从np.random.normal()到正态分布的拟合操作
先看伟大的高斯分布(Gaussian Distribution)的概率密度函数(probability density function):
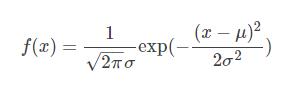
对应于numpy中:
numpy.random.normal(loc=0.0, scale=1.0, size=None)
参数的意义为:
loc:float
此概率分布的均值(对应着整个分布的中心centre)
scale:float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints
输出的shape,默认为None,只输出一个值
我们更经常会用到的np.random.randn(size)所谓标准正态分布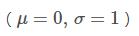
对应于np.random.normal(loc=0, scale=1, size)。
采样(sampling)
# 从某一分布(由均值和标准差标识)中获得样本 mu, sigma = 0, .1 s = np.random.normal(loc=mu, scale=sigma, size=1000)
也可使用scipy库中的相关api(这里的类与函数更符合数理统计中的直觉):
import scipy.stats as st mu, sigma = 0, .1 s = st.norm(mu, sigma).rvs(1000)
校验均值和方差:
>>> abs(mu < np.mean(s)) < .01
True
>>> abs(sigma-np.std(s, ddof=1)) < .01
True
# ddof,delta degrees of freedom,表示自由度
# 一般取1,表示无偏估计,
拟合
我们看使用matplotlib.pyplot便捷而强大的语法如何进行高斯分布的拟合:
import matplotlib.pyplot as plt
count, bins, _ = plt.hist(s, 30, normed=True)
# normed是进行拟合的关键
# count统计某一bin出现的次数,在Normed为True时,可能其值会略有不同
plt.plot(bins, 1./(np.sqrt(2*np.pi)*sigma)*np.exp(-(bins-mu)**2/(2*sigma**2), lw=2, c='r')
plt.show()
或者:
s_fit = np.linspace(s.min(), s.max()) plt.plot(s_fit, st.norm(mu, sigma).pdf(s_fit), lw=2, c='r')
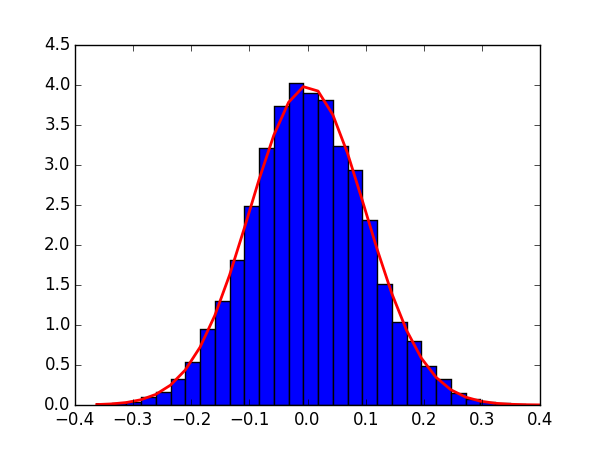
np.random.normal()的含义及实例
这是个随机产生正态分布的函数。(normal 表正态)
先看一下官方解释:
有三个参数
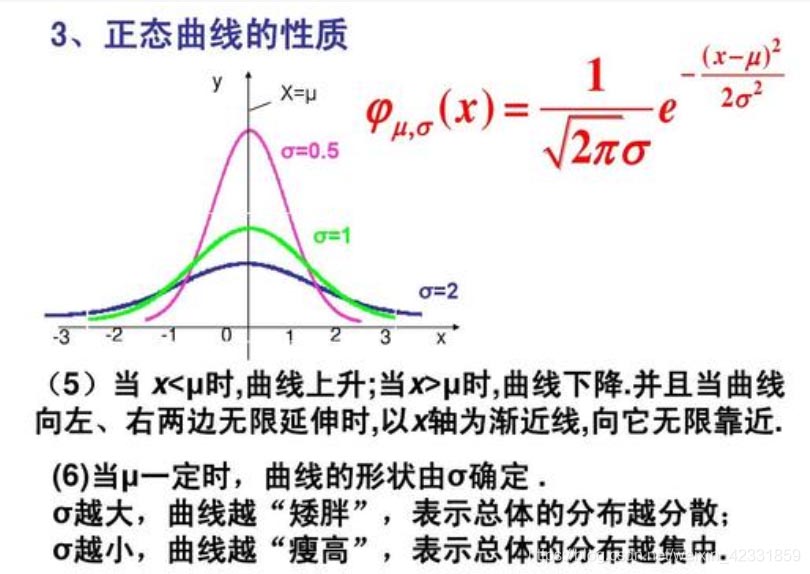
loc:正态分布的均值,对应着这个分布的中心.代表下图的μ
scale:正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线 越矮胖,scale越小,曲线越高瘦。 代表下图的σ
size:你输入数据的shape,例子:
下面展示一些 内联代码片。
// An highlighted block a=np.random.normal(0, 1, (2, 4)) print(a) 输出: [[-0.29217334 0.41371571 1.26816017 0.46474676] [ 1.33271487 0.80162296 0.47974157 -1.49748788]]
看这个图直观些:
以下为官方文档:


以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Numpy之random函数使用学习
random模块用于生成随机数,下面看看模块中一些常用函数的用法: numpy.random.rand(d0, d1, ..., dn):生成一个[0,1)之间的随机浮点数或N维浮点数组. #numpy.random.rand(d0, d1, ..., dn) import numpy as np #无参 np.random.rand()#生成生成[0,1)之间随机浮点数 type(np.random.rand())#float #d0,d1....表示传入的数组形状 #一个参数 np.rand
-
python numpy之np.random的随机数函数使用介绍
np.random的随机数函数(1) 函数 说明 rand(d0,d1,..,dn) 根据d0‐dn创建随机数数组,浮点数, [0,1),均匀分布 randn(d0,d1,..,dn) 根据d0‐dn创建随机数数组,标准正态分布 randint(low[,high,shape]) 根据shape创建随机整数或整数数组,范围是[low, high) seed(s) 随机数种子, s是给定的种子值 np.random.rand import numpy as np a = np.random.ran
-
Numpy中np.random.rand()和np.random.randn() 用法和区别详解
