详解Python如何批量采集京东商品数据流程
目录
- 准备工作
- 驱动安装
- 模块使用与介绍
- 流程解析
- 完整代码
- 效果展示
准备工作
驱动安装
实现案例之前,我们要先安装一个谷歌驱动,因为我们是使用selenium 操控谷歌驱动,然后操控浏览器实现自动操作的,模拟人的行为去操作浏览器。
以谷歌浏览器为例,打开浏览器看下我们自己的版本,然后下载跟自己浏览器版本一样或者最相近的版本,下载后解压一下,把解压好的插件放到我们的python环境里面,或者和代码放到一起也可以。
模块使用与介绍
seleniumpip install selenium ,直接输入selenium的话是默认安装最新的,selenium后面加上版本号就是安装对应的的版本;csv内置模块,不需要安装,把数据保存到Excel表格用的;time内置模块,不需要安装,时间模块,主要用于延时等待;
流程解析
我们访问一个网站,要输入一个网址,所以代码也是这么写的。
首先导入模块
from selenium import webdriver
文件名或者包名不要命名为selenium,会导致无法导入。 webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器。
实例化浏览器对象 ,我这里用的是谷歌,建议大家用谷歌,方便一点。
driver = webdriver.Chrome()
我们用get访问一个网址,自动打开网址。
driver.get('https://www.jd.com/')
运行一下
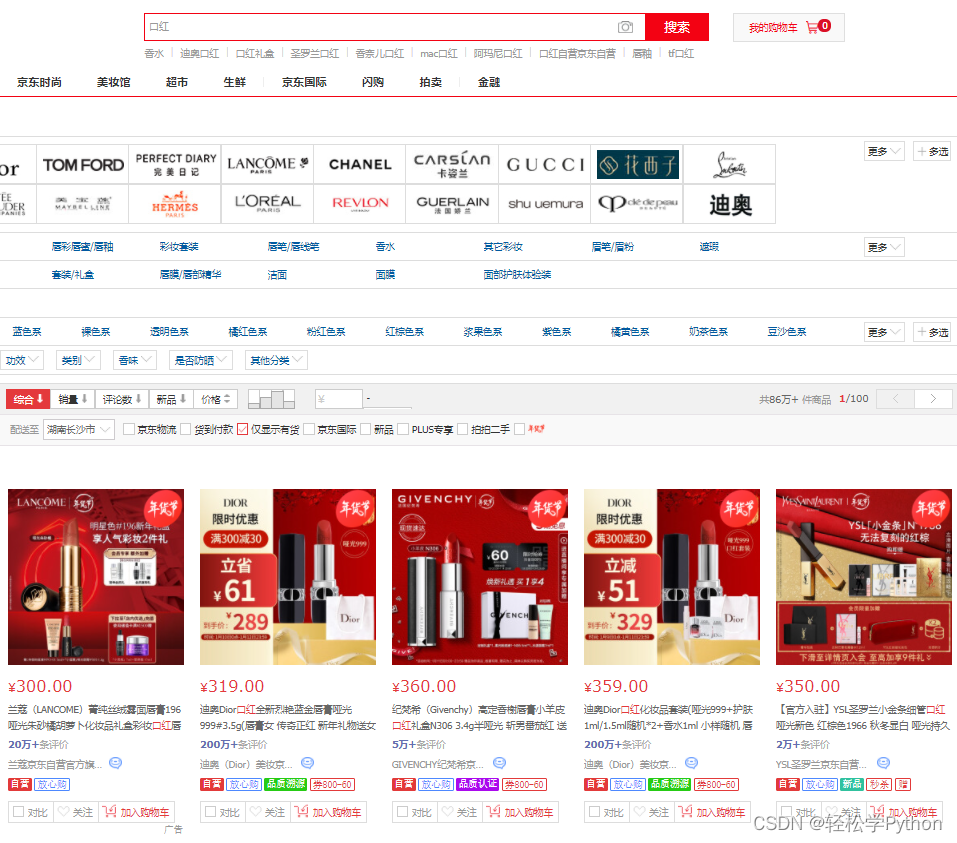
打开网址后,以买口红为例。
我们首先要通过你想购买的商品关键字来搜索得到商品信息,用搜索结果去获取信息。
那我们也要写一个输入,空白处点击右键,选择检查。
选择element 元素面板

鼠标点击左边的箭头按钮,去点击搜索框,它就会直接定位到搜索标签。
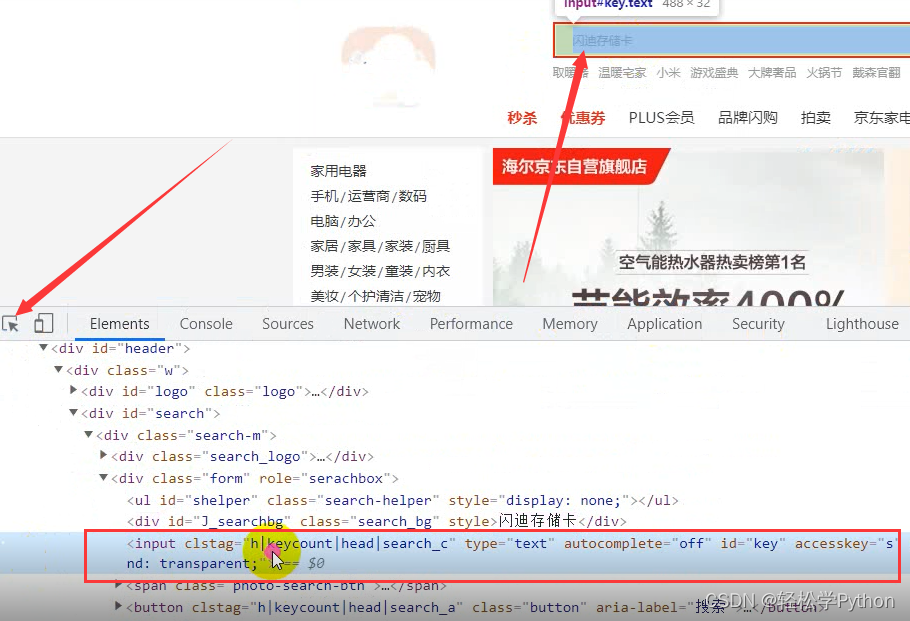
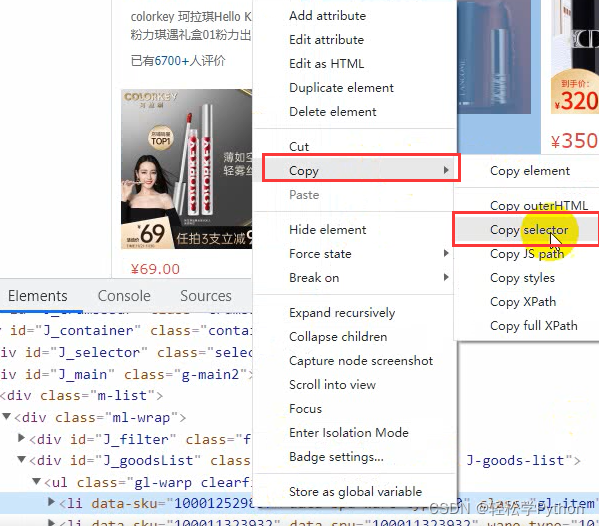
在标签上点击右键,选择copy,选择copy selector 。
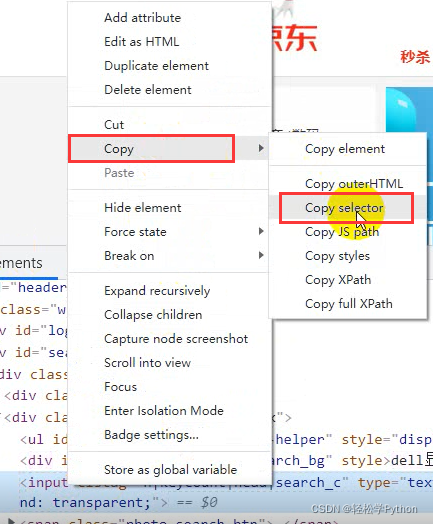
如果你是xpath ,就copy它的xpath 。
然后把我们想要搜索的内容写出来
driver.find_element_by_css_selector('#key').send_keys('口红')
再运行的时候,它就会自动打开浏览器进入目标网址搜索口红。

同样的方法,找到搜索按钮进行点击。
driver.find_element_by_css_selector('.button').click()
再运行就会自动点击搜索了
页面搜索出来了,那么咱们正常浏览网页是要下拉网页对吧,咱们让它自动下拉就好了。 先导入time模块
import time
执行页面滚动的操作
def drop_down():
"""执行页面滚动的操作""" # javascript
for x in range(1, 12, 2): # for循环下拉次数,取1 3 5 7 9 11, 在你不断的下拉过程中, 页面高度也会变的;
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js) # 执行我们JS代码
循环写好了,然后调用一下。
