Python opencv相机标定实现原理及步骤详解
相机标定相机标定的目的
获取摄像机的内参和外参矩阵(同时也会得到每一幅标定图像的选择和平移矩阵),内参和外参系数可以对之后相机拍摄的图像就进行矫正,得到畸变相对很小的图像。
相机标定的输入
标定图像上所有内角点的图像坐标,标定板图像上所有内角点的空间三维坐标(一般情况下假定图像位于Z=0平面上)。
相机标定的输出
摄像机的内参、外参系数。
拍摄的物体都处于三维世界坐标系中,而相机拍摄时镜头看到的是三维相机坐标系,成像时三维相机坐标系向二维图像坐标系转换。不同的镜头成像时的转换矩阵不同,同时可能引入失真,标定的作用是近似地估算出转换矩阵和失真系数。为了估算,需要知道若干点的三维世界坐标系中的坐标和二维图像坐标系中的坐标,也就是拍摄棋盘的意义。
相机成像
相机的成像原理:小孔成像

相机的内参相机的外参
在实际由于设计工艺问题、相机安装环境或物体摆放位置等影响,会照成成像与实际图像不一样的现象。
由于设计工艺照成的影响是无法改变的事实,所以这将是相机的内参;
由环境或安装方式照成的影响是可以改变的,这就是相机的外参。
张正友标定相机原理
1.求得相机内参数:
用于标定的棋盘格是特制的,其角点坐标已知。标定棋盘格是三维场景中的一个平面∏,棋盘格在成像平面为π(知道了∏与π的对应点坐标之后,可求解两个平面1对应的单应矩阵H)。
根据相机成像模型,P为标定的棋盘坐标,p为其像素点坐标。则 ,通过对应的点坐标求解H后,可用于求K,R,T。
,通过对应的点坐标求解H后,可用于求K,R,T。
2.设棋盘格所在平面为世界坐标系上XOY平面,则棋盘格上任一角点P世界坐标系为(X,Y,0)。

3、内参约束条件



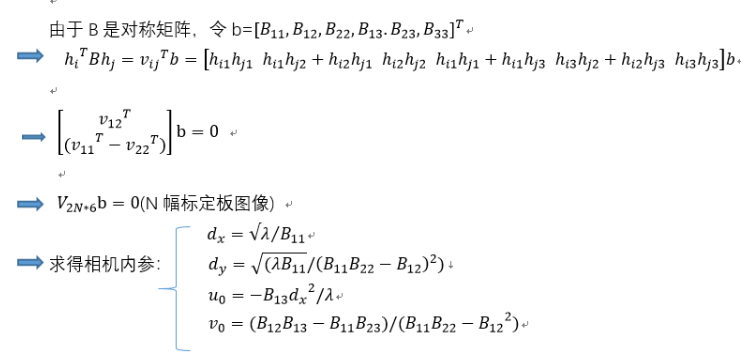
实验步骤打印棋盘图片(网上找一张)

