlineCallbacks
def process_exception(_failure):
exception = _failure.value
for method in self.methods['process_exception']:
response = yield method(request=request, exception=exception,
spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_exception must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, type(response))
if response:
defer.returnValue(response)
defer.returnValue(_failure)
deferred = mustbe_deferred(process_request, request)
deferred.addErrback(process_exception)
deferred.addCallback(process_response)
return deferred
4. 代码
在settings.py中,配置好selenium参数:
# 文件settings.py中 # ----------- selenium参数配置 ------------- SELENIUM_TIMEOUT = 25 # selenium浏览器的超时时间,单位秒 LOAD_IMAGE = True # 是否下载图片 WINDOW_HEIGHT = 900 # 浏览器窗口大小 WINDOW_WIDTH = 900
在spider中,生成request时,标记哪些请求需要走selenium下载:
# 文件mySpider.py中
class mySpider(CrawlSpider):
name = "mySpiderAmazon"
allowed_domains = ['amazon.com']
custom_settings = {
'LOG_LEVEL':'INFO',
'DOWNLOAD_DELAY': 0,
'COOKIES_ENABLED': False, # enabled by default
'DOWNLOADER_MIDDLEWARES': {
# 代理中间件
'mySpider.middlewares.ProxiesMiddleware': 400,
# SeleniumMiddleware 中间件
'mySpider.middlewares.SeleniumMiddleware': 543,
# 将scrapy默认的user-agent中间件关闭
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
#.....................华丽的分割线.......................
# 生成request时,将是否使用selenium下载的标记,放入到meta中
yield Request(
url = "https://www.amazon.com/",
meta = {'usedSelenium': True, 'dont_redirect': True},
callback = self.parseIndexPage,
errback = self.error
)
在下载中间件middlewares.py中,使用selenium抓取页面(核心部分)
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
from scrapy.http import HtmlResponse
from logging import getLogger
import time
class SeleniumMiddleware():
# 经常需要在pipeline或者中间件中获取settings的属性,可以通过scrapy.crawler.Crawler.settings属性
@classmethod
def from_crawler(cls, crawler):
# 从settings.py中,提取selenium设置参数,初始化类
return cls(timeout=crawler.settings.get('SELENIUM_TIMEOUT'),
isLoadImage=crawler.settings.get('LOAD_IMAGE'),
windowHeight=crawler.settings.get('WINDOW_HEIGHT'),
windowWidth=crawler.settings.get('WINDOW_WIDTH')
)
def __init__(self, timeout=30, isLoadImage=True, windowHeight=None, windowWidth=None):
self.logger = getLogger(__name__)
self.timeout = timeout
self.isLoadImage = isLoadImage
# 定义一个属于这个类的browser,防止每次请求页面时,都会打开一个新的chrome浏览器
# 这样,这个类处理的Request都可以只用这一个browser
self.browser = webdriver.Chrome()
if windowHeight and windowWidth:
self.browser.set_window_size(900, 900)
self.browser.set_page_load_timeout(self.timeout) # 页面加载超时时间
self.wait = WebDriverWait(self.browser, 25) # 指定元素加载超时时间
def process_request(self, request, spider):
'''
用chrome抓取页面
:param request: Request请求对象
:param spider: Spider对象
:return: HtmlResponse响应
'''
# self.logger.debug('chrome is getting page')
print(f"chrome is getting page")
# 依靠meta中的标记,来决定是否需要使用selenium来爬取
usedSelenium = request.meta.get('usedSelenium', False)
if usedSelenium:
try:
self.browser.get(request.url)
# 搜索框是否出现
input = self.wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@class='nav-search-field ']/input"))
)
time.sleep(2)
input.clear()
input.send_keys("iphone 7s")
# 敲enter键, 进行搜索
input.send_keys(Keys.RETURN)
# 查看搜索结果是否出现
searchRes = self.wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@id='resultsCol']"))
