正则表达式常见的4种匹配模式小结
目录
- 0.写在前面
- 1.不区分大小写模式
- 2.点号通配模式
- 3.多行匹配模式
- 4.注释模式
- 5.写在最后
0.写在前面
今天一起来学习下正则中的匹配模式,所谓的匹配模式,就是指正则中的一些 改变元字符匹配行为 的方式,比如匹配时不区分英文字母的大小写。
还记得我们在第二篇文章中学过的贪婪模式、非贪婪模式和独占模式吗,这些模式会改变正则中量词的匹配行为,今天来看一些和量词无关的匹配模式,一共有4种,分别是不区分大小写模式、点号通配模式、多行匹配模式、注释模式。
1.不区分大小写模式
顾名思义,不区分大小写模式就是我想要匹配目标字符串中的Cat,我不关心是大猫CAT,还是小猫cat,只要给我匹配上就可以了。
模式修饰符是通过 (?模式标识) 的方式来表示的,我们只需要把模式修饰符放在对应的正则前面,就可以使用指定的模式了,
不区分大小写的英文是 Case-Insensitive,模式标识用首字母的小写来表示就是 (?i),上面提到的栗子正则可以这么写 (?i)cat,看下:

上一篇文章中,我们学习了分组与引用,如果匹配两个猫就是 (?i)(cat) \1:

对应的 Python 代码如下:
import re
result = re.findall(r"(?i)(cat) (\1)", "cat cat CAT Cat")
print(result)
输出:[('cat', 'cat'), ('CAT', 'Cat')]
可以看到,前后两个cat大小写不一致,也可以匹配上,如果我们想要匹配前后大小写一致的猫该怎么办呢,可以在外面加上一层括号 ((?i)cat) \1,看下:
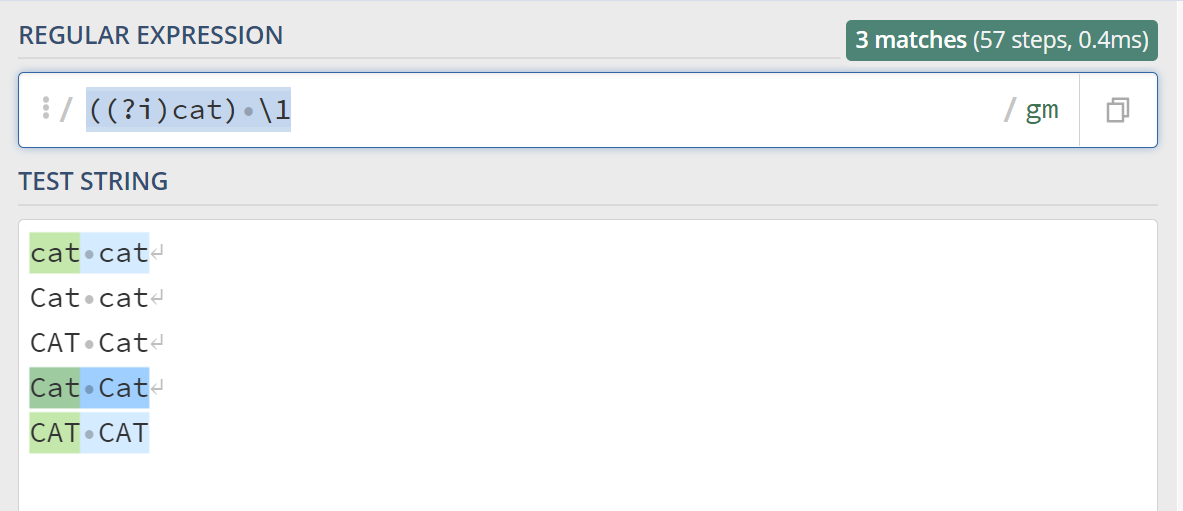
测试链接:https://regex101.com/r/tPXuGX/1
注意:在 Python 语言中,使用 re 库调用上面的正则会报下面的异常,换成 regex 库就可以,但是不能准确的匹配两个大小写一致的 cat。
DeprecationWarning: Flags not at the start of the expression
import regex
result = regex.findall(r"((?i)cat) (\1)", "cat cat CAT Cat")
print(result)
输出:[('cat', 'cat'), ('CAT', 'Cat')]
2.点号通配模式
在第一篇文章中,我们学习了元字符的相关知识,还记的英文的点 . 代表什么含义吗,它可以匹配任意字符,但是不能匹配换行。当我们需要匹配真正的任意字符时,可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等来表示。