将打印出的纸固定放到一个平面上,使用同一相机从不同的位置,不同的角度,拍摄标定板的多张照片(我拍了15张)手机型号是华为mate9

提取标定板的世界坐标
标定板的大小是标定板在水平和竖直方向上内角点的个数。内角点指的是,标定板上不挨着边界的角点。
我打印的是6x9的标定板。

标定相机



mtx -->内参数矩阵
dist --> 畸变系数
rvecs --> 旋转向量
tvecs --> 平移向量
我们可以通过反投影误差来评估结果的好坏,越接近0,说明结果越理想。
通过之前计算的内参数矩阵、畸变系数、旋转矩阵和平移向量,使用cv2.projectPoints()计算三维点到二维图像的投影,然后计算反投影得到的点与图像上检测到的点的误差,最后计算一个对于所有标定图像的平均误差即反投影误差
我的棋盘打印出来有些不平整,可能是打印的纸张没有放正,导致有些地方翘着,效果不是很好,误差值有些大了,把纸张贴平整应该会好很多。而且我可能拍照的角度变化不是太大,可以试着把拍照的角度更加差异些,结果会更明显。
import cv2
import numpy as np
import glob
# 设置寻找亚像素角点的参数,采用的停止准则是最大循环次数30和最大误差容限0.001
criteria = (cv2.TERM_CRITERIA_MAX_ITER | cv2.TERM_CRITERIA_EPS, 30, 0.001)
# 获取标定板角点的位置
objp = np.zeros((6 * 9, 3), np.float32)
objp[:, :2] = np.mgrid[0:9, 0:6].T.reshape(-1, 2) # 将世界坐标系建在标定板上,所有点的Z坐标全部为0,所以只需要赋值x和y
obj_points = [] # 存储3D点
img_points = [] # 存储2D点
images = glob.glob("E:/test_pic/qipan/*.jpg")
for fname in images:
img = cv2.imread(fname)
cv2.imshow('img',img)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
size = gray.shape[::-1]
ret, corners = cv2.findChessboardCorners(gray, (6, 9), None)
print(ret)
if ret:
obj_points.append(objp)
corners2 = cv2.cornerSubPix(gray, corners, (5, 5), (-1, -1), criteria) # 在原角点的基础上寻找亚像素角点
#print(corners2)
if [corners2]:
img_points.append(corners2)
else:
img_points.append(corners)
cv2.drawChessboardCorners(img, (8, 6), corners, ret) # 记住,OpenCV的绘制函数一般无返回值
cv2.imshow('img', img)
cv2.waitKey(2000)
print(len(img_points))
cv2.destroyAllWindows()
# 标定
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(obj_points, img_points, size, None, None)
print("ret:", ret)
print("mtx:\n", mtx) # 内参数矩阵
print("dist:\n", dist) # 畸变系数 distortion cofficients = (k_1,k_2,p_1,p_2,k_3)
print("rvecs:\n", rvecs) # 旋转向量 # 外参数
print("tvecs:\n", tvecs ) # 平移向量 # 外参数
print("-----------------------------------------------------")
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python+opencv3生成一个自定义纯色图教程
一. 图像在计算机中存储为矩阵.矩阵上一个点表示一个像素.若矩阵由一系列0-255的整数值组成,则表现为灰度图.便于理解,以下贴出代码: import cv2 import numpy as np img = np.ones((3,3),dtype=np.uint8)#random.random()方法后面不能加数据类型 #img = np.random.random((3,3)) #生成随机数都是小数无法转化颜色,无法调用cv2.cvtColor函数 img[0,0]=100 img[0,1]
-
Python+OpenCV实现图像的全景拼接
本文实例为大家分享了Python+OpenCV实现图像的全景拼接的具体代码,供大家参考,具体内容如下 环境:python3.5.2 + openCV3.4 1.算法目的 将两张相同场景的场景图片进行全景拼接. 2.算法步骤 本算法基本步骤有以下几步: 步骤1:将图形先进行桶形矫正 没有进行桶形变换的图片效果可能会像以下这样: 图片越多拼接可能就会越夸张. 本算法是将图片进行桶形矫正.目的就是来缩减透视变换(Homography)之后图片产生的变形,从而使拼接图片变得畸形. 步骤2:特征点匹配 本
-
python实现opencv+scoket网络实时图传
本文实例为大家分享了python实现opencv+scoket网络实时图传的具体代码,供大家参考,具体内容如下 服务器分析: 1. 先通过在服务器端利用OpenCV捕获到视频的每一帧图片 2. 将这些图片进行压缩成JPEG格式,这样能减小图片大小,便于传输 3. 按照提前协商好的分辨率和帧数进行打包编码传输 4. 利用服务器端打开端口8880,此时客户端连接后,便可以在客户端中捕获到服务器端的视频. #服务端 import socket import threading import struc
-