drop_down()

我们再给它来个延时
driver.implicitly_wait(10)
这是一个隐式等待,等待网页延时,网不好的话加载很慢。
隐式等待不是必须等十秒,在十秒内你的网络加载好后,它随时会加载,十秒后没加载出来的话才会强行加载。
还有另外一种死等的,你写的几秒就等几秒,相对没有那么人性化。
time.sleep(10)
加载完数据后我们需要去找商品数据来源
价格/标题/评价/封面/店铺等等
还是鼠标右键点击检查,在element ,点击小箭头去点击你想查看的数据。
可以看到都在li标签里面
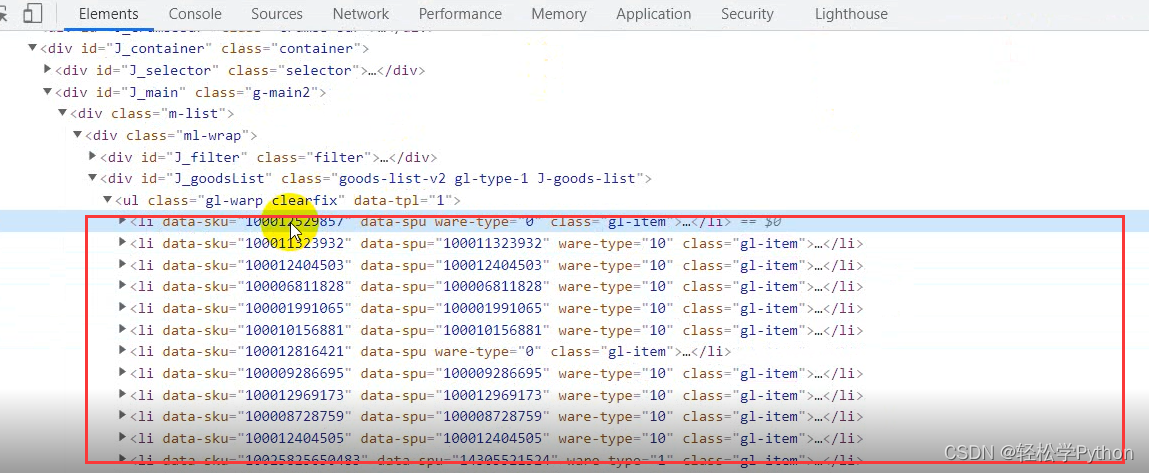
获取所有的 li 标签内容,还是一样的,直接copy 。
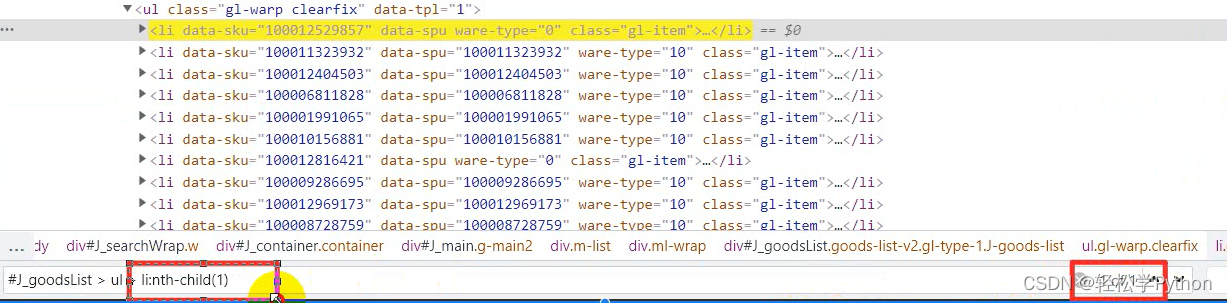
在左下角就有了

这里表示的是取的第一个,但是我们是要获取所有的标签,所以左边框框里 li 后面的可以删掉不要。
不要的话,可以看到这里是60个商品数据,一页是60个。
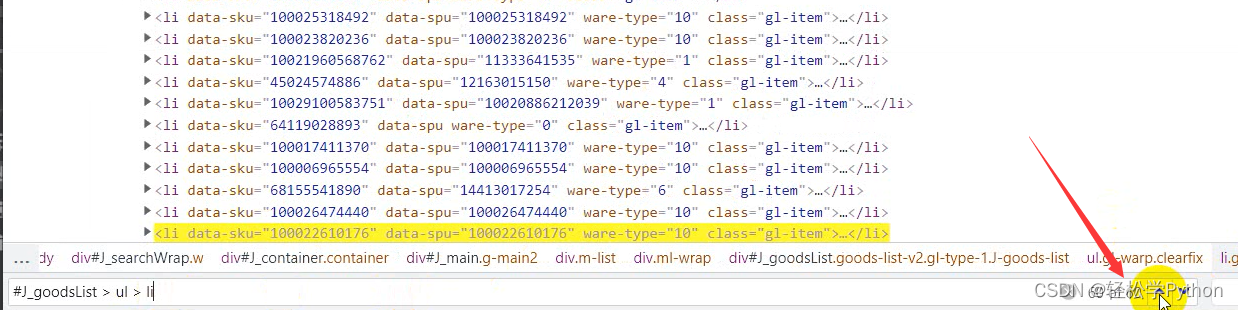
所以我们把剩下的复制过来, 用lis接收一下 。
lis = driver.find_elements_by_css_selector('#J_goodsList ul li')
因为我们是获取所有的标签数据,所以比之前多了一个s

打印一下
print(lis)
通过lis返回数据 列表 [] 列表里面的元素 <> 对象

遍历一下,把所有的元素拿出来。
for li in lis:
title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 商品标题 获取标签文本数据
price = li.find_element_by_css_selector('.p-price strong i').text # 价格
commit = li.find_element_by_css_selector('.p-commit strong a').text # 评论量
shop_name = li.find_element_by_css_selector('.J_im_icon a').text # 店铺名字
href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # 商品详情页
icons = li.find_elements_by_css_selector('.p-icons i')
icon = ','.join([i.text for i in icons]) # 列表推导式 ','.join 以逗号把列表中的元素拼接成一个字符串数据
dit = {
'商品标题': title,
'商品价格': price,
'评论量': commit,
'店铺名字': shop_name,
'标签': icon,
'商品详情页': href,
}
csv_writer.writerow(dit)
print(title, price, commit, href, icon, sep=' | ')
搜索功能
key_world = input('请输入你想要获取商品数据: ')
要获取的数据 ,获取到后保存CSV
f = open(f'京东{key_world}商品数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'商品标题',
