Pandas中的 transform()结合 groupby()用法示例详解
首先,假设我们有如下餐厅数据集:
import pandas as pd
df = pd.DataFrame({
'restaurant_id': [101,102,103,104,105,106,107],
'address': ['A','B','C','D', 'E', 'F', 'G'],
'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'],
'sales': [10,500,48,12,21,22,14]
})

如果我们想知道:每个餐厅在城市中所占的销售额百分比是多少?预期得到的输出是:

相比于原来的数据集,多了两列,分别是某个城市所有餐厅的销售总额,以及每个餐厅在城市中所占的销售额百分比。解决方案有两个:
方案一(较麻烦):
1、使用 groupby('city') 基于城市进行分组,对于这些组中的每一个组,选中其销售额列 ['sales'],然后使用函数 apply(sum) 或者sum() 对城市的销售额进行求和。
之后,新列被重命名为 city_total_sales 并且索引被重置(注意不能漏了 reset_index() ,因为 groupby('city') 生成的索引是城市,而我们希望城市作为普通列)。
city_sales = df.groupby('city')['sales']
.sum().rename('city_total_sales').reset_index()
得到的 city_sales 如下:

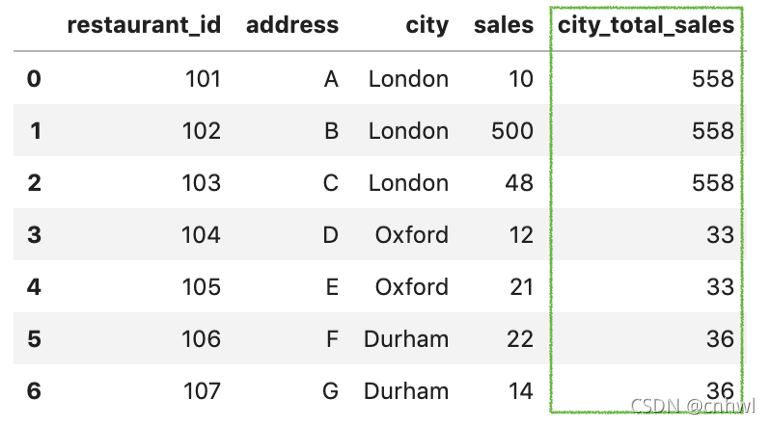
2、用 merge() 函数把 city_sales 合并回去,得到的 df_new 如下:
df_new = pd.merge(df, city_sales, how='left')
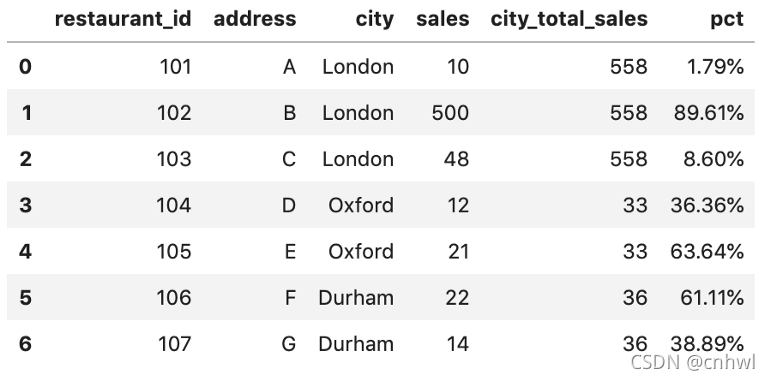
3、最后,求百分比并保留两位小数,结果如下:
df_new['pct'] = df_new['sales'] / df_new['city_total_sales'] df_new['pct'] = df_new['pct'].apply(lambda x: format(x, '.2%'))
方案二(便捷):
1、
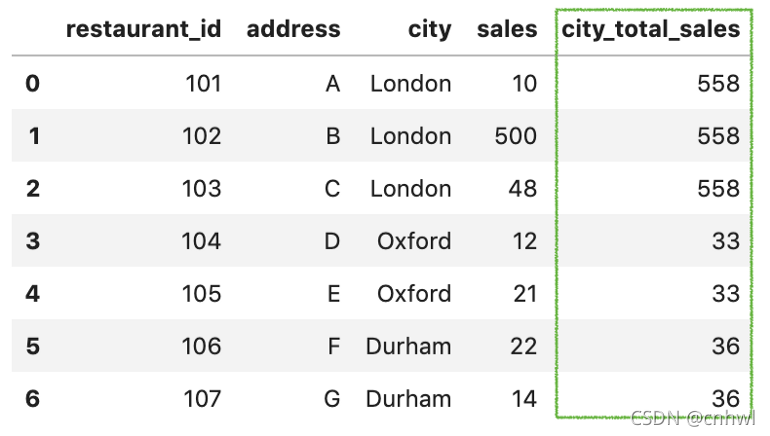
transform() 函数在执行转换后保留与原始数据集相同数量的项目。因此,使用 groupby() 然后使用 transform(sum) 会返回相同的输出,结果如下图:
df['city_total_sales'] = df.groupby('city')['sales']
.transform('sum')
代码翻译过来就是:数据集基于城市进行分组,然后选定销售额列,对每组的销售额进行求和,返回一个和原列长度一样的新列。
2、
与方案一相同。
df['pct'] = df['sales'] / df['city_total_sales'] df['pct'] = df['pct'].apply(lambda x: format(x, '.2%'))
总结:可以看出,在对 DataFrame 进行分组 groupby() 之后,如果是使用 apply() 或者直接使用某个统计函数,得到的新列的长度与分组得到的组数是一样的;而如果使用 transform() ,得到的新列与 DataFrame 中列的长度是一样的。
到此这篇关于Pandas中的 transform()结合 groupby()用法示例详解的文章就介绍到这了,更多相关Pandas groupby() 用法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pandas数据分组groupby()和统计函数agg()的使用