python通过opencv实现图片裁剪原理解析
这篇文章主要介绍了python通过opencv实现图片裁剪原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 图像裁剪的基本概念 : 图像裁剪是指将图像中我们想要的研究区以外的区域去除,经常是按照行政区划或研究区域的边界对图像进行裁剪.例如,一张500×400的图像,我们只想要中间的250×200的区域,就可以使用图像裁剪将四周的区域去除. 在实际开发工作中,我们经常需要对图像进行分幅裁剪,按照ERDAS实际图像分幅裁剪的过程,可以将图像分
-
python opencv 检测移动物体并截图保存实例
最近在老家找工作,无奈老家工作真心太少,也没什么面试机会,不过之前面试一家公司,提了一个有意思的需求,检测河面没有有什么船只之类的物体,我当时第一反应是用opencv做识别,不过回家想想,河面相对的东西比较少,画面比较单一,只需要检测有没有移动的物体不就简单很多嘛,如果做街道垃圾检测的话可能就很复杂了,毕竟街道上行人,车辆,动物,很多干扰物,于是就花了一个小时写了一个小的demo,只需在程序同级目录创建一个img目录就可以了 # -*-coding:utf-8 -*- __author__ =
-
python+opencv实现移动侦测(帧差法)
本文实例为大家分享了python+opencv实现移动侦测的具体代码,供大家参考,具体内容如下 1.帧差法原理 移动侦测即是根据视频每帧或者几帧之间像素的差异,对差异值设置阈值,筛选大于阈值的像素点,做掩模图即可选出视频中存在变化的桢.帧差法较为简单的视频中物体移动侦测,帧差法分为:单帧差.两桢差.和三桢差.随着帧数的增加是防止检测结果的重影. 2.算法思路 文章以截取视频为例进行单帧差法移动侦测 3.python实现代码 def threh(video,save_video,thres1,ar
-
win10下opencv-python特定版本手动安装与pip自动安装教程
1. 特定版本的python-opencv安装 在https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv 下载对应python版本和windows系统opencv的whl文件,例如我的系统是win10+64位+python3.5,于是下载的 opencv_python-3.4.2-cp35-cp35m-win_amd64.whl 下载完成后,在cmd里cd到这个whl文件目录,用pip执行安装即可: pip install opencv_python
-
python opencv圆、椭圆与任意多边形的绘制实例详解
圆形的绘制 : OpenCV中使用circle(img,center,radius,color,thickness=None,lineType=None,shift=None)函数来绘制圆形 import cv2 import numpy as np image=np.zeros((400,400,3),np.uint8) cv2.circle(image,(200,200),50,(0,0,255),2) #画圆 ''' 参数2 center:必选参数.圆心坐标 参数3 radius:必选参数
-
Python opencv相机标定实现原理及步骤详解
相机标定相机标定的目的 获取摄像机的内参和外参矩阵(同时也会得到每一幅标定图像的选择和平移矩阵),内参和外参系数可以对之后相机拍摄的图像就进行矫正,得到畸变相对很小的图像. 相机标定的输入 标定图像上所有内角点的图像坐标,标定板图像上所有内角点的空间三维坐标(一般情况下假定图像位于Z=0平面上). 相机标定的输出 摄像机的内参.外参系数. 拍摄的物体都处于三维世界坐标系中,而相机拍摄时镜头看到的是三维相机坐标系,成像时三维相机坐标系向二维图像坐标系转换.不同的镜头成像时的转换矩阵不同,同时可能引
-
Python 异步协程函数原理及实例详解
这篇文章主要介绍了Python 异步协程函数原理及实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一. asyncio 1.python3.4开始引入标准库之中,内置对异步io的支持 2.asyncio本身是一个消息循环 3.步骤: (1)创建消息循环 (2)把协程导入 (3)关闭 4.举例: import threading # 引入异步io包 import asyncio # 使用协程 @ asyncio.coroutine def
-
用Python实现简单的人脸识别功能步骤详解