)
except Exception as e:
# self.logger.debug(f'chrome getting page error, Exception = {e}')
print(f"chrome getting page error, Exception = {e}")
return HtmlResponse(url=request.url, status=500, request=request)
else:
time.sleep(3)
return HtmlResponse(url=request.url,
body=self.browser.page_source,
request=request,
# 最好根据网页的具体编码而定
encoding='utf-8',
status=200)
5. 执行结果

6. 存在的问题
6.1. Spider关闭了,chrome没有退出。
2018-04-04 09:26:18 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 2092766,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 4, 4, 1, 26, 16, 763602),
'log_count/INFO': 7,
'request_depth_max': 1,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 4, 4, 1, 25, 48, 301602)}
2018-04-04 09:26:18 [scrapy.core.engine] INFO: Spider closed (finished)
上面,我们是把browser对象放到了Middleware中间件中,只能做process_request和process_response, 没有说在中间件中介绍如何调用scrapy的close方法。
解决方案:利用信号量的方式,当收到spider_closed信号时,调用browser.quit()
6.2. 当一个项目同时启动多个spider,会共用到Middleware中的selenium,不利于并发。
因为用scrapy + selenium的方式,只有部分,甚至是一小部分页面会用到chrome,既然把chrome放到Middleware中有这么多限制,那为什么不能把chrome放到spider里面呢。这样的好处在于:每个spider都有自己的chrome,这样当启动多个spider时,就会有多个chrome,不是所有的spider共用一个chrome,这对我们的并发是有好处的。
解决方案:将chrome的初始化放到spider中,每个spider独占自己的chrome
7. 改进版代码
在settings.py中,配置好selenium参数:
# 文件settings.py中 # ----------- selenium参数配置 ------------- SELENIUM_TIMEOUT = 25 # selenium浏览器的超时时间,单位秒 LOAD_IMAGE = True # 是否下载图片 WINDOW_HEIGHT = 900 # 浏览器窗口大小 WINDOW_WIDTH = 900
在spider中,生成request时,标记哪些请求需要走selenium下载:
# 文件mySpider.py中
# selenium相关库
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
# scrapy 信号相关库
from scrapy.utils.project import get_project_settings
# 下面这种方式,即将废弃,所以不用
# from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
# scrapy最新采用的方案
from pydispatch import dispatcher
class mySpider(CrawlSpider):
name = "mySpiderAmazon"
allowed_domains = ['amazon.com']
custom_settings = {
'LOG_LEVEL':'INFO',
'DOWNLOAD_DELAY': 0,
'COOKIES_ENABLED': False, # enabled by default
'DOWNLOADER_MIDDLEWARES': {
# 代理中间件
'mySpider.middlewares.ProxiesMiddleware': 400,
# SeleniumMiddleware 中间件
'mySpider.middlewares.SeleniumMiddleware': 543,
# 将scrapy默认的user-agent中间件关闭
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
# 将chrome初始化放到spider中,成为spider中的元素
def __init__(self, timeout=30, isLoadImage=True, windowHeight=None, windowWidth=None):
# 从settings.py中获取设置参数
self.mySetting = get_project_settings()
self.timeout = self.mySetting['SELENIUM_TIMEOUT']
self.isLoadImage = self.mySetting['LOAD_IMAGE']
self.windowHeight = self.mySetting['WINDOW_HEIGHT']
self.windowWidth = self.mySetting['windowWidth']
# 初始化chrome对象
self.browser = webdriver.Chrome()
if self.windowHeight and self.windowWidth:
self.browser.set_window_size(900, 900)
self.browser.set_page_load_timeout(self.timeout) # 页面加载超时时间
self.wait = WebDriverWait(self.browser, 25) # 指定元素加载超时时间
super(mySpider, self).__init__()
# 设置信号量,当收到spider_closed信号时,调用mySpiderCloseHandle方法,关闭chrome
dispatcher.connect(receiver = self.mySpiderCloseHandle,
signal = signals.spider_closed
)
# 信号量处理函数:关闭chrome浏览器
def mySpiderCloseHandle(self, spider):
print(f"mySpiderCloseHandle: enter ")
self.browser.quit()
#.....................华丽的分割线.......................