但是这样写不够优雅,所以正则提供了一种模式,让英文的 . 能够匹配上换行在内的所有字符,这种模式就叫做点号通配模式。
点号通配模式,在很多地方被称为单行模式,英文表示为 Single Line,取其首字母,所以单行模式对应的修饰符是 (?s),举个栗子:

3.多行匹配模式
在正则中 ^ 用于匹配整个目标字符串的开头,$ 用户匹配整个目标字符串的结尾:

如果我们想要让表达式匹配上每行的开头和结尾呢,多行匹配模式就上场了,多行的英文是 Multiline,所以多行模式对应的修饰符是 (?m),看下效果:

4.注释模式
当我们写了一大长串的表达式之后,当时可能只有你和上帝知道它什么意思,过了半年,就只有上帝知道它什么意思了。
注释的英文是 Comment,所以注释模式对应的修饰符是 (?#comment),注意没有用首字母,还多了一个 # 号,拿我们之前写的 IPv4 地址匹配正则举个例:
^(?:[1-9][0-9]?|1[0-9][0-9]|2[0-4][0-9]|25[0-5])(?#comment IP地址第一个值)(?:\.(?:0|[1-9][0-9]?|1[0-9][0-9]|2[0-4][0-9]|25[0-5])){3}(?#comment IP地址后三个值)$
在很多编程语言中也提供了 x 模式来书写正则,也可以起到注释的作用,以 Python 为例:
import re
regex = r'''(?mx) # 使用多行模式和x模式
^ # 开头
(\d{4}) # 年
(\d{2}) # 月
$ # 结尾
'''
result = re.findall(regex, '202006\n202106')
print(result)
输出:[('2020', '06'), ('2021', '06')]
在 x 模式下,所有的换行和空格都会被忽略,如果要匹配的话,可以把换行和空格转义,或者放在字符组中:
import re
regex = r'''(?mx) # 使用多行模式和x模式
^ # 开头
(\d{4}) # 年
[ ] # 空格
(\d{2}) # 月
$ # 结尾
'''
result = re.findall(regex, '2020 06\n2021 06')
print(result)
输出:[('2020', '06'), ('2021', '06')]
5.写在最后
最后在总结下上面讲到的内容:

正则表达式在线校验工具:https://regex101.com/
到此这篇关于正则表达式常见的4种匹配模式小结的文章就介绍到这了,更多相关正则表达式 匹配模式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java 正则表达式匹配模式(贪婪型、勉强型、占有型)
Greediness(贪婪型):最大匹配 X?.X*.X+.X{n,} 是最大匹配.例如你要用 "<.+>" 去匹配 "a<tr>aava </tr>abb",也许你所期待的结果是想匹配 "<tr>",但是实际结果却会匹配到 "<tr>aava </tr>. 在 Greediness 的模式下,会尽量大范围的匹配,直到匹配了整个内容,这时发现匹配不能成功时,开始回退
-
JS中正则表达式全局匹配模式 /g用法详解
本文章来详细介绍js中正则表达式的全局匹配模式 /g用法,代码如下: var str = "123#abc"; var re = /abc/ig; console.log(re.test(str)); //输出ture console.log(re.test(str)); //输出false console.log(re.test(str)); //输出ture console.log(re.test(str)); //输出false 在创建正则表达式对象时如果使用了"g&q
-