前言 让我的电脑认识我,我的电脑只有认识我,才配称之为我的电脑! 今天,我们用Python实现简单的人脸识别技术! Python里,简单的人脸识别有很多种方法可以实现,依赖于python胶水语言的特性,我们通过调用包可以快速准确的达成这一目的.这里介绍的是准确性比较高的一种. 一.首先 梳理一下实现人脸识别需要进行的步骤: 流程大致如此,在此之前,要先让人脸被准确的找出来,也就是能准确区分人脸的分类器,在这里我们可以用已经训练好的分类器,网上种类较全,分类准确度也比较高,我们也可以节约在这方面花
-
python实现微信跳一跳辅助工具步骤详解
说明 1.windows上安装安卓模拟器,安卓版本5.1以上 2.模拟器里下载安装最新的微信6.6.1 3.最好使用python2.7,python3的pyhook包有bug,解决比较麻烦 步骤 1.windows上安装python2.7,配置好环境变量和pip 2.到这个网站下载对应版本的pyHook和pywin32 http://www.lfd.uci.edu/~gohlke/pythonlibs 2.打开cmd,安装下载好的whl文件和其他库 pip install pywin32-221
-
对Python+opencv将图片生成视频的实例详解
如下所示: import cv2 fps = 16 size = (width,height) videowriter = cv2.VideoWriter("a.avi",cv2.VideoWriter_fourcc('M','J','P','G'),fps,size) for i in range(1,200): img = cv2.imread('%d'.jpg % i) videowriter.write(img) 以上这篇对Python+opencv将图片生成视频的实例详解就是
-
OpenCV实现无缝克隆算法的步骤详解
目录 一.概述 二.函数原型 三.OpenCV源码 1.源码路径 2.源码代码 四.效果图像示例 一.概述 借助无缝克隆算法,您可以从一张图像中复制一个对象,然后将其粘贴到另一张图像中,从而形成一个看起来无缝且自然的构图. 二.函数原型 给定一个原始彩色图像,可以无缝混合该图像的两个不同颜色版本. void cv::colorChange (InputArray src, InputArray mask, OutputArray dst, float red_mul=1.0f, float gr
-
Python+Opencv实现物体尺寸测量的方法详解
目录 1.效果展示 2.项目介绍 3.项目搭建 4.utils.py文件代码展示与讲解 5.项目代码展示与讲解 6.项目资源 7.项目总结 1.效果展示 我们将以两种方式来展示我们这个项目的效果. 下面这是视频的实时检测,我分别用了盒子和盖子来检测,按理来说效果不应该怎么差的,但我实在没有找到合适的背景与物体.且我的摄像头使用的是外设,我不得不手持,所以存在一点点的抖动,但我可以保证,它是缺少了适合检测物体与背景. 我使用手机拍了一张照片并经过了ps修改了背景,效果不错. 2.项目介绍 本项目中
-
Python+OpenCV实现信用卡数字识别的方法详解
目录 一.模板图像处理 二.信用卡图片预处理 一.模板图像处理 (1)灰度图.二值图转化 template = cv2.imread('C:/Users/bwy/Desktop/number.png') template_gray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY) cv_show('template_gray', template_gray) # 形成二值图像,因为要做轮廓检测 ret, template_thresh = cv2.thre
-
Python设计模式之备忘录模式原理与用法详解
本文实例讲述了Python设计模式之备忘录模式原理与用法.分享给大家供大家参考,具体如下: 备忘录模式(Memento Pattern):不破坏封装性的前提下捕获一个对象的内部状态,并在该对象之外保存这个状态,这样已经后就可将该对象恢复到原先保存的状态 下面是一个备忘录模式的demo: #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'Andy' """ 大话设计模式 设计模式--备忘录模式 备忘录模式(Me
-
Python设计模式之状态模式原理与用法详解
本文实例讲述了Python设计模式之状态模式原理与用法.分享给大家供大家参考,具体如下: 状态模式(State Pattern):当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类 下面是一个状态模式的demo: #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'Andy' """ 大话设计模式 设计模式--状态模式 状态模式(State Pattern):当一个对象的内在状态改变时允许改