# 生成request时,将是否使用selenium下载的标记,放入到meta中
yield Request(
url = "https://www.amazon.com/",
meta = {'usedSelenium': True, 'dont_redirect': True},
callback = self.parseIndexPage,
errback = self.error
)
在下载中间件middlewares.py中,使用selenium抓取页面
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
from scrapy.http import HtmlResponse
from logging import getLogger
import time
class SeleniumMiddleware():
# Middleware中会传递进来一个spider,这就是我们的spider对象,从中可以获取__init__时的chrome相关元素
def process_request(self, request, spider):
'''
用chrome抓取页面
:param request: Request请求对象
:param spider: Spider对象
:return: HtmlResponse响应
'''
print(f"chrome is getting page")
# 依靠meta中的标记,来决定是否需要使用selenium来爬取
usedSelenium = request.meta.get('usedSelenium', False)
if usedSelenium:
try:
spider.browser.get(request.url)
# 搜索框是否出现
input = spider.wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@class='nav-search-field ']/input"))
)
time.sleep(2)
input.clear()
input.send_keys("iphone 7s")
# 敲enter键, 进行搜索
input.send_keys(Keys.RETURN)
# 查看搜索结果是否出现
searchRes = spider.wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@id='resultsCol']"))
)
except Exception as e:
print(f"chrome getting page error, Exception = {e}")
return HtmlResponse(url=request.url, status=500, request=request)
else:
time.sleep(3)
# 页面爬取成功,构造一个成功的Response对象(HtmlResponse是它的子类)
return HtmlResponse(url=request.url,
body=spider.browser.page_source,
request=request,
# 最好根据网页的具体编码而定
encoding='utf-8',
status=200)
运行结果(spider结束,执行mySpiderCloseHandle关闭chrome浏览器):
['categorySelectorAmazon1.pipelines.MongoPipeline']
2018-04-04 11:56:21 [scrapy.core.engine] INFO: Spider opened
2018-04-04 11:56:21 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
chrome is getting page
parseProductDetail url = https://www.amazon.com/, status = 200, meta = {'usedSelenium': True, 'dont_redirect': True, 'download_timeout': 25.0, 'proxy': 'http://H37XPSB6V57VU96D:CAB31DAEB9313CE5@proxy.abuyun.com:9020', 'depth': 0}
chrome is getting page
2018-04-04 11:56:54 [scrapy.core.engine] INFO: Closing spider (finished)
mySpiderCloseHandle: enter
2018-04-04 11:56:59 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 1938619,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 4, 4, 3, 56, 54, 301602),
'log_count/INFO': 7,
'request_depth_max': 1,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2018, 4, 4, 3, 56, 21, 642602)}
2018-04-04 11:56:59 [scrapy.core.engine] INFO: Spider closed (finished)
到此这篇关于如何在scrapy中集成selenium爬取网页的方法的文章就介绍到这了,更多相关scrapy集成selenium爬取网页内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
scrapy与selenium结合爬取数据(爬取动态网站)的示例代码
scrapy框架只能爬取静态网站.如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据. 如何通过selenium请求url,而不再通过下载器Downloader去请求这个url? 方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源 代码通过response对象返回,直接交给process_response()进行处理,再交给引擎.过程中相当于后续中间件的process_req