'商品价格',
'评论量',
'店铺名字',
'标签',
'商品详情页',
])
csv_writer.writeheader()
然后再写一个自动翻页
for page in range(1, 11):
print(f'正在爬取第{page}页的数据内容')
time.sleep(1)
drop_down()
get_shop_info() # 下载数据
driver.find_element_by_css_selector('.pn-next').click() # 点击下一页
完整代码
from selenium import webdriver
import time
import csv
def drop_down():
"""执行页面滚动的操作"""
for x in range(1, 12, 2):
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js) # 执行JS代码
key_world = input('请输入你想要获取商品数据: ')
f = open(f'京东{key_world}商品数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'商品标题',
'商品价格',
'评论量',
'店铺名字',
'标签',
'商品详情页',
])
csv_writer.writeheader()
# 实例化一个浏览器对象
driver = webdriver.Chrome()
driver.get('https://www.jd.com/') # 访问一个网址 打开浏览器 打开网址
# 通过css语法在element(元素面板)里面查找 #key 某个标签数据 输入一个关键词 口红
driver.find_element_by_css_selector('#key').send_keys(key_world) # 找到输入框标签
driver.find_element_by_css_selector('.button').click() # 找到搜索按钮 进行点击
# time.sleep(10) # 等待
# driver.implicitly_wait(10) # 隐式等待
def get_shop_info():
# 第一步 获取所有的li标签内容
driver.implicitly_wait(10)
lis = driver.find_elements_by_css_selector('#J_goodsList ul li') # 获取多个标签
# 返回数据 列表 [] 列表里面的元素 <> 对象
# print(len(lis))
for li in lis:
title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # 商品标题 获取标签文本数据
price = li.find_element_by_css_selector('.p-price strong i').text # 价格
commit = li.find_element_by_css_selector('.p-commit strong a').text # 评论量
shop_name = li.find_element_by_css_selector('.J_im_icon a').text # 店铺名字