正则表达式中最短匹配模式的用法浅析
前言 最近有一次想用正则表达式从网页里面抓取一些东西出来,内容不复杂却出现不少问题.下面话不多说,来一起看看详细的介绍: 当我们用正则表达式去匹配一个标签的首尾的时候,比如匹配 <h1>hello world</h1> 中的 h1 的开始和闭合标签 可能很多人会这样写 /<.*h1>/g 但是这样真的可以吗? 因为 * 匹配符是匹配前面一个字符的零到多个,而且它是贪婪匹配的 所以你得到的就会是下面的结果了. 显然这并不是我们想要的,那么怎么把贪婪匹配换成最小匹配呢, /
-
正则表达式全局匹配模式(g修饰符)
正则表达式g修饰符: g修饰符用语规定正则表达式执行全局匹配,也就是在找到第一个匹配之后仍然会继续查找. 语法结构: 构造函数方式: new RegExp("regexp","g") 对象直接量方式: /regexp/g 浏览器支持: IE浏览器支持此元字符. 火狐浏览器支持此元字符. 谷歌浏览器支持此元字符. 实例代码: 实例一: var str="this is an antzone good"; var reg=/an/; console.
-
正则表达式惰性匹配模式(?)
正则表达式惰性匹配模式: 在贪婪匹配模式一章节已经说过人性是贪婪的,希望获得更多的金钱.地位甚至美女,但是也有很多清心寡欲的人,只要满足基本的生活需求就可以了,在正则表达式中也有这样的匹配原则,下面就进行一下介绍. 一.惰性模式的概念: 此模式和贪婪模式恰好相反,它尽可能少的匹配字符以满足正则表达式即可,例如: var str="axxyyzbdkb"; console.log(str.match(/a.*b/)); 以上代码是贪婪模式,于是能够匹配整个字符串,下面将其修改成惰性匹配模
-
正则表达式常见的4种匹配模式小结
目录 0.写在前面 1.不区分大小写模式 2.点号通配模式 3.多行匹配模式 4.注释模式 5.写在最后 0.写在前面 今天一起来学习下正则中的匹配模式,所谓的匹配模式,就是指正则中的一些 改变元字符匹配行为 的方式,比如匹配时不区分英文字母的大小写. 还记得我们在第二篇文章中学过的贪婪模式.非贪婪模式和独占模式吗,这些模式会改变正则中量词的匹配行为,今天来看一些和量词无关的匹配模式,一共有4种,分别是不区分大小写模式.点号通配模式.多行匹配模式.注释模式. 1.不区分大小写模式 顾名思义,不区
-
JS中正则表达式只有3种匹配模式(没有单行模式)详解
JS正则表达式对象模式仅有如下三种: g (全文查找出现的所有 pattern) i (忽略大小写) m (多行查找) 即没有单行匹配模式,Singleline(单行模式):更改.的含义,使它与每一个字符匹配(包括换行符\n). 如java中 String regex = "(?s)(?<=interface).{0,500}(shutdown)";---------"."表示在一行. 但可以采用[\d\D]或[\w\W]或[\s\S]或(.|\s)*?来解
-
C#中正则表达式的3种匹配模式
在C#中,我们一般使用Regex类来表示一个正则表达式.一般正则表达式引擎支持以下3种匹配模式:单行模式(Singleline).多行模式(Multiline)与忽略大小写(IgnoreCase). 1. 单行模式(Singleline) MSDN定义:更改点 (.) 的含义,使它与每一个字符匹配(而不是与除 \n 之外的每个字符匹配). 使用单行模式的典型场景是获取网页源码中的信息. 示例: 我们使用WebBrowser控件,从http://www.xxx.com/1.htm上获取了如下HTM
-
Android常见的几种内存泄漏小结
一.背景 最近在项目的版本迭代中,出现了一些内存问题的小插曲,然后自己花了一些时间优化了APP运行时内存大小的问题,特此做个总结,与大家分享. 二.简介 在Android程序开发中,当一个对象已经不需要再使用了,本该被回收时,而另外一个正在使用的对象持有它的引用从而导致它不能被回收,这就导致本该被回收的对象不能被回收而停留在堆内存中,内存泄漏就产生了.内存泄漏有什么影响呢?它是造成应用程序OOM的主要原因之一.由于Android系统为每个应用程序分配的内存有限,当一个应用中产生的内存泄漏比较多时
-
SpringSecurity oAuth2.0的四种模式(小结)
目录 1.1. 授权码授权模式(Authorization code Grant) 1.1.1. 流程图 1.1.2. 授权服务器配置配置 1.1.3. 资源服务器配置 1.1.5. 使用场景 1.2. 隐式授权模式(Implicit Grant) 1.2.1. 流程图 1.2.2. 改动 authorizedGrantTypes 1.2.3. 操作步骤 1.2.4. 使用场景 1.3. 密码模式(Resource Owner Password Credentials Grant) 1.3.1.
-
PHP常见的几种攻击方式实例小结
本文实例总结了PHP常见的几种攻击方式.分享给大家供大家参考,具体如下: 1.SQL Injection(sql注入) ①.暴字段长度 Order by num/* ②.匹配字段 and 1=1 union select 1,2,3,4,5--.n/* ③.暴露字段位置 and 1=2 union select 1,2,3,4,5-..n/* ④.利用内置函数暴数据库信息 version() database() user() 不用猜解可用字段暴数据库信息(有些网站不适用): and 1=2 u
-
正则表达式之 贪婪与非贪婪模式详解(概述)
1 概述 贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配.非贪婪模式只被部分NFA引擎所支持. 属于贪婪模式的量词,也叫做匹配优先量词,包括: "{m,n}"."{m,}"."?"."*"和"+". 在一些使用NFA引擎的语言中,在匹配优先量词后加上"?",即变成属于非