数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据 准备数据 # 一个Series其实就是一条数据,Series方法的第一个参数是data,第二个参数是index(索引),如果没有传值会使用默认值(0-N) # index参数是我们自定义的索引值,注意:参数值的个数一定要相同. # 在创建Series时数据并不一定要是列表,也可以将一个字典
-
分享Pandas库中的一些宝藏函数transform()
Pandas函数的核心功能是,既计算了统计值,又保留了明细数据.为了更好地理解transform和agg的不同,下面从实际的应用场景出发进行对比. aggregation会返回数据的缩减版本,而transformation能返回完整数据的某一变换版本供我们重组.这样的transformation,输出的形状和输入一致.一个常见的例子是通过减去分组平均值来居中数据. #数据构造 data = pd.DataFrame( {"company":['百度', '阿里', '百度', '阿里'
-
pandas之分组groupby()的使用整理与总结
前言 在使用pandas的时候,有些场景需要对数据内部进行分组处理,如一组全校学生成绩的数据,我们想通过班级进行分组,或者再对班级分组后的性别进行分组来进行分析,这时通过pandas下的groupby()函数就可以解决.在使用pandas进行数据分析时,groupby()函数将会是一个数据分析辅助的利器. groupby的作用可以参考 超好用的 pandas 之 groupby 中作者的插图进行直观的理解: 准备 读入的数据是一段学生信息的数据,下面将以这个数据为例进行整理grouby()函数的
-
Pandas中的 transform()结合 groupby()用法示例详解
首先,假设我们有如下餐厅数据集: import pandas as pd df = pd.DataFrame({ 'restaurant_id': [101,102,103,104,105,106,107], 'address': ['A','B','C','D', 'E', 'F', 'G'], 'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'], 'sales': [10,500,48,12,2
-
python中前缀运算符 *和 **的用法示例详解
这篇主要探讨 ** 和 * 前缀运算符,**在变量之前使用的*and **运算符. 一个星(*):表示接收的参数作为元组来处理 两个星(**):表示接收的参数作为字典来处理 简单示例: >>> numbers = [2, 1, 3, 4, 7] >>> more_numbers = [*numbers, 11, 18] >>> print(*more_numbers, sep=', ') 2, 1, 3, 4, 7, 11, 18 用途: 使用 * 和
-
SQL Server中row_number函数的常见用法示例详解
一.SQL Server Row_number函数简介 ROW_NUMBER()是一个Window函数,它为结果集的分区中的每一行分配一个连续的整数. 行号以每个分区中第一行的行号开头. 以下是ROW_NUMBER()函数的语法实例: select *,row_number() over(partition by column1 order by column2) as n from tablename 在上面语法中: PARTITION BY子句将结果集划分为分区. ROW_NUMBER()函
-
golang中的三个点 '...'的用法示例详解
'-' 其实是go的一种语法糖. 它的第一个用法主要是用于函数有多个不定参数的情况,可以接受多个不确定数量的参数. 第二个用法是slice可以被打散进行传递. 下面直接上例子: func test1(args ...string) { //可以接受任意个string参数 for _, v:= range args{ fmt.Println(v) } } func main(){ var strss= []string{ "qwr", "234", "yui