href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # 商品详情页
icons = li.find_elements_by_css_selector('.p-icons i')
icon = ','.join([i.text for i in icons]) # 列表推导式 ','.join 以逗号把列表中的元素拼接成一个字符串数据
dit = {
'商品标题': title,
'商品价格': price,
'评论量': commit,
'店铺名字': shop_name,
'标签': icon,
'商品详情页': href,
}
csv_writer.writerow(dit)
print(title, price, commit, href, icon, sep=' | ')
# print(href)
for page in range(1, 11):
print(f'正在爬取第{page}页的数据内容')
time.sleep(1)
drop_down()
get_shop_info() # 下载数据
driver.find_element_by_css_selector('.pn-next').click() # 点击下一页
driver.quit() # 关闭浏览器
效果展示


代码是没得问题的,大家可以去试试
到此这篇关于详解Python如何批量采集京东商品数据流程的文章就介绍到这了,更多相关Python 采集京东商品数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python制作爬虫采集小说
开发工具:python3.4 操作系统:win8 主要功能:去指定小说网页爬小说目录,按章节保存到本地,并将爬过的网页保存到本地配置文件. 被爬网站:http://www.cishuge.com/ 小说名称:灵棺夜行 代码出处:本人亲自码的 import urllib.request import http.cookiejar import socket import time import re timeout = 20 socket.setdefaulttimeout(timeout) sl
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
1.在Scrapy工程下新建"middlewares.py" # Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication import base64 # Start your middleware class class ProxyMiddleware(object): # overwrite process
-

Python爬虫实战演练之采集糗事百科段子数据
目录 知识点 爬虫基本步骤: 爬虫代码 导入所需模块 获取网页地址 发送请求 数据解析 保存数据 运行代码,得到数据 知识点 1.爬虫基本步骤 2.requests模块 3.parsel模块 4.xpath数据解析方法 5.分页功能 爬虫基本步骤: 1.获取网页地址 (糗事百科的段子的地址) 2.发送请求 3.数据解析 4.保存 本地 爬虫代码 导入所需模块 import re import requests import parsel 获取网页地址 url = 'https://www.qiu
-
Python爬虫实现热门电影信息采集