-
scrapy利用selenium爬取豆瓣阅读的全步骤
首先创建scrapy项目 命令:scrapy startproject douban_read 创建spider 命令:scrapy genspider douban_spider url 网址:https://read.douban.com/charts 关键注释代码中有,若有不足,请多指教 scrapy项目目录结构如下 douban_spider.py文件代码 爬虫文件 import scrapy import re, json from ..items import DoubanReadI
-
Scrapy基于selenium结合爬取淘宝的实例讲解
在对于淘宝,京东这类网站爬取数据时,通常直接使用发送请求拿回response数据,在解析获取想要的数据时比较难的,因为数据只有在浏览网页的时候才会动态加载,所以要想爬取淘宝京东上的数据,可以使用selenium来进行模拟操作 对于scrapy框架,下载器来说已经没多大用,因为获取的response源码里面没有想要的数据,因为没有加载出来,所以要在请求发给下载中间件的时候直接使用selenium对请求解析,获得完整response直接返回,不经过下载器下载,上代码 from selenium im
-
如何在scrapy中集成selenium爬取网页的方法
1.背景 我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium.requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化). 在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦. 尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面后台发生了怎样的请求,也不需要分析整
-
Python3爬虫之urllib携带cookie爬取网页的方法
如下所示: import urllib.request import urllib.parse url = 'https://weibo.cn/5273088553/info' #正常的方式进行访问 # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36' # } # 携带
-
Scrapy项目实战之爬取某社区用户详情
本文介绍了Scrapy项目实战之爬取某社区用户详情,分享给大家,具有如下: get_cookies.py from selenium import webdriver from pymongo import MongoClient from scrapy.crawler import overridden_settings # from segmentfault import settings import time import settings class GetCookies(object
-
如何在scrapy中捕获并处理各种异常
前言 使用scrapy进行大型爬取任务的时候(爬取耗时以天为单位),无论主机网速多好,爬完之后总会发现scrapy日志中"item_scraped_count"不等于预先的种子数量,总有一部分种子爬取失败,失败的类型可能有如下图两种(下图为scrapy爬取结束完成时的日志): scrapy中常见的异常包括但不限于:download error(蓝色区域), http code 403/500(橙色区域). 不管是哪种异常,我们都可以参考scrapy自带的retry中间件写法来编写自己的
-

python Selenium爬取内容并存储至MySQL数据库的实现代码
前面我通过一篇文章讲述了如何爬取CSDN的博客摘要等信息.通常,在使用Selenium爬虫爬取数据后,需要存储在TXT文本中,但是这是很难进行数据处理和数据分析的.这篇文章主要讲述通过Selenium爬取我的个人博客信息,然后存储在数据库MySQL中,以便对数据进行分析,比如分析哪个时间段发表的博客多.结合WordCloud分析文章的主题.文章阅读量排名等. 这是一篇基础性的文章,希望对您有所帮助,如果文章中出现错误或不足之处,还请海涵.下一篇文章会简单讲解数据分析的过程. 一. 爬取的结果 爬
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页
-
c# Selenium爬取数据时防止webdriver封爬虫的方法
背景 大家在使用Selenium + Chromedriver爬取网站信息的时候,以为这样就能做到不被网站的反爬虫机制发现.但是实际上很多参数和实际浏览器还是不一样的,只要网站进行判断处理,就能轻轻松松识别你是否使用了Selenium + Chromedriver模拟浏览器.其中 window.navigator.webdriver 就是很重要的一个. 问题窥探 正常浏览器打开是这样的 模拟器打开是这样的 ChromeOptions options = null; IWebDriver driv
-
详解如何在Flutter中集成华为认证服务
最近发现华为AGC认证服务支持Flutter框架了,期待这个平台的支持已经很久了,所以迫不及待接入了,关联了自己的邮箱等账号. 集成步骤 安装flutter环境 a) 下载Flutter sdk包,地址:https://flutter.dev/docs/get-started/install/windows 将压缩包解压到任意文件夹,例如D:\Flutter b) 将flutter命令文件添加到环境变量中,此处我添加的Path为D:\Flutter\flutter_windows_1.22.2-
-
python基于selenium爬取斗鱼弹幕
针对弹幕的爬取我们如果只需要获取看到的网页里面的而数据,使用selenium就能实现,对于直播平台来说,往往有第三方平台api让你获取数据(可以获取发弹幕,发弹幕者的名字礼物等等,这需要客户端向弹幕服务器发送登录请求,心跳信息的发送等等)只获取弹幕信息储存到txt文件中,上代码,上图片 代码如下: import time from selenium import webdriver chrome_options = webdriver.ChromeOptions() # 使用headless无界