-
Java中枚举类的用法示例详解
目录 1.引入枚举类 2.实现枚举类 3.枚举类的使用注意事项 4.枚举的常用方法 5.enum细节 1.引入枚举类 Java 枚举是一个特殊的类,一般表示一组常量,比如一年的 4 个季节,一个年的 12 个月份,一个星期的 7 天,方向有东南西北等. Java 枚举类使用 enum 关键字来定义,各个常量使用逗号 , 来分割. 示例: enum Color { RED, GREEN, BLUE; } 2.实现枚举类 接下来我们来看一个一个简单的DEMO示例: /** * java枚举 */ p
-
MySQL中使用去重distinct方法的示例详解
一 distinct 含义:distinct用来查询不重复记录的条数,即distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段 用法注意: 1.distinct[查询字段],必须放在要查询字段的开头,即放在第一个参数: 2.只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用: 3.DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,即查出的参数拼接每行记录
-
python编程中简洁优雅的推导式示例详解
目录 1. 列表推导式 增加条件语句 多重循环 更多用法 2. 字典推导式 3. 集合推导式 4. 元组推导式 Python语言有一种独特的推导式语法,相当于语法糖的存在,可以帮助你在某些场合写出较为精简酷炫的代码.但没有它,也不会有太多影响.Python语言有几种不同类型的推导式. 1. 列表推导式 列表推导式是一种快速生成列表的方式.其形式是用方括号括起来的一段语句,如下例子所示: lis = [x * x for x in range(1, 10)] print(lis) 输出 [1, 4
-
支持PyTorch的einops张量操作神器用法示例详解
目录 基础用法 高级用法 今天做visual transformer研究的时候,发现了einops这么个神兵利器,决定大肆安利一波. 先看链接:https://github.com/arogozhnikov/einops 安装: pip install einops 基础用法 einops的强项是把张量的维度操作具象化,让开发者"想出即写出".举个例子: from einops import rearrange # rearrange elements according to the
-
Go语言基础go接口用法示例详解
目录 概述 语法 定义接口 实现接口 空接口 接口的组合 总结 概述 Go 语言中的接口就是方法签名的集合,接口只有声明,没有实现,不包含变量. 语法 定义接口 type [接口名] interface { 方法名1(参数列表) 返回值列表 方法名2(参数列表) 返回值列表 ... } 例子 type Isay interface{ sayHi() } 实现接口 例子 //定义接口的实现类 type Chinese struct{} //实现接口 func (_ *Chinese) sayHi(
-
JavaScript事件的委托(代理)的用法示例详解
目录 简介 示例:事件委托 写法1:事件委托 写法2:每个子元素都绑定事件 示例:新增元素 写法1:事件委托 写法2:每个子元素都绑定事件 简介 说明 本文用示例介绍JavaScript中的事件(Event)的委托(代理)的用法. 事件委托简介 事件委托,也叫事件代理,是JavaScript中绑定事件的一种常用技巧.就是将原本需要绑定在子元素的响应事件委托给父元素或更外层元素,让外层元素担当事件监听的职务. 事件代理的原理是DOM元素的事件冒泡. 事件委托的优点 1.节省内存,减少事件的绑定 原