目录 一.前言 二.前期准备 1.使用的软件 2.需要用的模块 3.模块安装问题 4.如何配置pycharm里面的python解释器? 5.pycharm如何安装插件? 三.思路 1.明确需求 2.发送请求 3.获取数据 4.解析数据 5.保存数据 四.代码部分 一.前言 好不容易女神喊我去看电影,但是她又不知道看啥,那么我当然得准备准备~ 二.前期准备 1.使用的软件 python 3.8 开源 免费的 (统一 3.8) Pycharm YYDS python最好用的编辑器 不接受反驳- 2
-
Python爬虫实战演练之采集拉钩网招聘信息数据
目录 本文要点: 环境介绍 本次目标 爬虫块使用 内置模块: 第三方模块: 代码实现步骤: (爬虫代码基本步骤) 开始代码 导入模块 发送请求 解析数据 加翻页 保存数据 运行代码,得到数据 本文要点: 爬虫的基本流程 requests模块的使用 保存csv 可视化分析展示 环境介绍 python 3.8 pycharm 2021专业版 激活码 Jupyter Notebook pycharm 是编辑器 >> 用来写代码的 (更方便写代码, 写代码更加舒适) python 是解释器 >&
-
基于Python爬虫采集天气网实时信息
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10-20厘米.此外,贵州中东部.湖南中北部.湖北东南部.江西西北部有冻雨.言归正传,天气无时无刻都在陪伴着我们,今天小编带大家利用Python网络爬虫来实现天气情况的实时采集. 此次的目标网站是绿色呼吸网.绿色呼吸网站免费提供中国环境监测总站发布的PM2.5实时数据查询,更收集分析关于PM2.5有关的一切报
-
Python爬虫采集微博视频数据
目录 前言 知识点 开发环境 爬虫原理 案例实现 前言 随时随地发现新鲜事!微博带你欣赏世界上每一个精彩瞬间,了解每一个幕后故事.分享你想表达的,让全世界都能听到你的心声!今天我们通过python去采集微博当中好看的视频! 没错,今天的目标是微博数据采集,爬的是那些好看的小姐姐视频 知识点 requests pprint 开发环境 版 本:python 3.8 -编辑器:pycharm 2021.2 爬虫原理 作用:批量获取互联网数据(文本, 图片, 音频, 视频) 本质:一次次的请求与响应
-
Python爬虫入门案例之回车桌面壁纸网美女图片采集
目录 知识点 环境 目标网址: 爬虫代码 导入模块 发送网络请求 获取网页源代码 提取每个相册的详情页链接地址 替换所有的图片链接 换成大图 保存图片 图片名字 翻页 爬取结果 知识点 requests parsel re os 环境 python3.8 pycharm2021 目标网址: https://mm.enterdesk.com/bizhi/63899-347866.html [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 注意:
-
Python爬虫_城市公交、地铁站点和线路数据采集实例
城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息,包含公交.地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集.闲言少叙,接下来将详细介绍如何使用Python爬虫爬取城市公交.地铁站点和数据. 首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线.可以通过图吧公交.公交网.8684.本地宝等网站获取,该类网站提供了按数字和字母划分类别的公交线路名称.Pyth