numpy.random.rand(d0, d1, -, dn)的随机样本位于[0, 1)中:本函数可以返回一个或一组服从**"0~1"均匀分布**的随机样本值. numpy.random.randn(d0, d1, -, dn)是从标准正态分布中返回一个或多个样本值. 1. np.random.rand() 语法: np.random.rand(d0,d1,d2--dn) 注:使用方法与np.random.randn()函数相同 作用: 通过本函数可以返回一个或一组服从"0
-

从np.random.normal()到正态分布的拟合操作
先看伟大的高斯分布(Gaussian Distribution)的概率密度函数(probability density function): 对应于numpy中: numpy.random.normal(loc=0.0, scale=1.0, size=None) 参数的意义为: loc:float 此概率分布的均值(对应着整个分布的中心centre) scale:float 此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高) size:int or tuple
-
python人工智能tensorflow函数np.random模块使用方法
目录 np.random模块常用的一些方法介绍 例子 numpy.random.rand(d0, d1, …, dn): numpy.random.randn(d0, d1, …, dn): numpy.random.randint(low, high=None, size=None, dtype=‘I’): numpy.random.uniform(low=0.0, high=1.0, size=None): numpy.random.normal(loc=0.0, scale=1.0, si
-
Python numpy中np.random.seed()的详细用法实例
目录 引言 E.G.实验 E.G.随机数种子参数的作用 补充:一个随机种子在代码中只作用一次,只作用于其定义位置的下一次随机数生成 总结 引言 在进行机器学习和深度学习中,我们会经常用到np.random.seed(),利用随机数种子,使得每次生成的随机数相同. numpy.randn.randn(d0,d1,...,dn) randn函数根据给定维度生成大概率在(-2.58~+2.58)之间的数据 randn函数返回一个或者一组样本,具有标准正态分布 dn表示每个维度 返回值为指定维度的arr
-
np.random.seed() 的使用详解
在学习人工智能时,大量的使用了np.random.seed(),利用随机数种子,使得每次生成的随机数相同. 我们带着2个问题来进行下列实验 np.random.seed()是否一直有效 np.random.seed(Argument)的参数作用? 例子1 import numpy as np if __name__ == '__main__': i = 0 while (i < 6): if (i < 3): np.random.seed(0) print(np.random.randn(1,
-
在Keras中利用np.random.shuffle()打乱数据集实例
我就废话不多说了,大家还是直接看代码吧~ from numpy as np index=np.arange(2000) np.random.shuffle(index) print(index[0:20]) X_train=X_train[index,:,:,:]#X_train是训练集,y_train是训练标签 y_train=y_train[index] 补充知识:Keras中shuffle和validation_split的顺序 模型的fit函数有两个参数,shuffle用于将数据打乱,v
-
Python中的np.random.seed()随机数种子问题及解决方法
目录 1. 何为随机数种子 2. np.random.seed()参数问题 3. 使用方法 4. 随机数种子问题总结 前言: 最近在学习过程中总是遇到np.random.seed()这个问题,刚开始总是觉得不过是一个简单的随机数种子,就没太在意,后来遇到的次数多了,才发现他竟然是如此之用处之大!接下来我就把我所学到的关于np.random.seed()的知识分享给大家! 1. 何为随机数种子 随机数种子,相当于我给接下来需要生成的随机数一个初值,按照我给的这个初值,按固定顺序生成随机数.读到这,
-
Python中np.random.randint()参数详解及用法实例
目录 可实现功能: np.random.randint() 根据参数中所指定的范围生成随机 整数. 参数 一.基础用法 二.高级用法 总结 可实现功能: 1.随机生成一个整数. 2.随机生成任意范围内的一个整数. 3.随机生成指定长度的整数组 4.随机生成指定长度的任意范围的整数组 5.随机生成指定长度的多维整数组 6.随机生成指定长度的任意范围的多维整数组 np.random.randint() 根据参数中所指定的范围生成随机 整数. numpy.random.randint(low, hig
-
python中np.random.permutation函数实例详解
目录 一:函数介绍 二:实例 2.1 直接处理数组或列表数 2.2 间接处理:不改变原数据(对数组下标的处理) 2.3 实例:鸢尾花数据中对鸢尾花的随机打乱(可以直接用) 总结 一:函数介绍 np.random.permutation() 总体来说他是一个随机排列函数,就是将输入的数据进行随机排列,官方文档指出,此函数只能针对一维数据随机排列,对于多维数据只能对第一维度的数据进行随机排列. 简而言之:np.random.permutation函数的作用就是按照给定列表生成一个打乱后的随机列表 在