-
详解Python如何批量采集京东商品数据流程
目录 准备工作 驱动安装 模块使用与介绍 流程解析 完整代码 效果展示 准备工作 驱动安装 实现案例之前,我们要先安装一个谷歌驱动,因为我们是使用selenium 操控谷歌驱动,然后操控浏览器实现自动操作的,模拟人的行为去操作浏览器. 以谷歌浏览器为例,打开浏览器看下我们自己的版本,然后下载跟自己浏览器版本一样或者最相近的版本,下载后解压一下,把解压好的插件放到我们的python环境里面,或者和代码放到一起也可以. 模块使用与介绍 selenium pip install selenium ,直
-
详解Python如何批量检查图像是否可用
数据集中的图像,一般不可用在以下3个方面: 1.图像过小 2.无法打开 3.“Premature end of JPEG file” 这些图像可能会导致模型的学习异常,因此,使用多进程检查数据集中的每张图像,是很有必要的. 具体逻辑如下: 遍历文件夹,多进程处理每一张图像 判断图像是否可读,是否支持resize尺寸,边长是否满足 判断JPG图像是否Premature end 删除错误图像 脚本如下: #!/usr/bin/env python # -- coding: utf-8 -- "&qu
-
详解Python中四种关系图数据可视化的效果对比
python关系图的可视化主要就是用来分析一堆数据中,每一条数据的节点之间的连接关系从而更好的分析出人物或其他场景中存在的关联关系. 这里使用的是networkx的python非标准库来测试效果展示,通过模拟出一组DataFrame数据实现四种关系图可视化. 其余还包含了pandas的数据分析模块以及matplotlib的画图模块. 若是没有安装这三个相关的非标准库使用pip的方式安装一下即可. pip install pandas -i https://pypi.tuna.tsinghua.e
-
Python实现批量采集商品数据的示例详解
目录 本次目的 知识点 开发环境 代码 本次目的 python批量采集某商品数据 知识点 requests 发送请求 re 解析网页数据 json 类型数据提取 csv 表格数据保存 开发环境 python 3.8 pycharm requests 代码 导入模块 import json import random import time import csv import requests import re import pymysql 核心代码 # 连接数据库 def save_sql(t
-
详解Python如何实现批量为PDF添加水印
目录 准备环境 获得经销商名字对应的列表 生成水印PDF 合并水印与目标PDF 总结 我们有时候需要把一些机密文件发给多个客户,为了避免客户泄露文件,会在机密文件中添加水印.每个客户收到的文件内容相同,但是水印都不相同.这样一来,如果资料泄露了,通过水印就知道是从谁手上泄露的. 今天,一个做市场的朋友找我咨询PDF加水印的问题,如下图所示: 他有一个Excel文件,文件里面有10000个经销商的名字,他要把价目表PDF发给这些经销商,每个经销商收到的PDF文件上面的水印都是这个经销商自己的名字.
-
详解Python+opencv裁剪/截取图片的几种方式
前言 在计算机视觉任务中,如图像分类,图像数据集必不可少.自己采集的图片往往存在很多噪声或无用信息会影响模型训练.因此,需要对图片进行裁剪处理,以防止图片边缘无用信息对模型造成影响.本文介绍几种图片裁剪的方式,供大家参考. 一.手动单张裁剪/截取 selectROI:选择感兴趣区域,边界框框选x,y,w,h selectROI(windowName, img, showCrosshair=None, fromCenter=None): . 参数windowName:选择的区域被显示在的窗口的名字
-
详解Python设计模式之策略模式
虽然设计模式与语言无关,但这并不意味着每一个模式都能在每一门语言中使用.<设计模式:可复用面向对象软件的基础>一书中有 23 个模式,其中有 16 个在动态语言中"不见了,或者简化了". 1.策略模式概述 策略模式:定义一系列算法,把它们一一封装起来,并且使它们之间可以相互替换.此模式让算法的变化不会影响到使用算法的客户. 电商领域有个使用"策略"模式的经典案例,即根据客户的属性或订单中的商品计算折扣. 假如一个网店制定了下述折扣规则. 有 1000 或
-
详解Python 关联规则分析
1. 关联规则 大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布:据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起:结果这两个品类的销量都有明显的增长:分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品. 不论这个案例是否是真实的,案例中分析顾客购买记录的方式就是关联规则分析法Association Rules. 关联规则分析也被称为购物篮分析,用于分析数据集各项之间的关联关系. 1
-
详解Python自动化之文件自动化处理
一.生成随机的测验试卷文件 假如你是一位地理老师, 班上有 35 名学生, 你希望进行美国各州首府的一个小测验.不妙的是,班里有几个坏蛋, 你无法确信学生不会作弊.你希望随机调整问题的次序, 这样每份试卷都是独一无二的, 这让任何人都不能从其他人那里抄袭答案.当然,手工完成这件事又费时又无聊. 下面是程序所做的事: • 创建 35 份不同的测验试卷. • 为每份试卷创建 50 个多重选择题,次序随机. • 为每个问题提供一个正确答案和 3 个随机的错误答案,次序随机. • 将测验试卷写到 35
-
详解Python如何利用Pandas与NumPy进行数据清洗
目录 准备工作 DataFrame 列的删除 DataFrame 索引更改 DataFrame 数据字段整理 str 方法与 NumPy 结合清理列 apply 函数清理整个数据集 DataFrame 跳过行 DataFrame 重命名列 许多数据科学家认为获取和清理数据的初始步骤占工作的 80%,花费大量时间来清理数据集并将它们归结为可以使用的形式. 因此如果你是刚刚踏入这个领域或计划踏入这个领域,重要的是能够处理杂乱的数据,无论数据是否包含缺失值.不一致的格式.格式错误的记录还是无意义的异常